Inspiration
As LLMs are increasingly deployed in real applications, reliability becomes just as critical as model quality. Most demos treat LLMs as black boxes, with little visibility into latency, failures, or long-term health. This project was inspired by the need to apply real SRE practices to LLM systems.
What it does
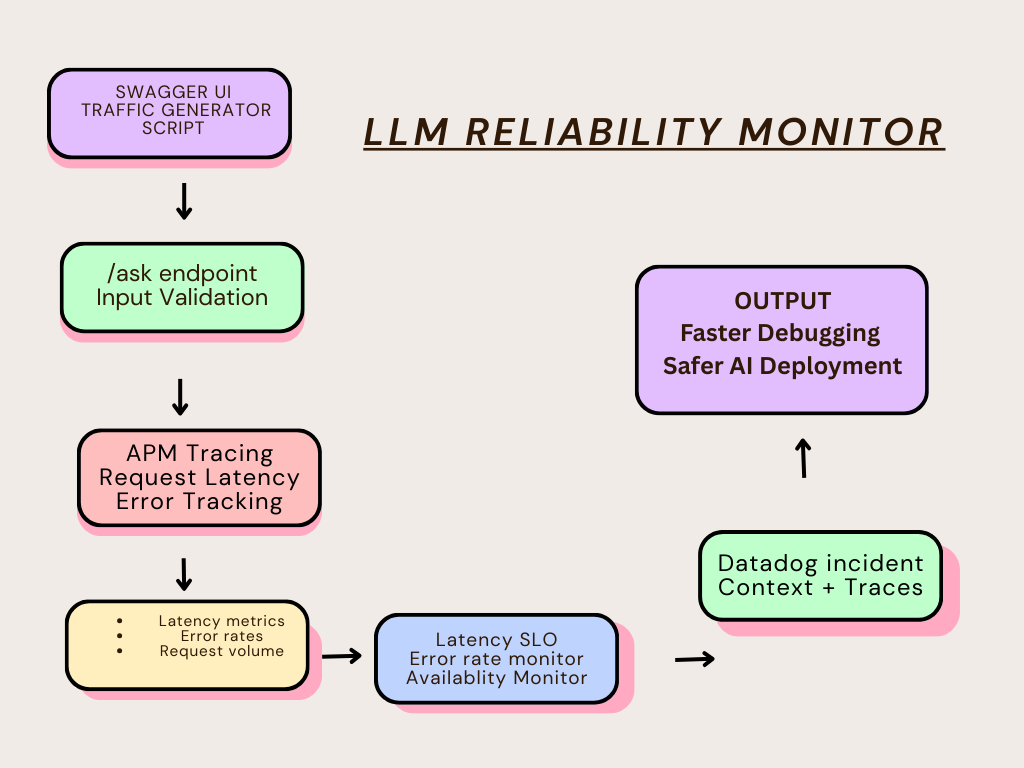
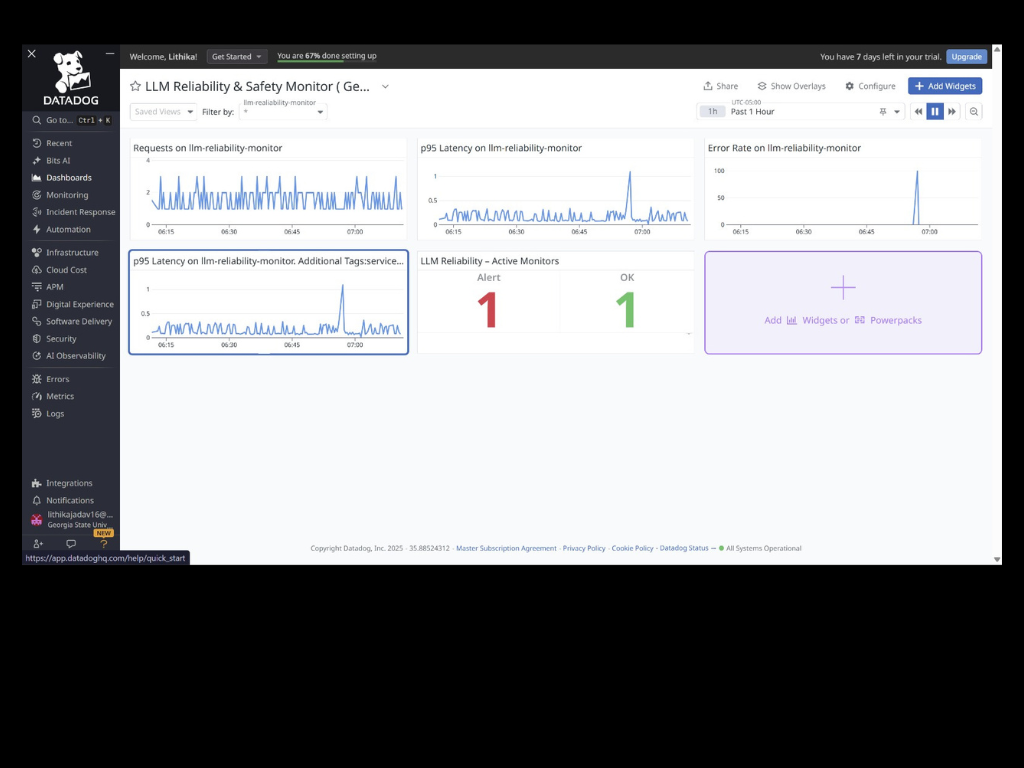
This project implements an end-to-end observability strategy for a Gemini-backed LLM application using Datadog. It monitors request latency, availability, and error budget burn, and automatically creates actionable incidents when reliability degrades.
How I built it
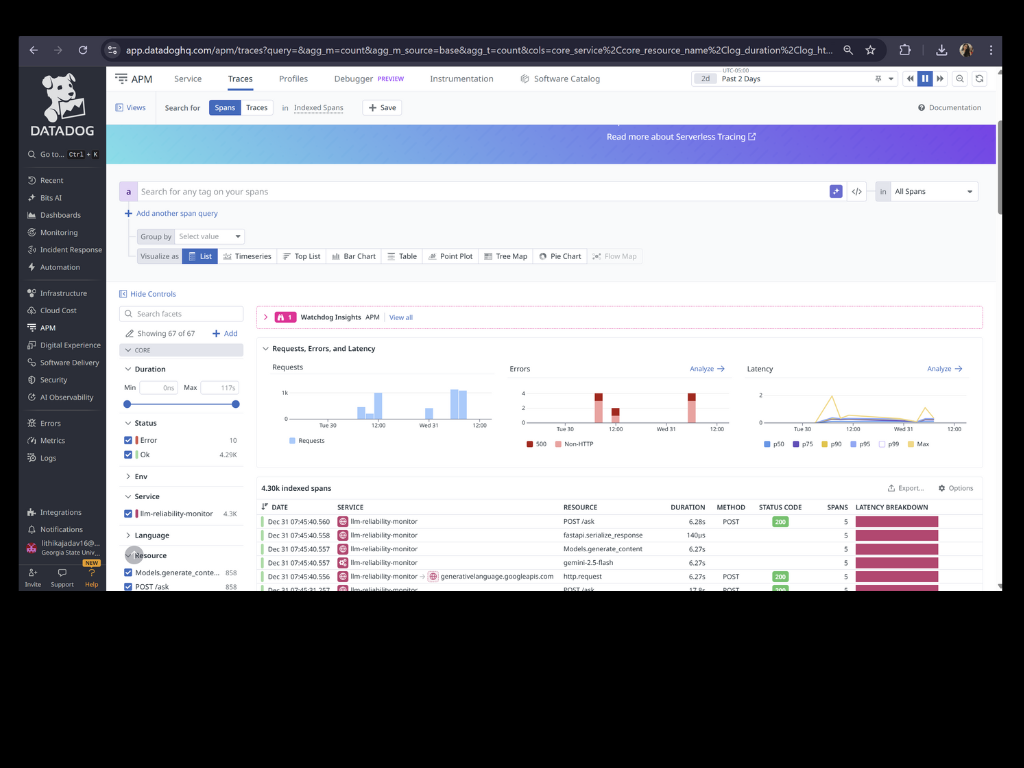
The application is a FastAPI service that sends prompts to Gemini. It is instrumented using Datadog APM via auto-instrumentation, which emits traces, latency metrics, and error signals for every request.
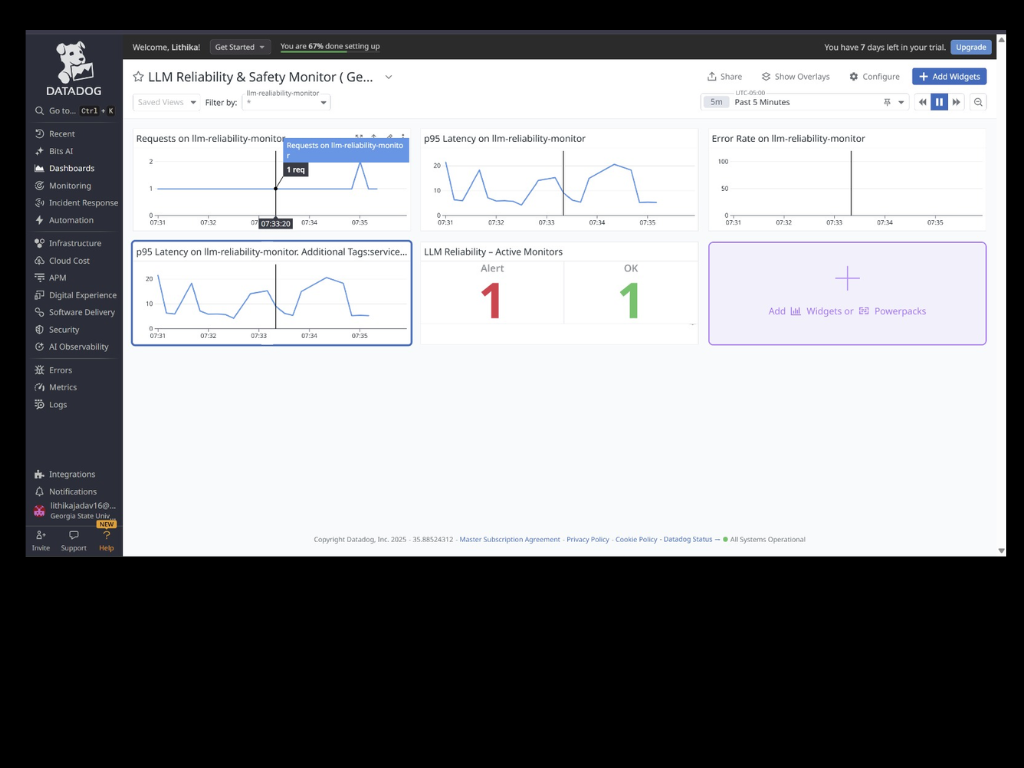
A custom traffic generator simulates real usage by sending varied prompts to the API. Using the collected telemetry, I configured Datadog monitors, Service Level Objectives (SLOs), and dashboards to surface application health and reliability trends.
What I learned
I learned how SLOs and error budgets provide a more meaningful view of reliability than isolated alerts, especially for LLM systems where latency variability is common. I also gained hands-on experience designing observability signals that are actionable, not noisy.
Challenges
One challenge was identifying the right signals to measure for an LLM service, particularly when some latency metrics are exposed differently through APM traces. Another challenge was tuning thresholds to intentionally trigger incidents without overwhelming the system, while still producing realistic reliability signals.


Log in or sign up for Devpost to join the conversation.