


Inspiration
In an era of ever-increasing media consumption, individuals often fall into reinforcement bias—engaging only with content that aligns with their existing beliefs. Our project was born from the need to break this cycle and promote diverse perspectives in online media. By providing users with real-time insights into their content consumption habits, we empower them to make informed choices about what they engage with and how it shapes their worldview.
What it does
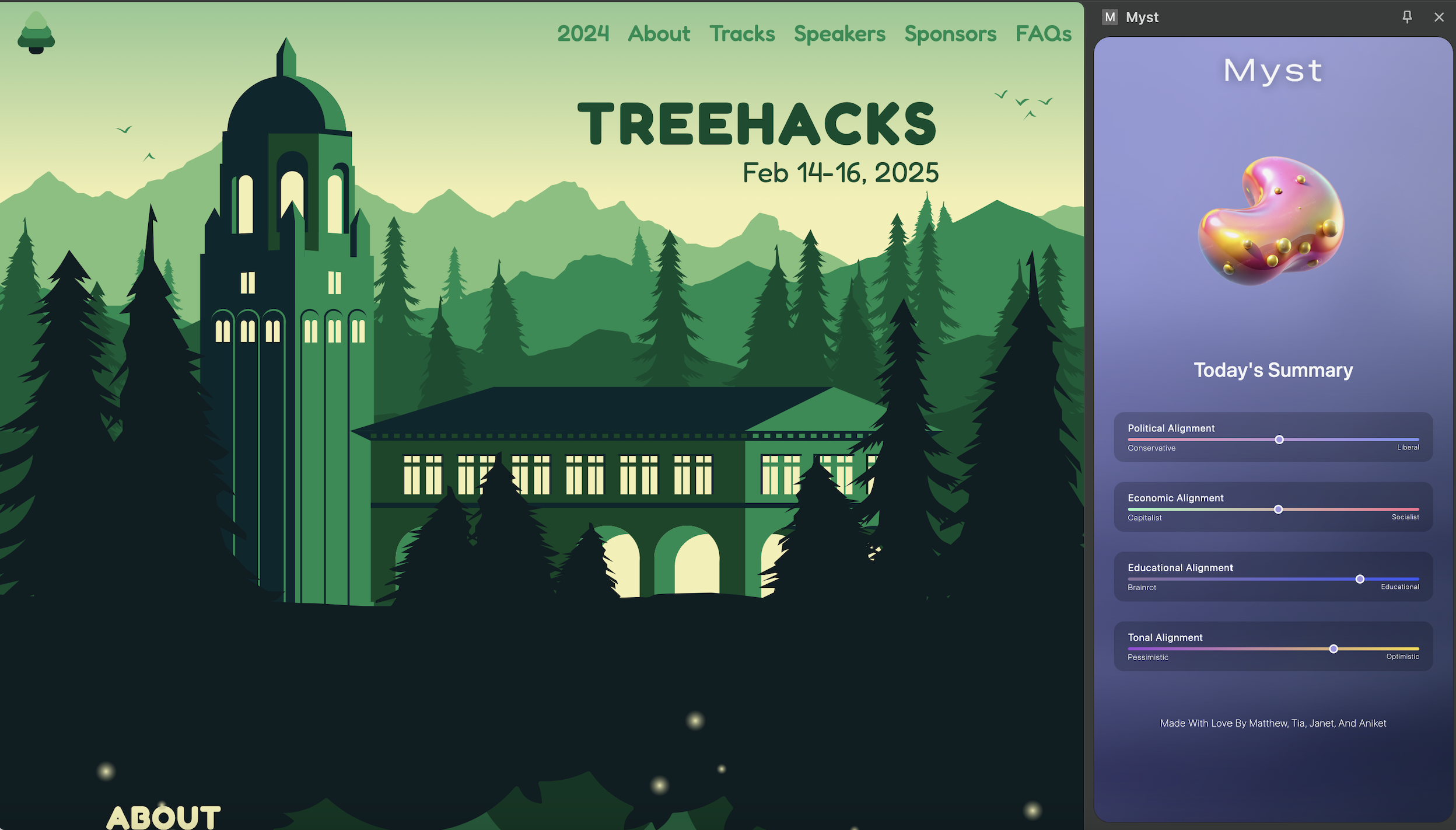
We created a Chrome Extension that automatically captures screenshots of online activity upon tab changes and significant keystrokes and analyzes the content in real time, all while minimizing storage usage by updating a rolling classification vector instead of storing every screenshot. Using Vision-Language Models (VLMs), content classification, and sentiment analysis, we generate a numerical consumption vector that categorizes a user's browsing habits on progressive scales for various categories: motivational (generally optimistic vs. pessimistic content), educational (informative vs. brain rot content), political (conservative vs. liberal content), and economic (capitalist vs. social content), and whether or not the content is misinformation. Users are then given an easy to read summary of where their content consumption leans.
By continuously updating rather than storing every screenshot, our system provides real-time insights without unnecessary data overhead. These insights are displayed dynamically, allowing users to track shifts in their media consumption and even receive recommendations for broadening their exposure.
How we built it
We started by assembling a basic Chrome extension, learning the required structure for opening and deploying an extension on the Chrome Web Store. Next, we developed the core functionality and pipeline: capturing screenshots of the user's screen, extracting text using the OpenAI GPT-4o API, and classifying the content using Mistral AI. Finally, we performed sentiment analysis with our fine-tuned model on TogetherAI to generate meaningful insights about user consumption habits.
The last stage was connecting these two components through the use of a Flask endpoint, enabling seamless communication between the extension and the backend. To make the insights more interactive, we used Luma Labs to visualize the classification data dynamically. Instead of simply displaying raw numerical values, we transformed the running classification vector into a blob-based 3D visualization, where the shape, size, and color of the blob evolve based on the user’s browsing trends. This provides an intuitive and engaging way for users to see how their content consumption habits shift over time.
Challenges we ran into
We got stuck a few times when hosting the Flask backend. A lot of time was spent trying to debug the json outputs for the Mistral API realizing that formatting was creating a large amount of errors. After fixing this, debugging was difficult since understanding niche errors in database management and quicks of Flask took time to individually discover and address.
We also have a hard time synchronizing data across the users as we added capabilities to maintain a user’s data across different devices. This meant sharing the json file on a backend hosted database.
Accomplishments that we're proud of
We are very proud that we were able to deliver an end-to-end extension that we had no idea how to do prior to the Hackathon start. Hosting on Flask was something we had never done, so getting an extension that fully integrates with user behavior and provide useful insights was incredibly rewarding. This extension is truly something that I would want to use in my everyday internet usage, for which, I am excited to continue building and fine-tuning to my usage patterns.
The UI for this extension is gorgeous and came together with the metrics swimmingly. We are always excited to see what our unique "Blob" will look like!
What we learned
Throughout this journey, we learned:
- How to fully build an end-to-end Chrome Extension—from background scripts to local storage synchronization.
- Leveraging Vision-Language Models (VLMs) for content classification and sentiment analysis.
- Integrating a Flask backend with a real-time classification model.
- Applying generative AI for visualizing user behavior in 3D using Luma Labs.
What's next for Myst
If we were to continue developing Myst, we envision several key improvements and expansions to enhance its impact:
- Refining Classification Models: While our current approach effectively categorizes content, we aim to further fine-tune our model for better accuracy. This includes improving sentiment analysis, refining misinformation detection, and incorporating a broader range of training data to reduce biases.
- Displaying Global User Trends: To help users contextualize their browsing habits, we plan to introduce an aggregated, anonymized view of global consumption trends. Users will be able to compare their own consumption patterns against the average person's trends, seeing where they align or diverge in different categories and encouraging greater awareness of information bubbles.
- Personalized Recommendations: Beyond simply analyzing content, we want to guide users toward a more balanced information diet. Myst will offer recommendations based on gaps in their consumption, encouraging exposure to diverse perspectives while respecting user preferences.
Built With
- css
- flask
- html
- javascript
- lumalabs
- mistral-ai
- openai
- python


Log in or sign up for Devpost to join the conversation.