






Memes are becoming premier sources of information, especially for Generation Z. A meme is a form of comedic expression through digital content, typically seen as a picture, gif, or video, accompanied by text. People find enjoyment both when looking at funny memes themselves and sharing these memes with their friends (and thus hopefully making their friends laugh). These memes are transmitted through channels such as Facebook Messenger, Instagram, email, social media, text, meme apps, etc. Users often spend hours “meme hunting” - finding memes that satiate senses of humor. However, since a meme is essentially just a picture with some text on it, it is difficult to classify with traditional methods. This has led to a natural fragmentation in the channels that users utilize to receive this content. Enter MyMeMe.
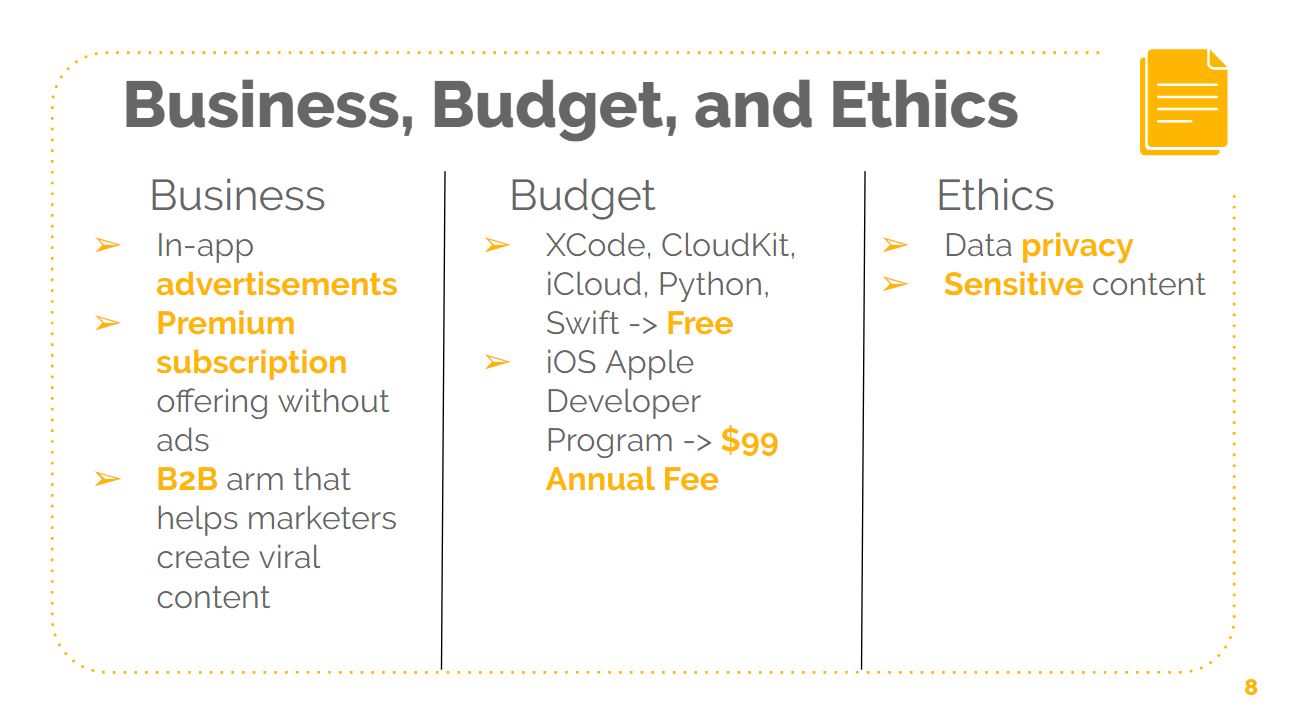
MyMeMe targets young people who regularly use smartphones and social media. Through the use of machine learning based around identifying distinct “senses of humor”, MyMeMe will learn about users over time and provide more and more tailored content, removing the extra, unnecessary channels users currently have to scour to find content that appeals to their taste. This not only saves the user time, but also increases utility gained per unit time the user spends on our app, as he / she is receiving more personalized content and what is not relevant to them is filtered out. Users will be shown ads to generate revenue, and they will also have the option to pay for a premium subscription service to remove theses ads.
MyMeMe will also feature a B2B arm in addition to its consumer-facing app. This targets the mobile advertising market. We look to monetize the data collected on users and the subsequent network effects, such as users sharing memes in groups. Social media marketing budgets are ballooning for B2C companies but few are capitalizing on virality. Traditionally, advertising is centered around number of engagements or views. If something goes viral, like a Wendy’s tweet, the value realized from it has asymmetric upside. The probability of this happening is relatively low, given the amount of content on the internet, but its risk-reward profile justifies that savvy businesses at least invest a small percent of their social media marketing budget in this, similar to speculative investments without the downside risk. Historically, virality has been extremely tough to predict, leading to few companies successfully harnessing it, but the data MyMeMe collects on users, humor profiles, and network effects will allow much better prediction. MyMeMe will capitalize on this data to help businesses create viral content, which it will subsequently promote on the app. This value proposition for businesses can be thought of in terms of Blue Ocean Strategy. With this current plan, MyMeMe becomes the leader in a currently uncontested market, virality advertising, that creates new value for advertisers while decreasing costs to obtain the same level of views and thus can garner asymmetric reach upside for fixed marketing investments.
The business-facing arm of MyMeMe solves the current inability of marketers to capitalize on the virality of social networks. Advertising is currently structured such that companies pay for a certain “expected” reach. MyMeMe will allow for viral marketing to be accessible through insights on the data that is collected. We define viral advertising as advertising based on developing content which companies leave to network effects, or virality, to self-propagate to users across the internet. While the expected distribution of reach has high variance, it is extremely right-tailed. This justifies businesses at least investing a small percentage of their social media advertising portfolio in viral marketing. This can be compared to high-risk-high-return stocks.
A simple profit-and-loss model has been created, forecasting revenues and expenses over the next 5 years to calculate potential operating profit. For now, we are just assuming that we can capture a certain percentage of the mobile application and social media advertising markets, but we hope to break this down more granularly and precisely based on our two market segments, especially with regards to the first segment (revenue coming from individuals age 25-and-under who regularly use their smartphones and social media). Preliminary segment sizes and growth rates have been obtained from Statista. The cost structure allows us to maintain high operating leverage. Variable costs primarily come from storing user and meme data in the cloud servers, and this will be eventually accomplished with Amazon Web Services. Fixed costs will exist in the form of sales, general, and administrative expenses (which we will define as all overhead not related to software development, including rent and executive salaries), as well as research and development expenses (which we will define as software developer salaries and related expenses). Generally, as the business grows, it will achieve more economies of scale and organically expand margins, especially as storage costs become smaller per incremental data usage.
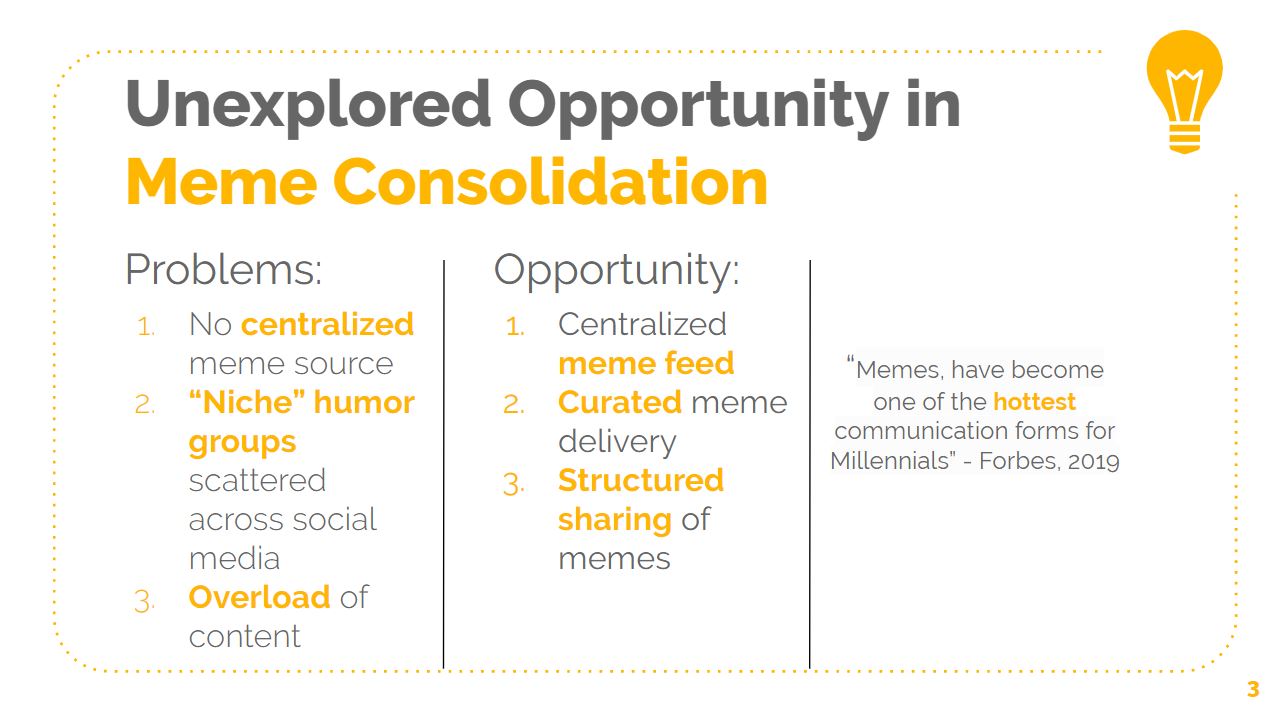
MyMeMe solves four main problems with meme consumption: classification of memes, the presence of multiple suboptimal platforms, overload of content, and short attention span of users. Since a meme is essentially just a picture with some text on it, it is difficult to classify. Thus, it often takes a person much “meme hunting” before finding one that satiates his/her sense of humor, and these “senses of humor” are extremely difficult to classify in simple terms. This presents a problem of inefficient searching for enjoyable memes and content. Users find information on multiple platforms, including Facebook, Twitter, Instagram, and Snapchat, all of which use feed systems that are overloaded with content posted and shared by other accounts. People spend millions of hours per day swiping, scrolling, liking, and commenting on memes every day. However, people generally have short attention spans when browsing content and are prone to get bored, distracted, and / or frustrated while searching for memes. With advanced technology and Internet browsing available at their fingertips, people may just give up searching for memes and engage in another activity if they are unable to find ones that appeal to their unique senses of humor.
MyMeMe increases user entertainment from meme consumption while simultaneously decreasing time spent searching for memes, overall providing more concentrated enjoyment. We believe a web service or smartphone application with a “dislike” / “like” swiping mechanism, providing better-curated memes to individuals over time as they provide feedback, is the most feasible solution to improve meme consumption. Users have previously shown interest in this swiping activity, as shown by the popularity of applications like Tinder, Bumble, and Hinge, and memes are more prevalent in society than ever before. Exposing individuals to memes they like on a consistent basis is a value-additive process.
It is important to note that there are no applications currently on the market that offer self-improving meme distribution, as most people have resorted to more-tailored Facebook groups and forums like Reddit. The value-add of the consumer-facing side of MyMeMe is primarily gained from individuals who may like many types of memes or more specific genres of memes, and an algorithm has been designed to hit these many “senses of humor” well and deliver content that is appealing to the specific users
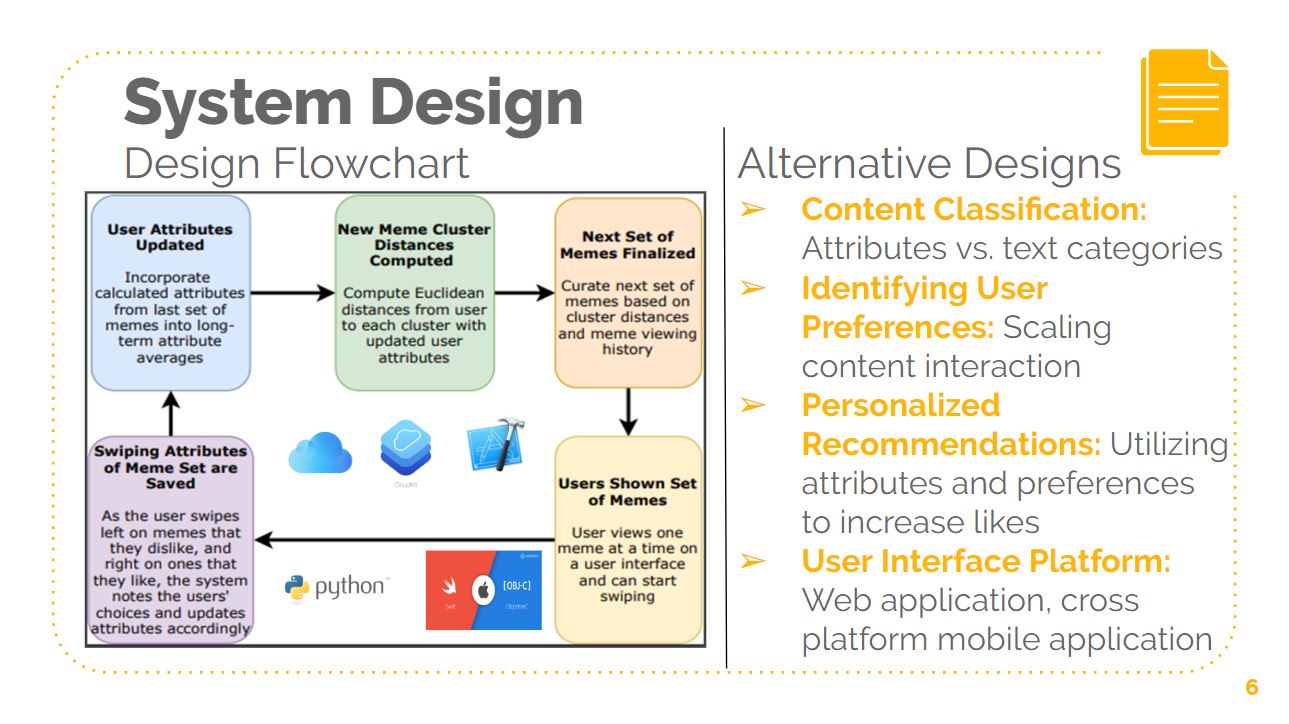
At the heart of the system are meme-attributes that we predict to be good differentiators of these clusters, and we characterize these attributes as “senses of humor”. Each meme can be defined by different levels of these attributes; specific attributes used to identify memes include political correctness, corniness, recency, and intended age, among others. These defined memes are shown to users in sets of 50 or so on a user interface, and they are able to either “dislike” (defined as a “left swipe”) or “like” (defined as a “right swipe”) the meme. When users make decisions, their preferred attributes are updated based on their reactions (“like” or “dislike” to the memes and their attributes. A user’s preferences / own attributes are used to find the distance between him/her and various clusters. The clusters closest to the users will have a proportionally higher share of memes shown to the user in the next set of memes that are available to the user. The first set of memes a user sees is defined as the “training” set of memes, and they are randomly selected from the database and used to define the initial user attributes to suggest better-curated memes in the future. Over time, as user attributes converge, the users’ decisions will be used to assign attributes to the newly entering memes in the meme ecosystem, creating a self-ranking system so that external rating is not necessary.
For the scope of the senior design project, we are creating the user-facing application aspect of MyMeMe. The project will consist of a meme database with ranked attributes, the clustering algorithm, the meme suggestion algorithm, the meme rating algorithm, and the user interface iOS application. Currently, we have defined our set of attributes (10+, including both binary and non-binary levels) and ranked a subset of 500 memes. Additionally, we have programmed one algorithm to cluster the memes based on these attributes and another algorithm to suggest a set of memes based on these clusters and the user’s attributes. To test the reliability of our defined attributes and the effectiveness of the recommender algorithm, we are developing an iOS app. This beta app is a basic user interface for users to easily view and rate memes and see their unique attributes. Using Swift in XCode we are going straight to iOS for easy accessibility to testers. We are implementing our in Apple iCloud with Cloudkit. This database will hold all user and meme data as well as keep rating records for metrics that will allow us to determine how well we are capturing users’ preferred content.
The progress of the most important component, the suggestion algorithm, can be measured quantitatively by comparing the “like swipe ratio” obtained from a set of random, uncorrelated memes, say 50, to that obtained from a different set of 50 memes that have been generated by the algorithm and suggested to the user. Hopefully, the user will “like swipe” these suggested memes at higher frequencies than memes that were randomly generated; from this user data, the ratio should improve over time as user preferences are further specified. Even as the suggested set of memes are being liked / disliked, the algorithm will continue to update and provide even better curated memes.


Log in or sign up for Devpost to join the conversation.