
Inspiration
Recent development in text-to-image models (Dalle-2, Imagen, Stable Diffusion) have been very exciting. We wanted to take it a step further and build an app to drastically simplify the process of getting this technology in the hands of users.
What it does
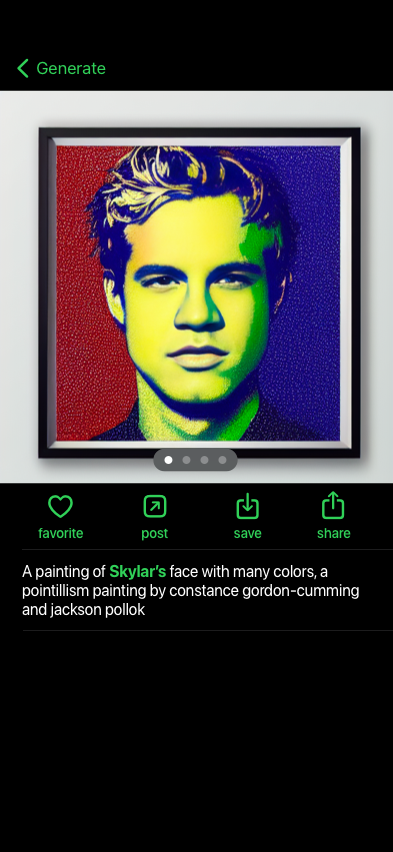
The MyDiffusion app generates images from a text prompt with yourself in the images.
How we built it
We built an iOS app for end users and our backend runs on accelerated GPU cloud machines to run the ML operations. Users first upload photos of themselves and the backend will fine-tune Stable Diffusion using a Dreambooth implementation. Then users can interact with the model by sending prompts and getting back images with themselves in them.
Challenges we ran into
We ran into a few technical problems, the major one was getting an existing Dreambooth implementation to work in a scalable fashion.
Accomplishments that we're proud of
We are proud of building a working demo in such a short amount of time!
What we learned
We learned that the amount of time to build software is longer than expected.
What's next for MyDiffusion
We will continue to refine the iOS app and build the backend to be scalable. Then we will launch a beta on TestFlight for friends and family.

Log in or sign up for Devpost to join the conversation.