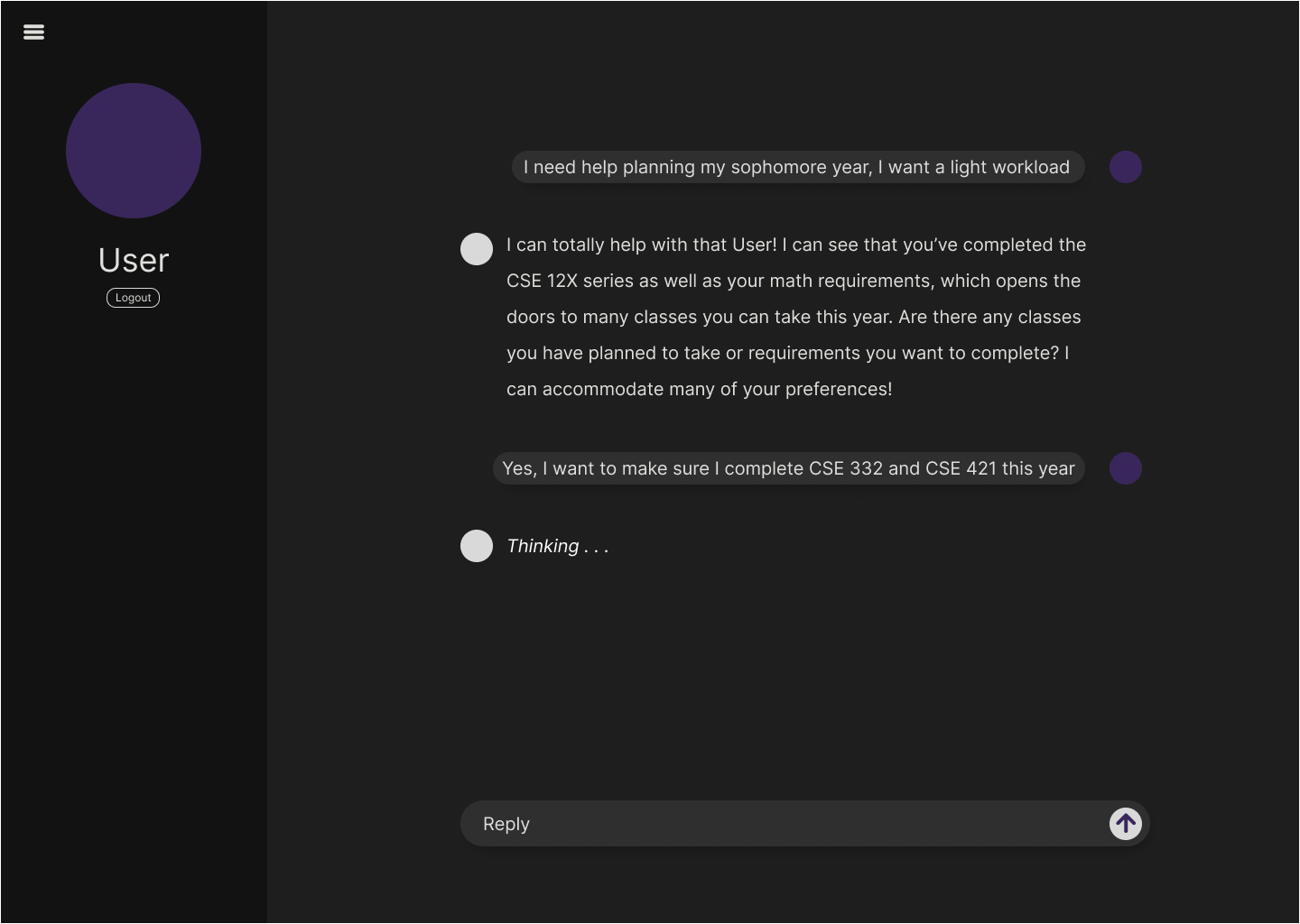
About the Project
As UW students, we often found ourselves overwhelmed by the complexity of degree requirements, course prerequisites, and scheduling. The official tools, while helpful, lacked the conversational, personalized guidance that would make academic planning less stressful, and advisors can only handle hundreds of students everyday. We wanted to build an AI-powered advisor that could supplement student's academic careers by answering questions like "What classes should I take next quarter?" or "Do I meet the prerequisites for CSE 373?" in a natural, intuitive way.
What We Learned
This project was our deep dive into Retrieval-Augmented Generation (RAG) and modern LLM applications:
- Vector Databases: We implemented ChromaDB to store and efficiently search through thousands of course descriptions and degree requirements using semantic similarity
- LLM Integration: We integrated Google's Gemini model to generate contextual, helpful responses based on retrieved information
- Full-Stack Development: We built a complete application with FastAPI backend and React frontend, handling real-time chat interactions
- Data Engineering: We parsed and structured course catalog data from multiple sources (CSV, JSON) into a queryable format
How We Built It
Backend (Python + FastAPI)
- We created a RAG pipeline using ChromaDB for vector storage and semantic search
- We integrated Google's Gemini LLM through LangChain for natural language responses
- We built RESTful API endpoints for chat, profile management, and course search
- We implemented context-aware prompting that considers the user's major, completed courses, and current quarter
Frontend (React + TypeScript)
- We designed an intuitive chat interface for students to ask questions
- We created components for user profiles, FAQs, and course search
- We implemented real-time communication with the backend API
Data Pipeline
- We scraped and parsed UW course catalog data across multiple quarters
- We structured degree requirement documents for efficient retrieval
- We generated embeddings for semantic search using ChromaDB's built-in models
Challenges We Faced
- Data Quality: Course catalog data was inconsistent across quarters and campuses. We had to write robust parsers to handle various formats and edge cases.
- Context Window Management: Balancing the amount of context sent to the LLM was tricky. Too much information led to slow responses; too little resulted in inaccurate answers. We settled on retrieving the top 5 courses and 3 requirement documents.
- Semantic Search Tuning: Getting relevant results from vector search required experimentation with chunk sizes and metadata filtering. Some queries about specific course codes needed exact matching, while others benefited from semantic similarity.
- Dependency Hell: BeautifulSoup's lxml parser requirement caused deployment headaches—a reminder to always document dependencies clearly!
What's Next
- Implement user authentication and persistent storage for profiles
- Add features to visualize current course plans
- Add additional course details (such as instructor names and course difficulty)
- Expand to support more majors beyond Computer Science




Log in or sign up for Devpost to join the conversation.