Inspiration
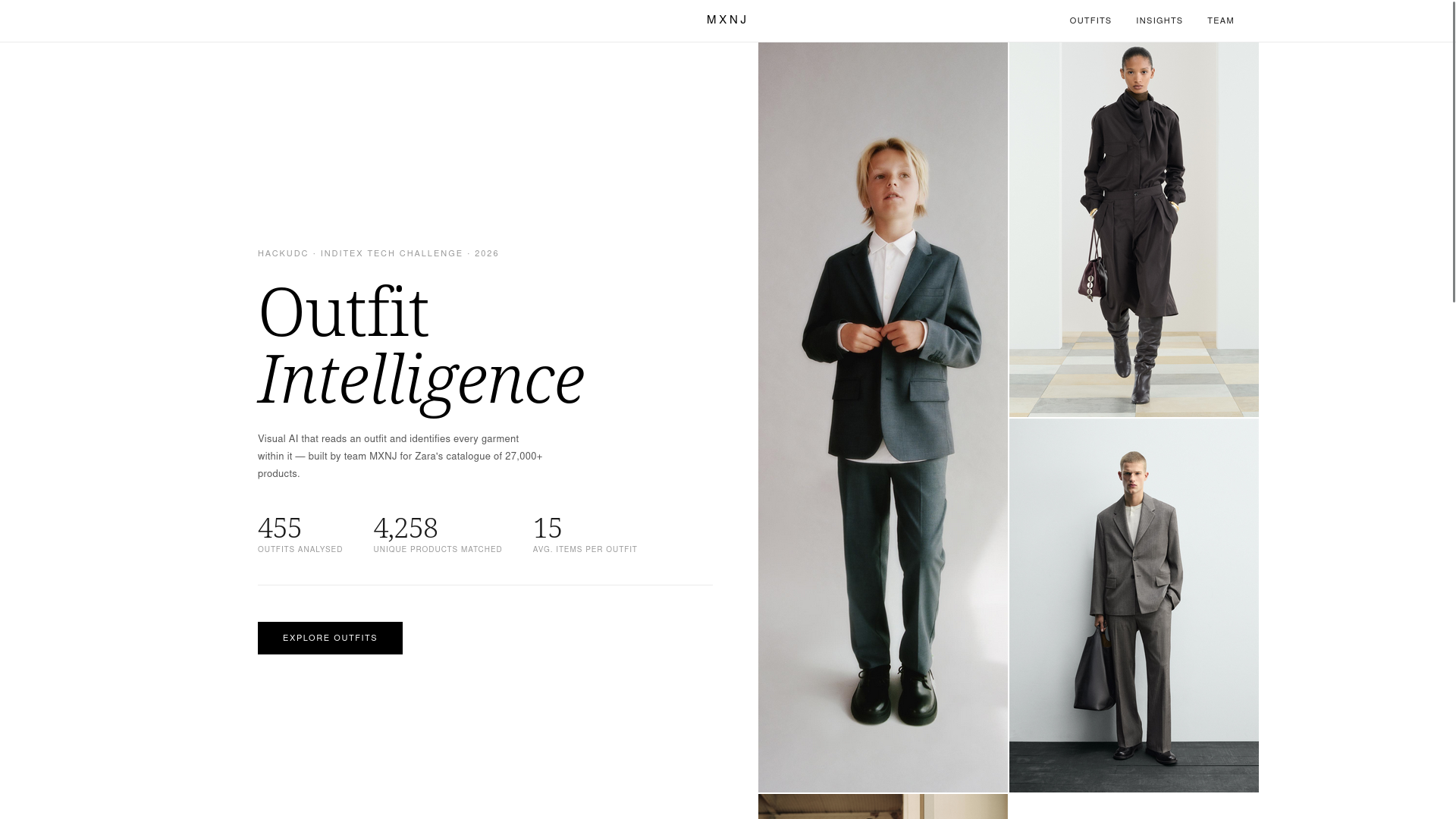
Fashion search is a visual problem: you see an outfit on a model and want that exact shirt from the catalogue, but you can't describe it well enough for text search to work. We wanted to solve that with open-source AI — no closed APIs, no black boxes.
How we built it
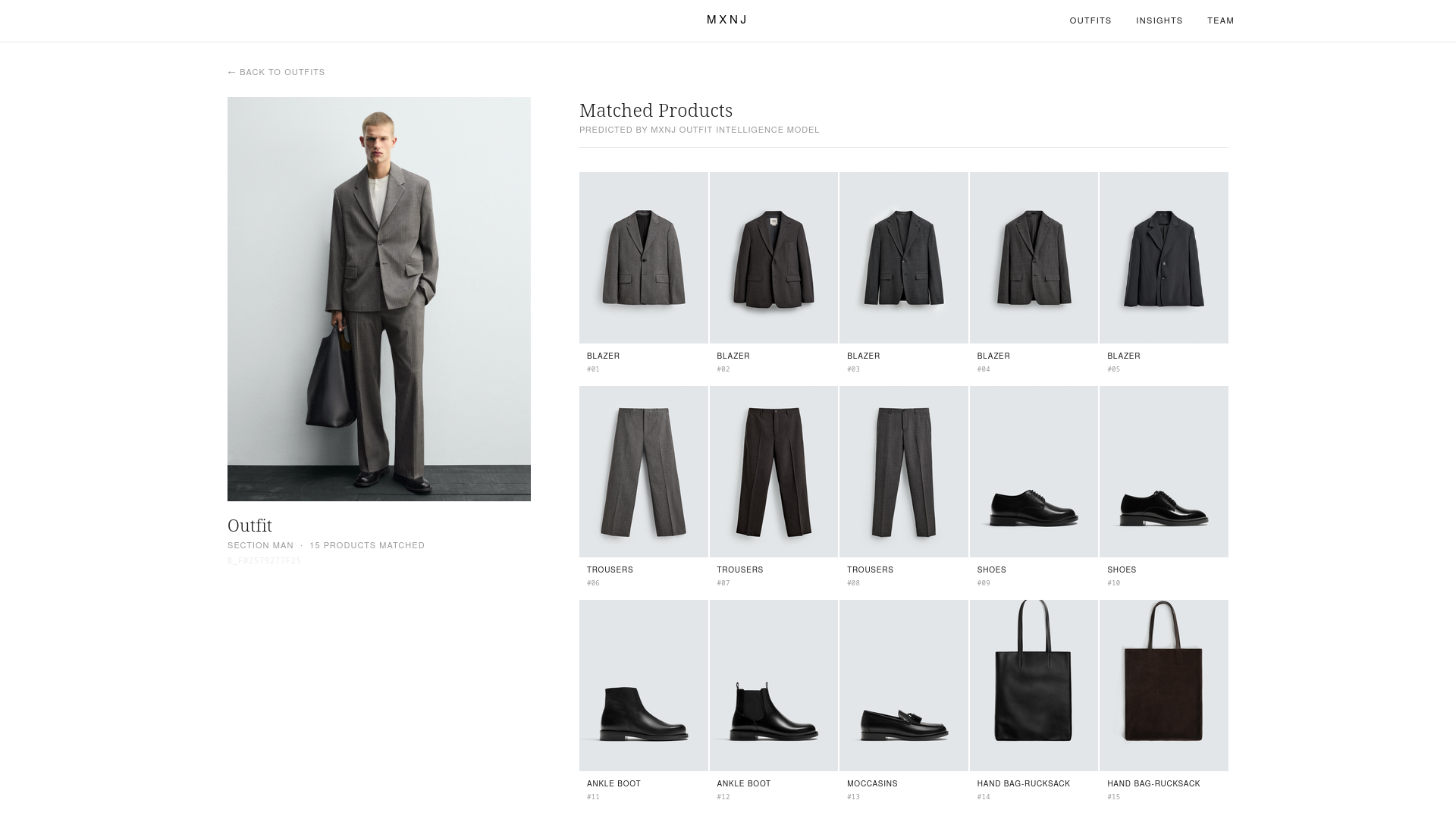
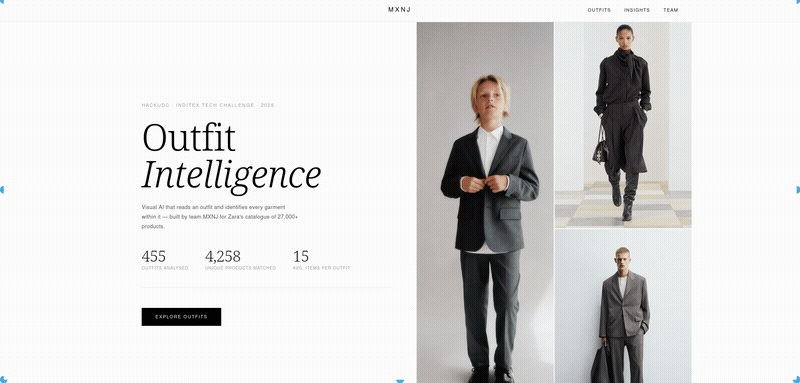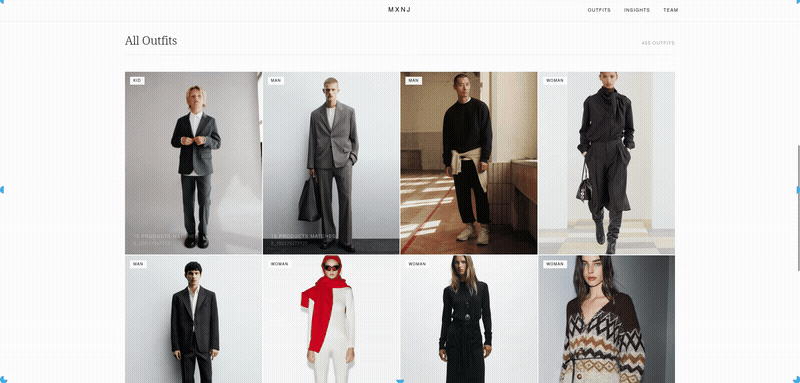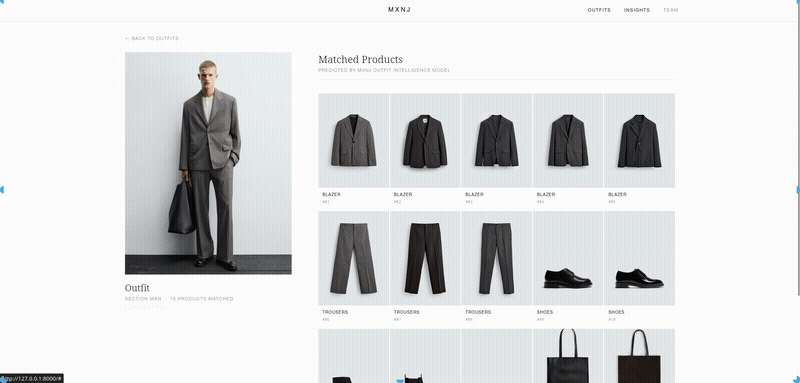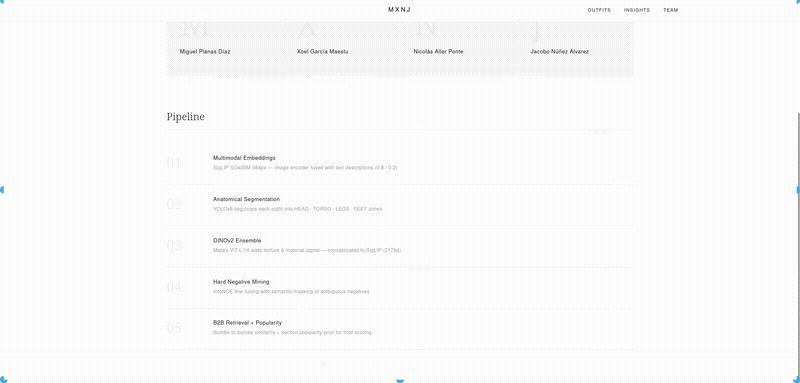
We detect the person in each photo and split them into body zones (head, torso, legs, feet). Each zone is matched separately against the product catalogue using two complementary open-source vision models — SigLIP and DINOv2 — fine-tuned on the specific Inditex domain with contrastive learning. Business signals like collection timestamps and SKU prefixes add a final scoring boost.
The key trick was a semi-supervised loop: our own high-confidence predictions on test photos were fed back into the retrieval index as pseudo-labels, letting similar outfits inform each other's results without any new annotations.
Challenges
Fitting two large vision models into 16GB VRAM, calibrating which predictions were confident enough to recycle as pseudo-labels, and forcing diversity in the top-15 results so the same shirt in five colorways doesn't eat all the slots.
What we learned
The gap between an editorial photo and a white-background product shot is huge for a vision model. A small fine-tuning step with hard negatives bridges it efficiently — and anatomy-aware matching (don't look for shoes in the torso crop) matters more than model size.


Log in or sign up for Devpost to join the conversation.