-
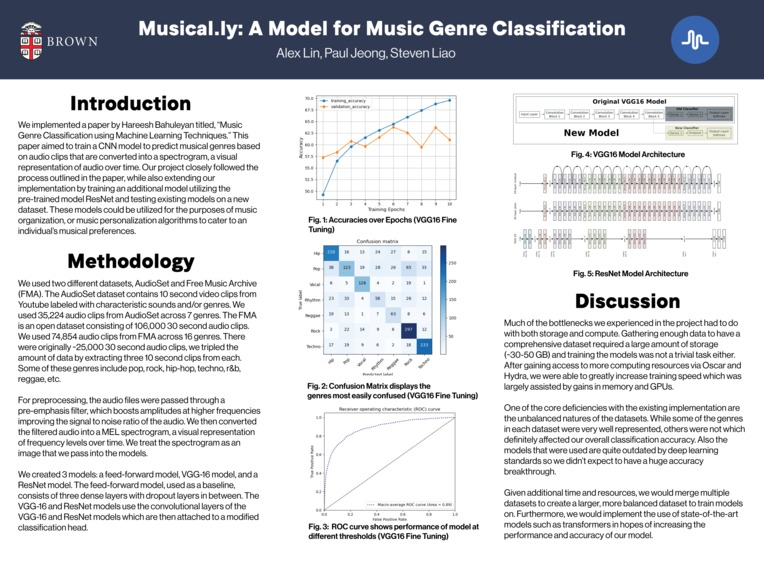
Final Poster
------------------------------------------ Final Submission -----------------------------------------------
The final poster is attached as an image. It can also be found here
------------------------------------------Check In's 1 and 2 -----------------------------------------------
Title
Musical.ly
Summarize the main idea of your project.
Music Genre Classification
Who: Names and logins of all your group members.
Paul Jeong - pjeong1 Steven Liao - sliao10 Alex Lin - alin90
Introduction:
The paper’s objective is to explore machine learning algorithms, classify and identify the genre of audio files. This problem is a classification problem.
Related Work:
We read an article on music genre classification using CNNs. They make use of the GTZAN dataset which contains music of 10 different genres. The features they fed the CNN were a mix of spectrogram, mel-spectrograms, and MFCCs which is similar to the implementation the original paper we chose used. This article only covers the feature extraction, but eventually the features are used to classify the audio files’ genre.
Data:
The dataset that we are using is the AudioSet dataset from Google, which consists of 10-second curated clips from YouTube that are grouped by labels. These groups include everyday sounds, like car horns, instruments, and genres of music. We will likely be looking at the labels that are genres of music. The dataset contains 2.1 million videos, with about 1 million being labeled as music. The paper implemented a total of 40540 videos from the following genres: pop music, rock music, hip hop music, techno, rhythm and blues, vocal, and reggae music.
For the CNN architecture, the paper outlines the preprocessing pipeline applied to the audio. First, a pre-emphasis filter is applied to the audio signal which will boost amplitudes at higher frequencies. Next, the audio is converted to a spectrogram, which is a visual graph outlining the frequencies and their corresponding amplitudes over time.
For the data passed into the machine learning classifiers, the raw audio signal is used to extract time domain and frequency domain features. For each of the features, the mean and standard deviation is taken which is then passed as the input for the classifiers.
Methodology:
For the CNN model, we will use the VGG-16 model, which consists of five convolutional blocks followed by a set of dense layers. We will use the five convolutional blocks of the VGG-16, then feed its output to our own set of dense layers which will then predict the genre of the audio using cross-entropy loss. For training, we will feed the spectrograms into the CNN starting with the original VGG-16 weights, but we will allow the weights to be modified throughout the training process. The hardest part will most likely be implementing the machine learning classifications, as we have not dealt with those implementations before.
Metrics
Success metrics Success will be measured by how closely we can reach the accuracy reached by the paper. For the Ensemble Classifiers using VGG-16 CNN + XGB, the target goal is to reach a target accuracy of 0.65, an F-score of 0.62, and an AUC of 0.894.
The base goal will be to reach a target accuracy of 0.5, an F-score of 0.5, and an AUC of 0.5.
The stretch goal will be to reach a target accuracy greater than 0.65, an F-score greater than 0.62, and an AUC greater than 0.894.
Accuracy: Refers to the percentage of correctly classified test samples [https://arxiv.org/pdf/1804.01149.pdf].
F-score: Based on the confusion matrix, it is possible to calculate the precision and recall. The F-score is then computed as the harmonic mean between precision and recall [https://arxiv.org/pdf/1804.01149.pdf].
AUC: This evaluation criteria known as the area under the receiver operator characteristics (ROC) curve is a common way to judge the performance of a multi-class classification system. The ROC is a graph between the true positive rate and the false positive rate. A baseline model that randomly predicts each class label with equal probability would have an AUC of 0.5, and hence the system being designed is expected to have an AUC higher than 0.5 [https://arxiv.org/pdf/1804.01149.pdf].
Experiments The model will be tested on the 3 metrics accuracy, F-score, and AUC described above. The model will be tested on a subset of the data (10%) set aside for testing purposes.
A confusion matrix will also be created with the categories hip-hop, pop, vocal, rhythm, reggae, rock, and techno to evaluate if our implementation performs similarly to the paper. Paper’s Discussion of Metrics The original authors implemented on top of the VGG-16 convolution a variety of different machine learning classification heads. Each of their implementations was tested with the above 3 metrics. The spectrogram-based models performed better than feature engineering-based models, and the ensemble classifier performed the best overall. The authors went on to analyze the most important features of the data samples concerning the prediction. The most important feature was concluded to be Mel-Frequency Cepstral Coefficients (MFCC). Furthermore, the authors produced confusion matrices for VGG-16 CNN Transfer Learning, XGB, and Ensemble models. The matrices showed the model had the most difficulty distinguishing hip-hop and pop music from other genres the most.
Ethics
The dataset is Audio Set, created by human-annotating 10 second clips extracted from 2.1 million YouTube videos. Only the audio clips relevant to music will be used. The open source nature of YouTube means that the clips will tend to include the works of more popular genres and music than more niche categories. The clips thus might not be representative of every type of music. However, this is not discouraging since only several common types of music will be predicted.
The major stakeholders are artists, producers, and musicians whose work will one day be put through a network of streaming services such as Spotify. Their music will be recommended to users based on user taste. For smaller and up-and-coming artists, making it big will partly rely on the algorithm recommending their music to streamers. Faulty or biased algorithms toward certain genres of music can hinder an artist’s full potential. On the other hand, music taste is extremely subjective, and it is hard to quantify how much an artist’s music is impacted by biased algorithms since there is no concrete way to quantify how many people will like the music. The consequences of faulty algorithms are therefore subtle, and not as impactful in the music industry as it is in other industries (e.g. travel industry).
Division of labor: Briefly outline who will be responsible for which part(s) of the project.
------------------------------------------Check In 3 -----------------------------------------------
Introduction
The project's objective is to explore machine learning algorithms, and classify and identify the genre of audio files. This problem is a classification problem.
Challenges: What has been the hardest part of the project you’ve encountered so far?
We had a bug with the initial downloading of the data that had to do with a package being outdated. We had to modify a bit of the code to accommodate this change but it works now. Other than that, it's been a bit challenging replicating all of the Tensorflow steps into Pytorch. A lot of the syntax is different and some functions are pretty different.
Insights: Are there any concrete results you can show at this point?
We can't show results yet in part because of an oscar issue. We want to use oscar to run the models because they will run much faster with all of the compute. So our strategy is just to finish other aspects of the project in the meantime and put them together when oscar works.
How is your model performing compared with expectations?
Not sure yet but no concerns that it should be able to perform up to expectations.
Plan: Are you on track with your project?
Yes overall I believe that we've done enough work right now to be on time. We've had to do a few things out of order but other things have been done in the meantime.
What do you need to dedicate more time to?
At this point we need to focus on getting the data downloaded properly using oscar.
What are you thinking of changing, if anything?
Nothing as of now.

Log in or sign up for Devpost to join the conversation.