-
-
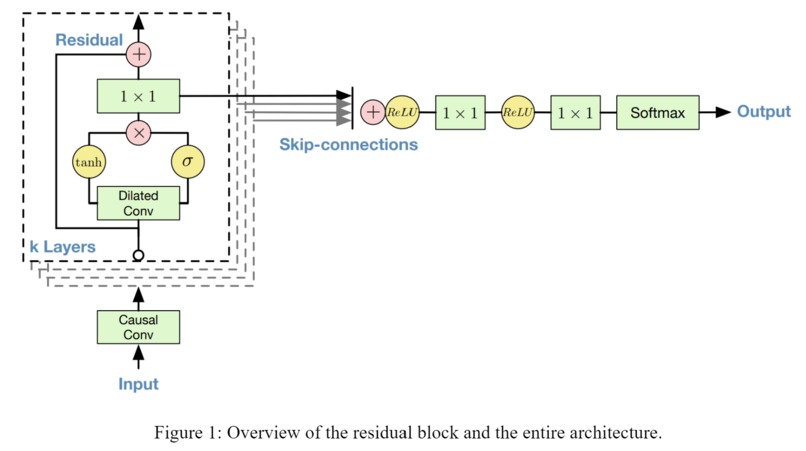
Model architecture
-
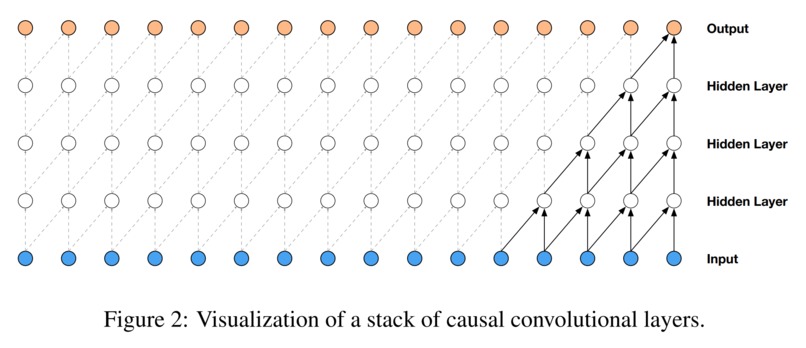
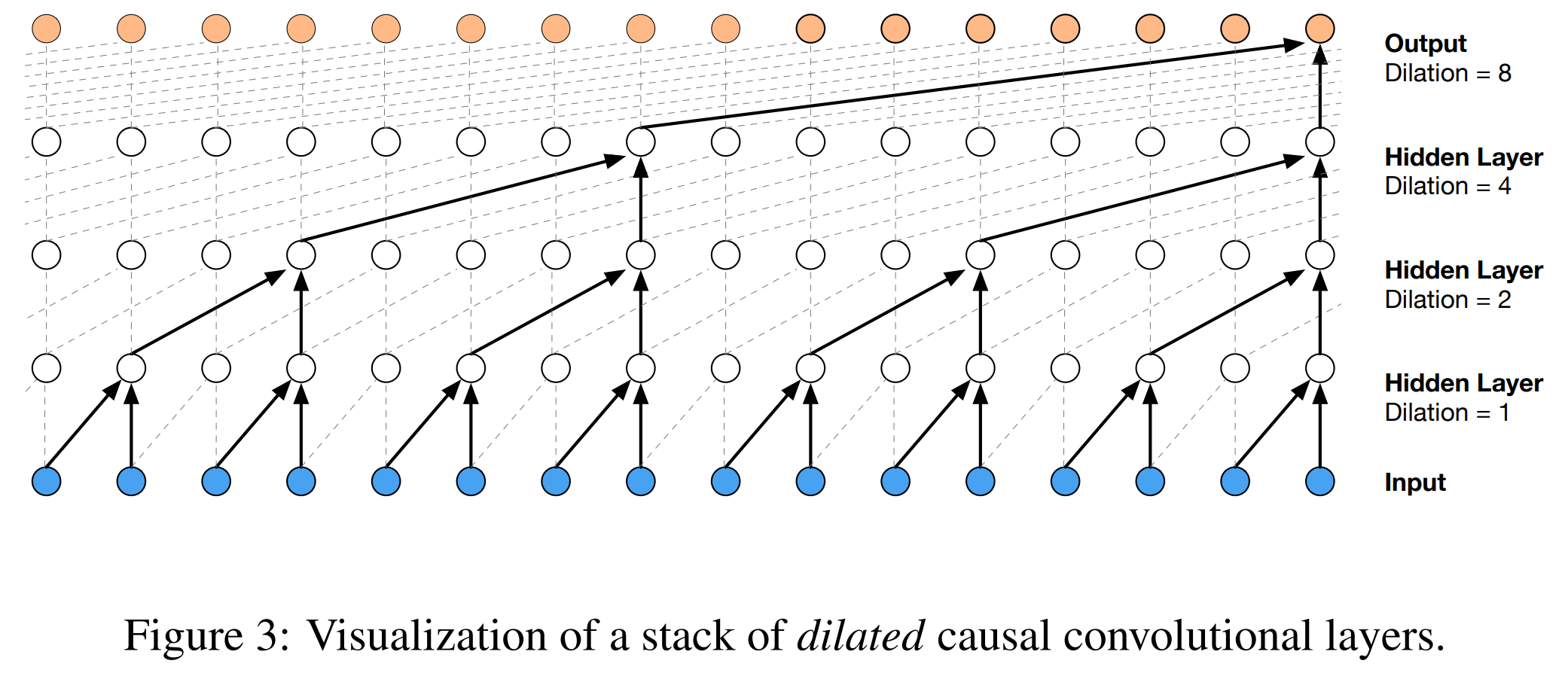
Casual dilated convolution layer
-
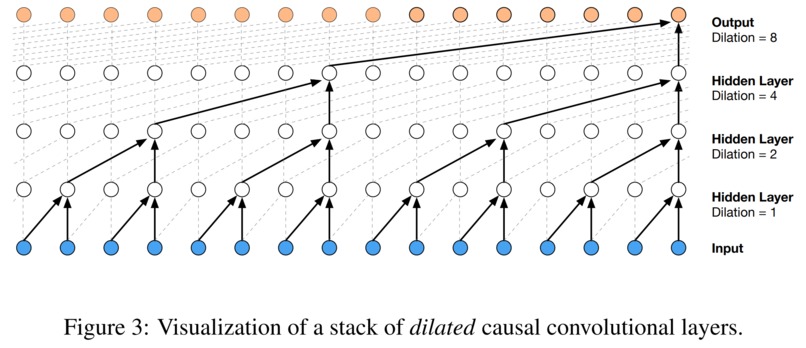
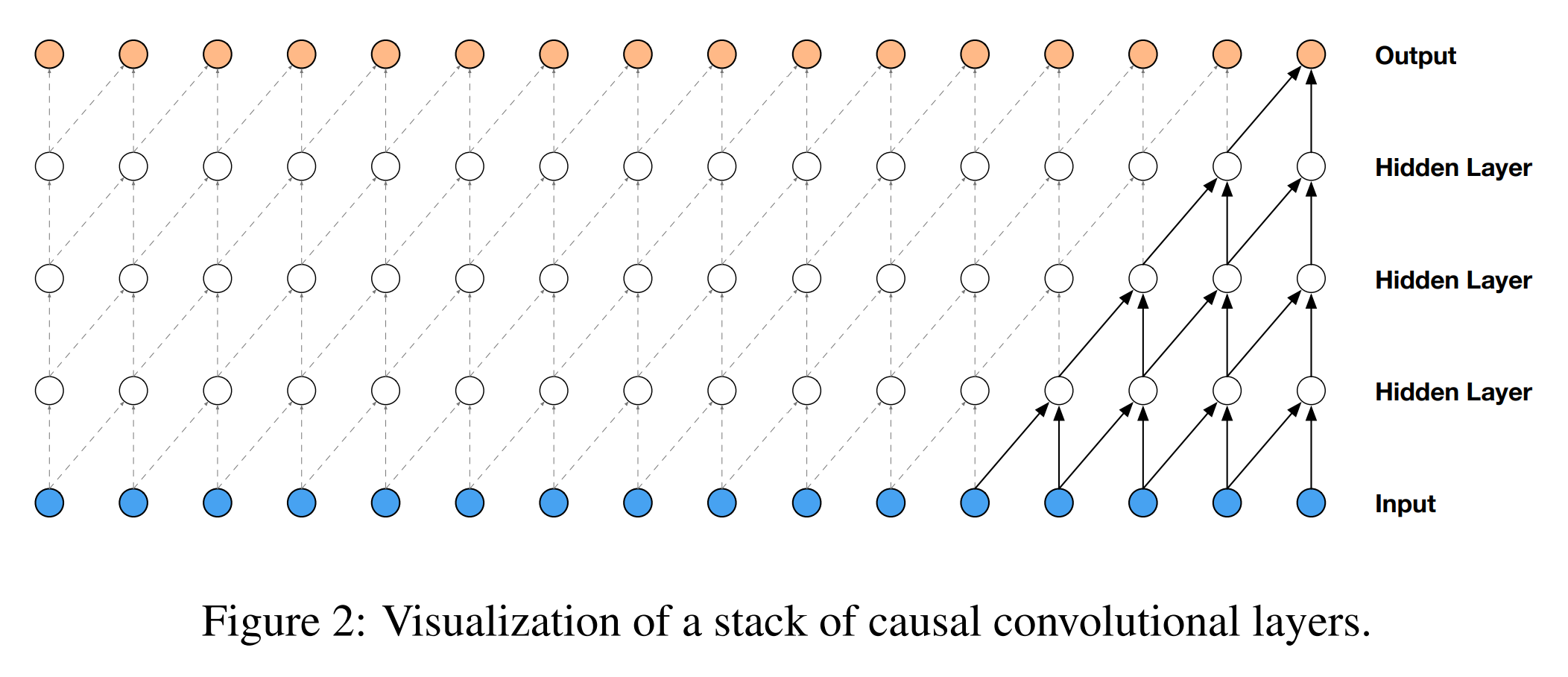
Casual convolution layer
-

Tensorflow Model for midi
-
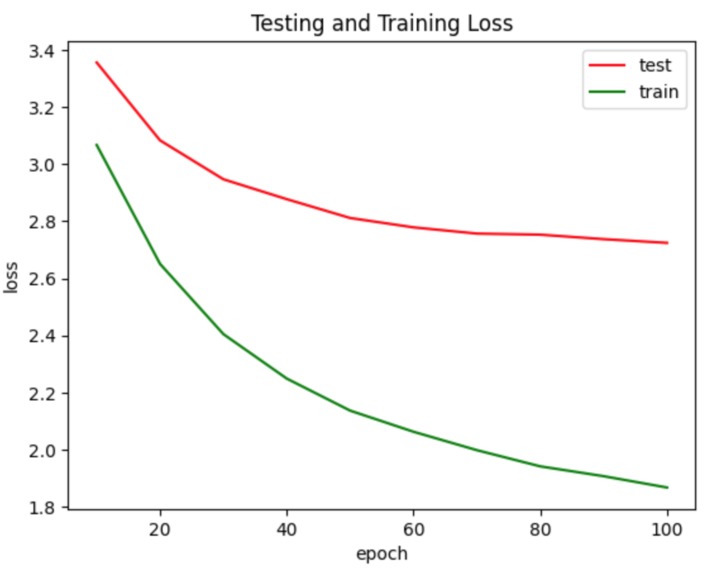
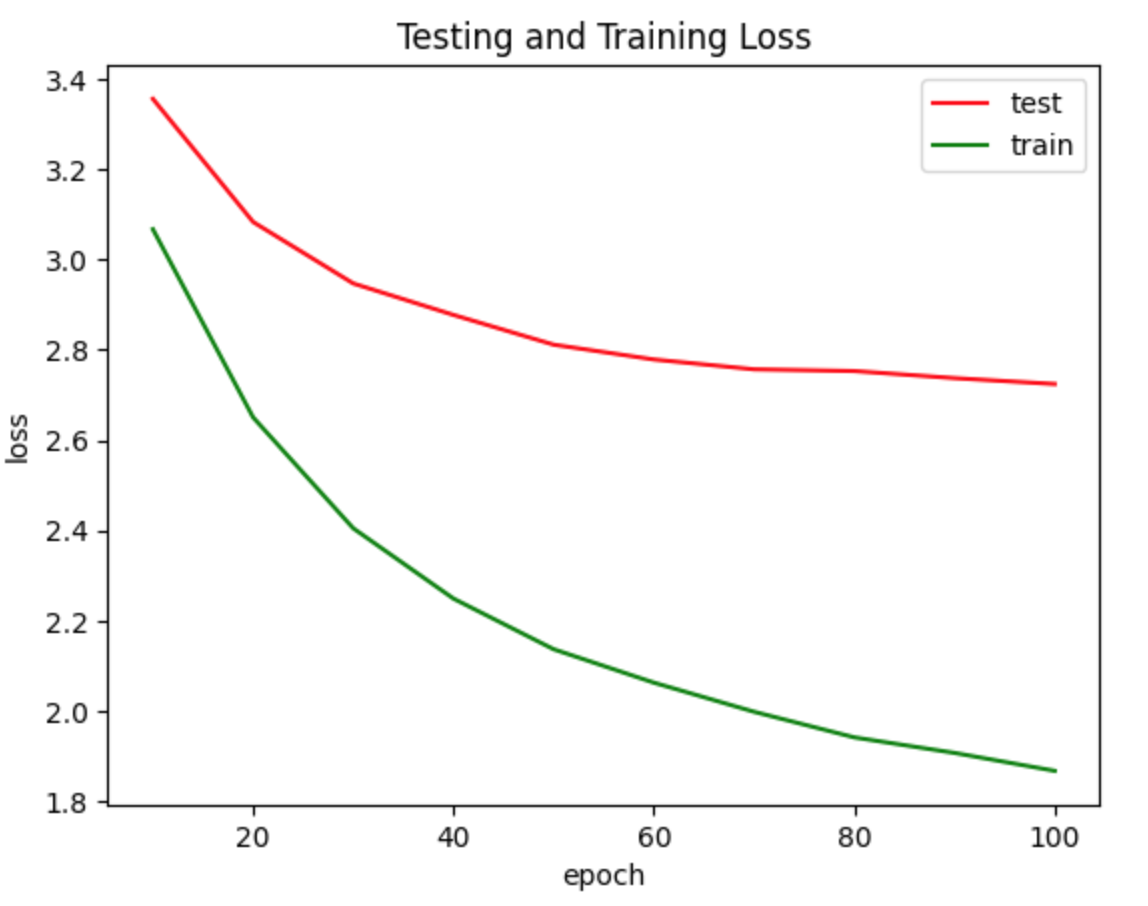
Training and testing loss for midi
-
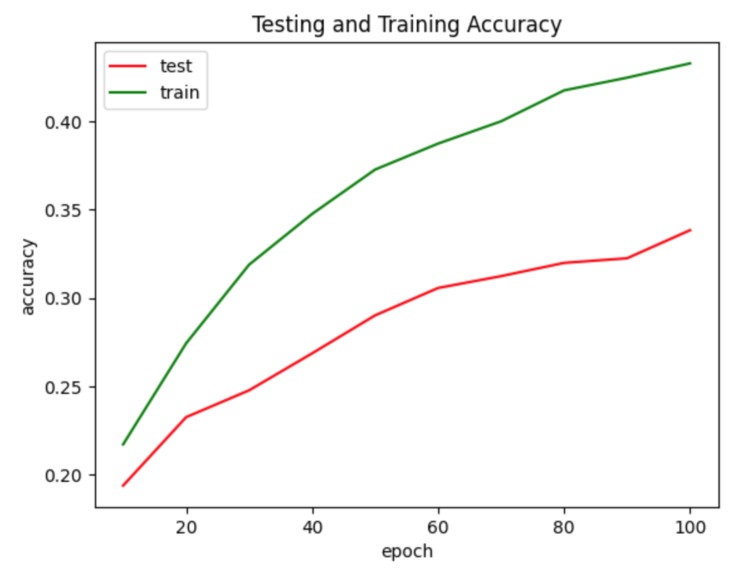
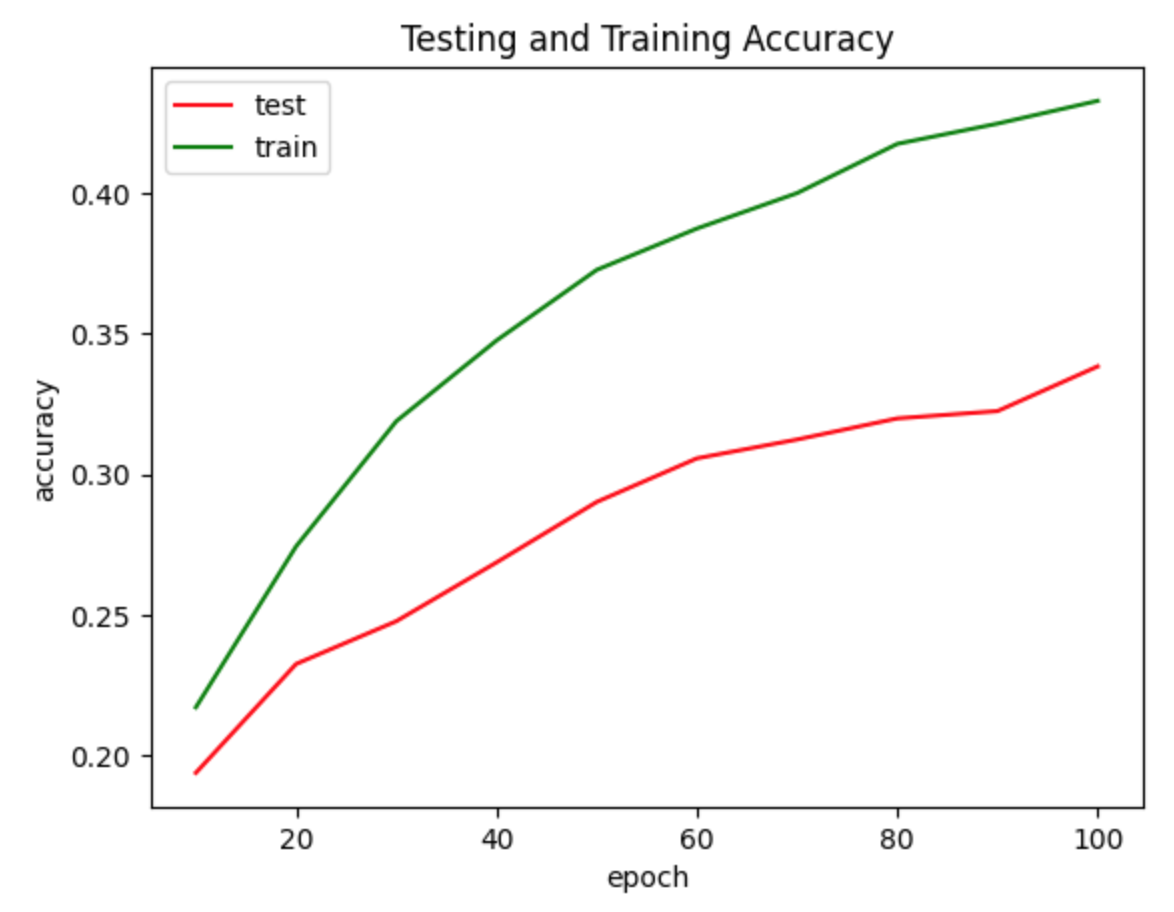
Training and testing accuracy for midi
-

Tensorflow Model for wav
-
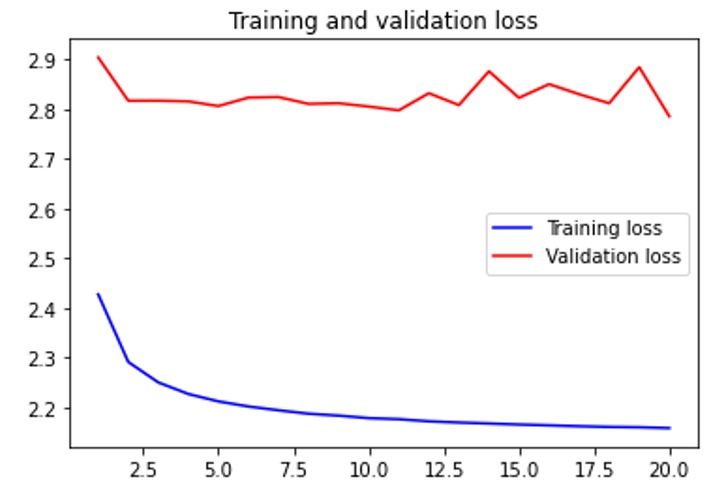
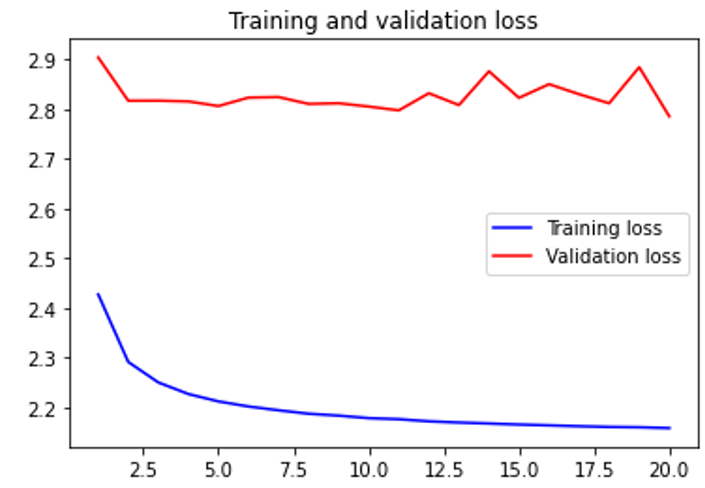
Training and testing loss for wav
-
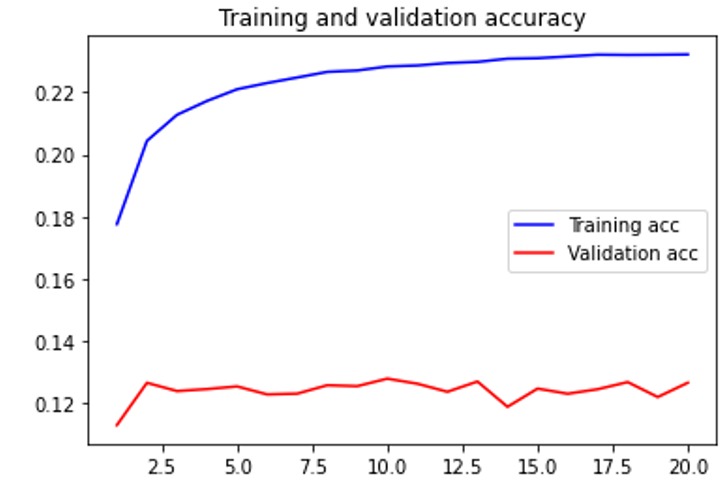
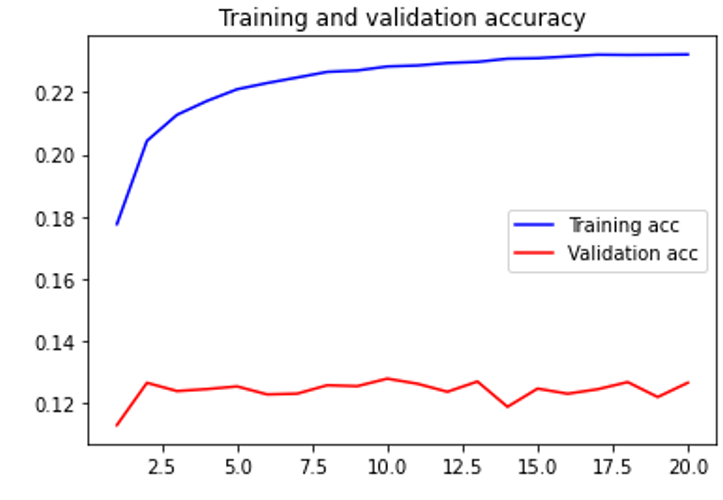
Training and testing accuracy for wav
-

Poster



Check-in information can be accessed here
A more readable version of the final report can be accessed here
Team Members: Yutong Wang, Zhijun Liu, Shuyang Song, Rosanna Zhao
Introduction
Deep learning is changing the way we listen to and create music. AI music generation is drastically increasing in popularity, with Magenta Studio, MuseTree, and Juebox being examples of some of the most popular software. In our implementation, we mimic the WaveNet model. The base goal of this project is generating a seven-second audio file with a training set of twenty Beethoven’s piano songs by following the model architecture of the source code. The target goal is improving the code such that it is an easy-to-use object-oriented API. The stretch goal is enhancing the model by directly training .wav files (waveform) instead of .midi files (musical notes), which is the type of file used in the reference code.
Related Work
Since WaveNet was first proposed in late 2016 and has nearly six years of history, there are several papers and implementations related to WaveNet available in academic literature. We referenced Oord et al (2016), which introduces the structure of the model and mentions potential applications such as text-to-speech translation and music generation. Besides the paper, our implementation is based on this source code named Music Generation Using Deep Learning, which is a precise reconstruction of the original model. In this code, the input data is .midi files, which can be easily converted into notes during preprocessing, and the output is also a .midi file, which is the prediction of the music.
Methodology
Data
The data used in this project for music generation is 20 piano songs composed by Beethoven. The data is in .midi format, and the reason .midi is used as the input data format is that it can be directly converted into a list of notes, which can be fed into the model in a straightforward way. However, since .midi files are not as common as .wav and .mp3 files, and usually people need extra tools and websites to listen to music in .midi format, we tried to improve the model by changing the input format into .wav or .mp3 files. By doing this, we made sure that we modified and attempted to improve the published model in our own way.
For our stretch goal, we tried training directly with .wav files. Since .wav files record data with waves instead of music notes as .midi does, the data size is significantly larger. We fetched .mp3 files from music websites like NetEase Cloud Music with a web crawler. During preprocessing, we first converted the .mp3 files to the .wav format, loaded them with Librosa, trimmed silence, converted them to mono wave forms, and mapped them from [-1, 1] to [0, quantization_channels - 1] with μ-law-encoding. Then, we split the 1-D input tensor into x and y, one-hot encode y, and split them into x_train, x_val, y_train, and y_val, each of shape (x, time_steps), (x/4, time_steps), (x, quantization_channels), and (x/4, quantization_channels). However, training with this data turned out to be unsuccessful, due to reasons which we will elaborately review in the Challenges section.
Model
WaveNet generates the audio relying on its memory of all previous data in the sequence, a similar approach to Recurrent Neural Networks (RNN), and thus is structured as a prediction problem. Given inputs (x1, x2, …, xt), the ultimate goal of this project is to predict the joint probability mass function p(x1, x2, …, xt). A single WaveNet cell contains a dilated causal convolution, a softmax function, a tanh activation that gates the output, and a residual and parameterised skip connection that speeds up the convergence of the model. The overall architecture of the model can be found in the media section.
The training process with WaveNet is similar to that of natural language processing (NLP). In a traditional language model, the model tries to predict the next word when given a sequence of words. Similarly, in WaveNet, the model tries to predict the next sample when given a sequence of samples. In this project, the input data is multiple audio files of the same length, denoted as x1, x2, … xt. During the training process, the model predicts x̂n based on (x1, x2, …, xn-1) and compares the result with the ground truth (xn) to obtain the MSE loss.
The type of convolution layers that build up WaveNet are Causal Dilated 1-Dimensional Convolution layers. A Causal Dilated Convolution is a causal convolution where the filter is applied over an area larger than its length by skipping input values with a certain step. A dilated causal convolution effectively allows the network to have very large receptive fields with just a few layers.
In the complete workflow of WaveNet, the input data, denoted as x1, x2, … xt. is fed into a Causal 1-Dimensional Convolution layer. Afterwards, the resulting output is fed to two different Dilated 1-Dimensional Convolution layers, one with sigmoid activation and another with tanh activation. The element-wise multiplication of the two different activation values results in a skip connection. The element-wise addition of a skip connection and the output of the Causal 1-Dimensional Convolution layer results in the residual. Both the residual and the skip connection functions are useful in speeding up the convergence of the model.
Hyperparameters
Important hyperparameters include:
- time_steps: the length of x to predict the next y. We found 32 to be appropriate.
- quantization_channels: the size of embedding. We found 256 to be appropriate.
- samling_rate: number of samples per second. 44100 is usual for most audio files, but we used 1600, 3200, and 16000 to reduce the amount of data.
- batch_size: we found 128 to be appropriate.
- epoch: for our target goal: we trained with 100 epochs; for our stretch goal, since sampled data from .wav files are significantly larger than that of the .midi files, we chose to train only 20 epochs due to the limitation of RAM.
Results
Target Goal:
When training with 32 time steps, 128 batch size, 100 epochs, and 20 pieces of piano music (about 100 minutes in total), we obtained the following results (see the graphs with red and green lines in the media section). At the end of the training process, the test accuracy is about 0.34, and the loss is approximately 2.72. As for the actual output, we generated a seven-second audio with Beethoven’s music as its input data. Please access the audio file here.
Stretch Goal:
When trained with 32 time steps, 1600 sample rate, quantization channels 32, batch size 128, 20 epochs and four pieces of Guzheng (a traditional Chinese instrument) music (total ~20 minutes), the results are the graphs with red and blue lines in the media section. At the end of the training process, the testing accuracy is about 0.12, and the loss stays around 2.8. Our ten-second output can be accessed here.
Challenges
One of the first major challenges of this project was finding a source code that was able to run successfully. Since the paper we referred to, which helps us understand WaveNet and music generation, was written more than five years ago, the attached code provided in the paper depends on TensorFlow 1, instead of the newer TensorFlow 2. Thus, multiple areas of the code needed to be fixed such that it would run with the newest version of TensorFlow.
Runtime was a significant challenge in general for this project. For our basic goal of training on .midi files, training locally took about 20 minutes to complete five epochs, so we switched to Google Colab and used the free GPU to train the model. Training was significantly faster, and we were able to train 100 epochs.
For our stretch goal, we encountered various problems training with .mp3 data from music websites. We explored different Python audio processing modules, including TensorFlow I/O, SciPy, and Librosa, which all have limited support with .mp3 files. Converting from .mp3 to .wav usually takes a long time and memory, and splitting them into training and testing datasets are memory-consuming too. On Google Colab, the RAM is often filled up after preprocessing about 5 audio files (a total of ~20 minutes), which results in 19,200,000 samples (for a sampling rate of 16,000). Therefore, we tried to reduce the sampling rate to cut data size.
Due to the immense amount of data in .wav files, training wasn't successful either, even on Google Colab. We had to balance between original data size and epochs to ensure the kernel doesn't crash. Oftentimes, memory fills up quickly.
Finally, results for training on waveform didn't sound ideal. Initially when we trained on Beethoven's piano pieces, we produced noise similar to a TV static noise instead of melodic piano music that we expected. We realized that the key issue might be we didn't implement μ-law-encoding and one-hot encoding. After modifying encoding, the output no longer had static noises, but it still did not contain any melodies. This challenge was unable to be resolved and is discussed more in the following section.
Reflection
Overall, we are satisfied with being able to make the project code run successfully and generate a 10-second audio file. We were able to reach our target goal of generating an audio file with a training dataset consisting of twenty piano songs by Beethoven through improving the reference code by changing it to be an easy-to-use object-oriented API. However, the output audio file does not sound musical (i.e., we can tell there were musical notes being generated in the audio file; however, the music did not have the best composition). Furthermore, we were unable to reach our stretch goal of improving the model by directly training .wav files instead of .midi files used in the reference code. We expected the output to sound like a piece of well-tuned classical music composed by a C-grade student of Mozart, but instead, it sounded like the electromagnetic noise emitted by the planet Venus as recorded by the NASA voyager (check out this video out if you are unsure what it sounds like).
We might achieve better results with our stretch goal if we had more time and resources. First, we could improve the loss function. Currently, we directly use TensorFlow's categorical cross-entropy, but improving the loss function might achieve better results through optimization of gradient descent. Second, due to the limitations of the free version of Google Colab, we were not able to train on larger datasets or for more epochs. The original paper suggests that training on 8-10 hours of music data and 1,500 epochs might achieve ideal results.
Beyond our stretch goal, we would have hoped to expand the scope of the generated music. We do not specify the genre or additional expectations of the output audio file. A change that could be made would be to be able to specify a specific genre, key, or vocal of the output audio file to be (such as keys = A minor, genre = rock & roll, vocal = soprano). WaveNet is also originally designed for human speech synthesis, and that would be a more challenging goal to achieve.
Ultimately, this project left us each with many important takeaways. None of our group members had ever implemented a deep learning model for a topic or application of our choice. It taught us how to search for reliable state-of-the-art research papers, understand other people’s implementation via reading and digesting the code being provided, brainstorm additional changes that we could make, and modify the code according to our customized needs. We also learned that effective communication is vital to the success of this project.
References
Oord, A. V. D., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., ... & Kavukcuoglu, K. (2016). Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499.
Built With
- python
- tensorflow
- wavenet




Log in or sign up for Devpost to join the conversation.