-
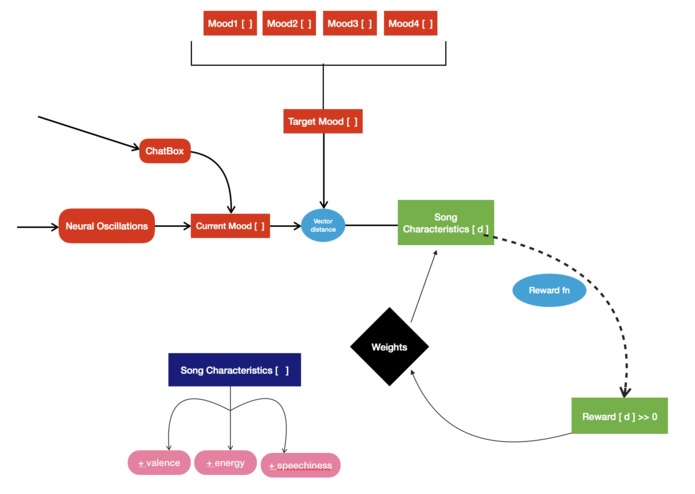
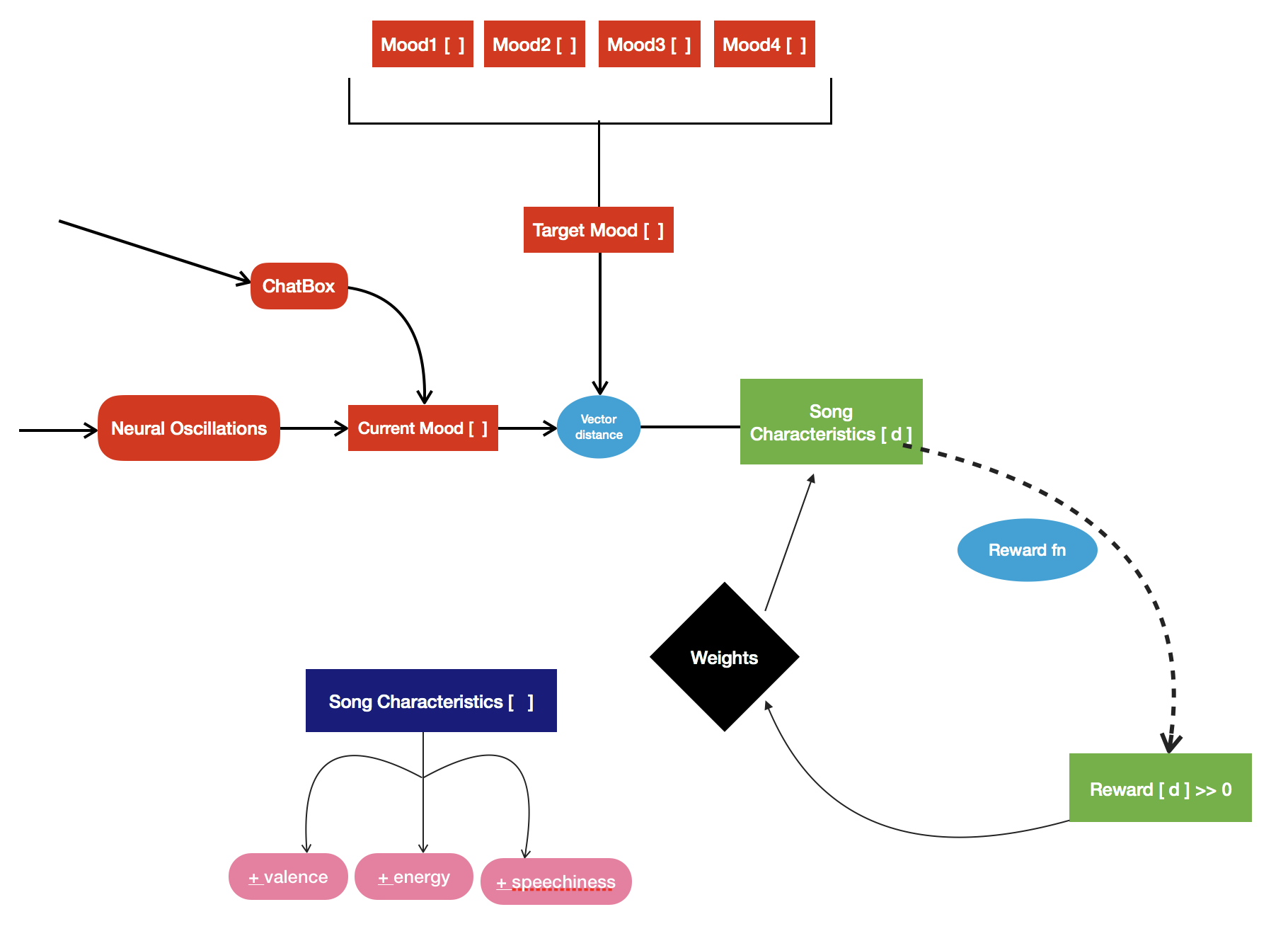
Flow Chart of the Reinforcement Learning Algorithm
-
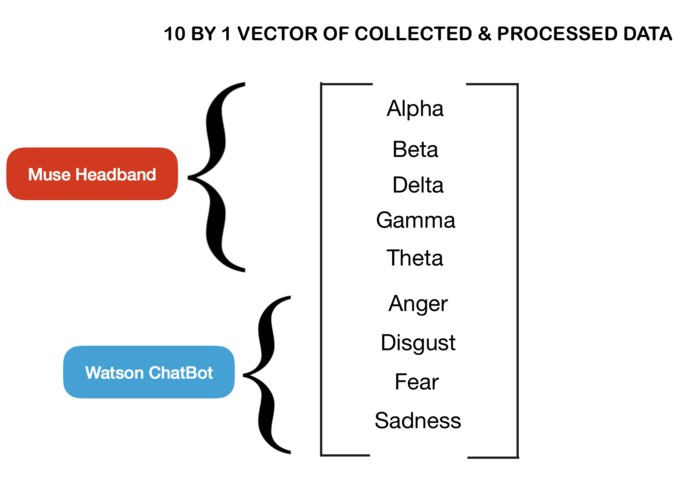
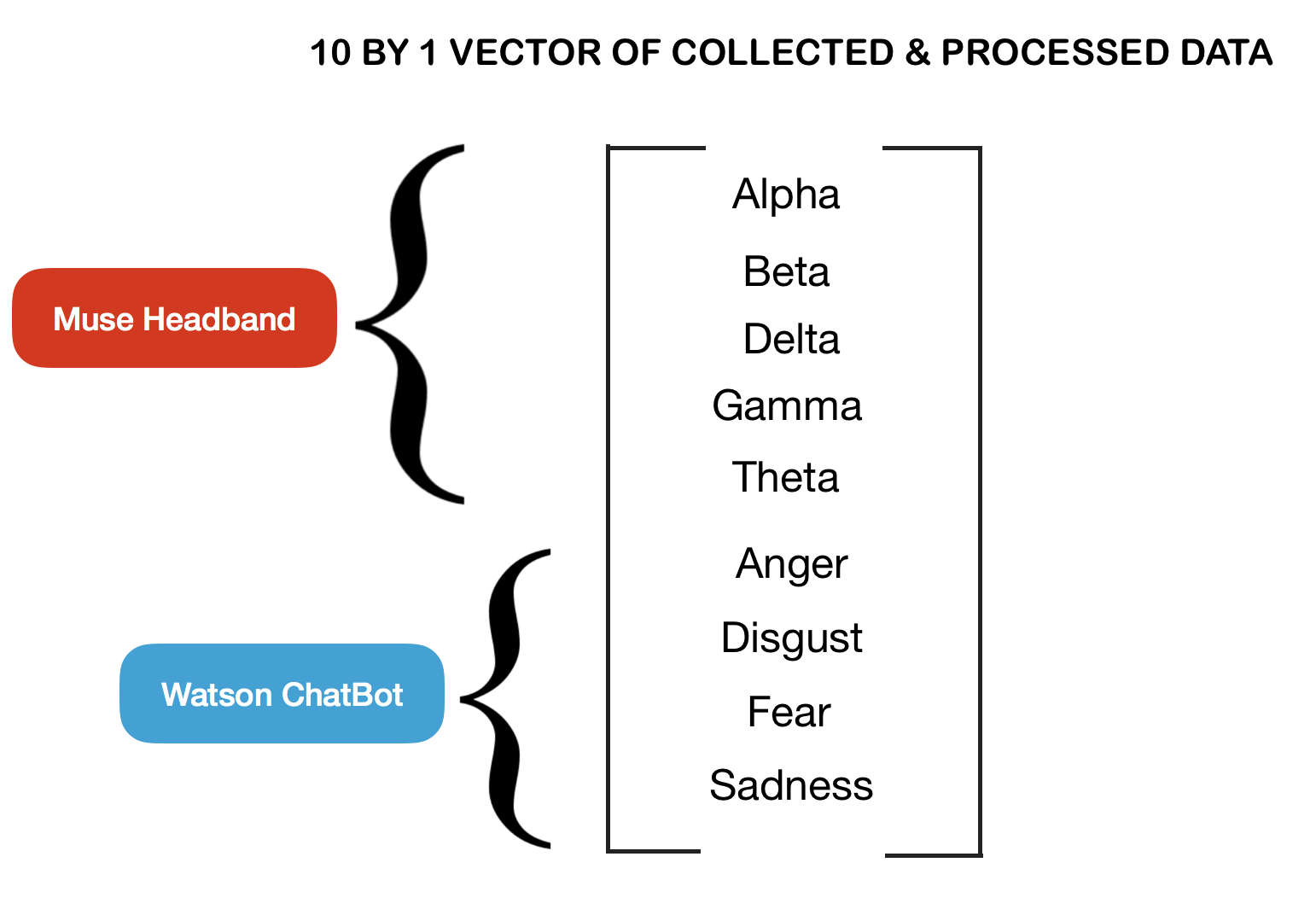
Inspiration
Often, we try to use music in order to focus, go to sleep or just relax, but it is difficult to find the right playlist with the right genre for the right moment. We were inspired by the simple idea that my partner and I listened to vastly different genres of music before our athletic meets. Thus, we decided to take this idea to the next level by aiming to assist any individual to smoothly transition from between moods using intelligent playlists.
What it does
Our ‘self-teaching’ mood alteration software consists of an interconnected suite of three core technologies – a Muse headband that generates the 5 primary brainwaves, a tone analysis of text generated by a Chatbot made on IBM Watson, and the Spotify API to play the music. We used a reinforcement learning algorithm to learn to map the initial
In plain terms, the reinforcement learning aspect ensures that the software can study the effect of different songs on the brainwave activity and mood, and as a result extrapolate a co-relationship between the choice of song and one’s mood.
Museic is an individualised interface that uses Reinforcement Learning Algorithms to learn to create intelligent playlists to take a user from some initial mood to a final desired state of mind. We measure their ‘state of mind’ through brain wave detection using the Muse Headband and the IBM Watson Tone Analysis API. The software has the following 5 moods & final states to choose from – Calm, Excited, Empathetic, Alert, and Complete.
How we built it
Museic makes use of the 2-combination input of the Muse headband brainwaves and a Chatbot built using the IBM Watson Tone Analysis API to serve as our initial and final mood standards.
We first extracted the processed Muse data that gave us the relative abundance of the 5 wave frequencies (alpha, beta. These 5 wave relative amplitudes (on a scale of 0-1) were combined with the Chatbot data (also on a scale of 0-1) to form a 10 by 1 vector that was compared to standardized vectors for each target mood (based on research from tertiary sources). Difference vectors were thereby generated and reward functions were assigned if the difference vector of the succeeding step was lesser in magnitude than the preceding – the premise of Reinforced Learning Algorithms. Thus, post carrying out several iterations on the test individual, the software was able to alter the mood of the individual more accurately – with a convergence toward the target mood (with the difference vector of approaching 0 magnitude).
Challenges we ran into
One of the biggest challenges we initially ran into was how to get the data transmitted from the headband’s sensor to the alienware laptop that we were using. It turns out that the headband (Muse) was unable to communicate with it directly, thus we had to set up an intermediary laptop to collect the data and then transmit it to the alienware laptop.
Initially we wanted to pull up a random song from the internet, but real time song analysis of the timbre and no pre-existing data for the RL were limiting factors that prevented us from incorporating that feature. We finally managed to scrape audio feature data for about ~700 songs.
During the course of programming the RL feature of Museic, we initially came across the challenge of designing a continuous state & action space for the program owing to the continuous sound characteristics data – valence, energy & speechiness. However, we figured out a way to utilize a policy gradient approach to tackle this challenge.
It was difficult to train the algorithm for a sufficient period of time due to the low battery life of the headband. As a result
Accomplishments that we're proud of
We were really pleased about being able to incorporate two sets of input data – the Muse and the Chatbot to train our RL algorithm, as this made it more reliable and flexible. It also meant that we could re-confirm our results and be even more confident in our system.
We also figured out a way to synchronize the collection of the response from the chatbot with the collection of the streamed EEG data. We also managed to figure out a way to define the reward for our algorithm by calculating the distance in the vector space for both our input and output.
What we learned
The brain is nOIsY. We had to smooth the data over several timesteps to ensure that it atleast somewhat represented the user’s state of mind across a given interval of time.
We not only learnt a lot about technical skills in the process of building of building the entire system we learnt a lot about debugging hardware issues, ensuring the flow of information from the sensor wasn’t interrupted until it was outputted to the user as a song change. We also learn how to implement RL algorithms, especially extending them beyond discrete actions spaces into the continuous.
What's next for Museic
Currently, Museic relies on a database of 700 songs to pull relevant information and suggest which song should be played next to reach the desired mood. In the future Museic would be able full any song from the web to provide a much more engaging and varied experienced. Ultimately it would be able to not only better detect the wide range of the current moods but also expand the range of final states (or moods) that the user wants to be in.
We would like to extend our implementation of the algorithm to be able to train on the final states for the different moods a user would like to be in. As of now, we have a discrete set of states for which we defined the activity vector. However, receiving user feedback to determine whether they have reached their desired final state would allow for a wider range of moods and improved customization.
We would also like to train a deeper model for longer to achieve more accurate results. Lastly, we would like to design a cleaner interface (instead of the current CLI) that would make it an easy-to-use application.
Built With
- ibm-watson
- muse-lab
- python
- spotify-apis


Log in or sign up for Devpost to join the conversation.