Inspiration
Synesthesia is a neurological condition where stimulation of one sense automatically triggers another
- Synesthetes might hear colors, see sounds, or taste shapes.
For an AI that genuinely processes multiple modalities simultaneously, this should be native behavior.
MUSE (Multimodal Synesthetic Experience Engine) asks: what if AI could experience the world the way a synesthete does? Instead of describing a painting, MUSE hears it. Instead of transcribing a melody, MUSE sees it. And it generates visual art from those cross-modal translations in real time, without being asked.
What it does
MUSE is a real-time AI synesthesia engine with four creative modes:
- Visual Mode: Show MUSE a painting, photo, or scene — it describes what it "hears" in the colors and composition, then generates synesthetic art
- Audio Mode: Hum or play music — MUSE describes the visual landscape the sound evokes, then paints it
- Environment Mode: Walk through spaces — MUSE narrates the journey and generates illustrated "postcards" of remarkable moments
- Sketch Mode: Show a hand drawing — MUSE recognizes the creative intent and generates a refined synesthetic illustration
MUSE speaks its interpretations in real-time via native audio and generates images spontaneously — without being asked.
How we built it
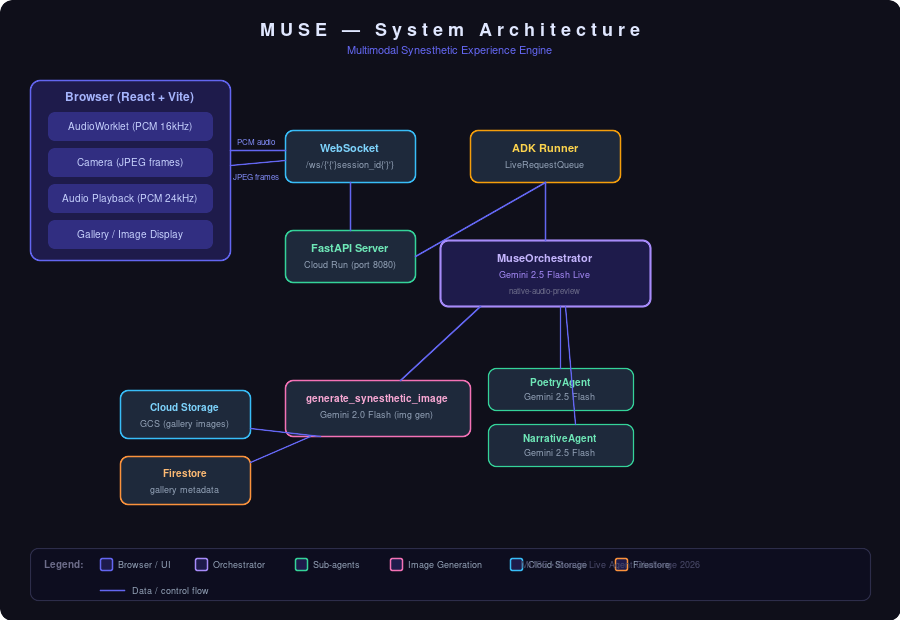
Stack: React + Vite (frontend) → WebSocket → FastAPI + uvicorn (backend) → Google ADK → Gemini
The browser captures microphone audio (16kHz PCM via AudioWorklet) and camera frames (1fps JPEG), sending them over a single WebSocket as binary + JSON frames. The FastAPI server feeds these into an ADK LiveRequestQueue. An ADK Runner orchestrates a multi-agent system:
- MuseOrchestrator: Root streaming agent using gemini-2.5-flash-native-audio-preview — proactive creative personality with a generate_synesthetic_image tool
- PoetryAgent: Sub-agent for structured poem generation from sensory descriptions
- NarrativeAgent: Sub-agent for building ongoing environment journey narratives
The key insight: image generation is a tool called by the streaming orchestrator, not a separate session. MUSE keeps talking while the image generates, then describes the result when it arrives.
Deployed on Google Cloud Run with Cloud Storage for images and Firestore for session metadata. Cloud Build automates deployment via cloudbuild.yaml.
Challenges we ran into
- Async session creation: ADK create_session() is a coroutine but wasn't obviously documented — caused pydantic validation errors until we added await
- React StrictMode double-mount: Caused duplicate WebSocket connections and duplicate greeting messages — fixed with dedup logic in transcript state
- Image data through ADK event stream: Had to parse part.function_response.response to extract base64 image data from tool results
- Bidirectional streaming: Keeping live audio flowing while async image generation completes required asyncio.gather() task management
Accomplishments that we're proud of
- Full real-time bidirectional voice + camera + image generation in one seamless session
- Proactive AI behavior — MUSE initiates art creation without being asked, embodying the synesthesia concept
- Clean multi-agent ADK architecture: streaming orchestrator + specialized sub-agents + function tools
What we learned
The Gemini Live API + ADK combination makes it possible to build agents that act rather than just respond. Synesthesia as a design paradigm forces genuine multimodal integration — you cannot fake it with sequential API calls.
What's next for MUSE
- Gallery persistence and session history with Cloud Firestore
- Collaborative mode: multiple users sharing a synesthetic session
- Mobile app for environment journeys
- Real-time sketch canvas integration
Built With
- audioworklet
- cloud
- cloud-storage
- fastapi
- firestore
- gemini-2.0-flash-image-generation
- gemini-2.5-flash-native-audio
- google-adk
- google-cloud-run
- python
- react
- tailwind-css
- typescript
- vite
- websocket



Log in or sign up for Devpost to join the conversation.