-

NLP generated context from de-noised audio transcription
-

video search option for default pre-loaded videos in app
-
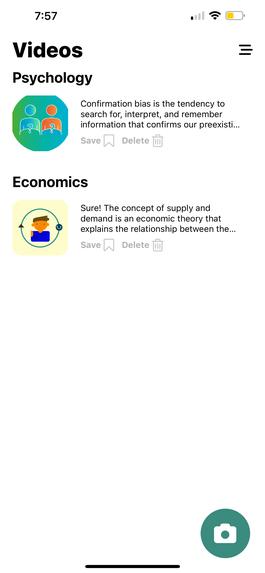
NLP generated context from de-noised audio transcription



Inspiration
When attending crowded lectures or tutorials, it's fairly difficult to discern content from other ambient noise. What if a streamlined pipeline existed to isolate and amplify vocal audio while transcribing text from audio, and providing general context in the form of images? Is there any way to use this technology to minimize access to education? These were the questions we asked ourselves when deciding the scope of our project.
The Stack
Front-end : react-native
Back-end : python, flask, sqlalchemy, sqlite
AI + Pipelining Tech : OpenAI, google-speech-recognition, scipy, asteroid, RNNs, NLP
What it does
We built a mobile app which allows users to record video and applies an AI-powered audio processing pipeline.
Primary use case: Hard of hearing aid which:
- Isolates + amplifies sound from a recorded video (pre-trained RNN model)
- Transcribes text from isolated audio (google-speech-recognition)
- Generates NLP context from transcription (NLP model)
- Generates an associated image to topic being discussed (OpenAI API)
How we built it
- Frameworked UI on Figma
- Started building UI using react-native
- Researched models for implementation
- Implemented neural networks and APIs
- Testing, Testing, Testing
Challenges we ran into
Choosing the optimal model for each processing step required careful planning. Algorithim design was also important as responses had to be sent back to the mobile device as fast as possible to improve app usability.
Accomplishments that we're proud of + What we learned
- Very high accuracy achieved for transcription, NLP context, and .wav isolation
- Efficient UI development
- Effective use of each tem member's strengths
What's next for murmr
- Improve AI pipeline processing, modifying algorithms to decreasing computation time
- Include multi-processing to return content faster
- Integrate user-interviews to improve usability + generally focus more on usability
Built With
- asteroid
- ffmpeg
- flask
- google-speech-recognition
- librosa
- natural-language-processing
- openai
- pca
- pydub
- python
- react-native
- rnn
- scipy
- speech-recognition
- sqlalchemy
- sqlite






Log in or sign up for Devpost to join the conversation.