-
-

Muntjac — self-healing observability agent. Detect, diagnose, repair, and audit incidents in under 6 seconds via Splunk MCP + Gemini.
-
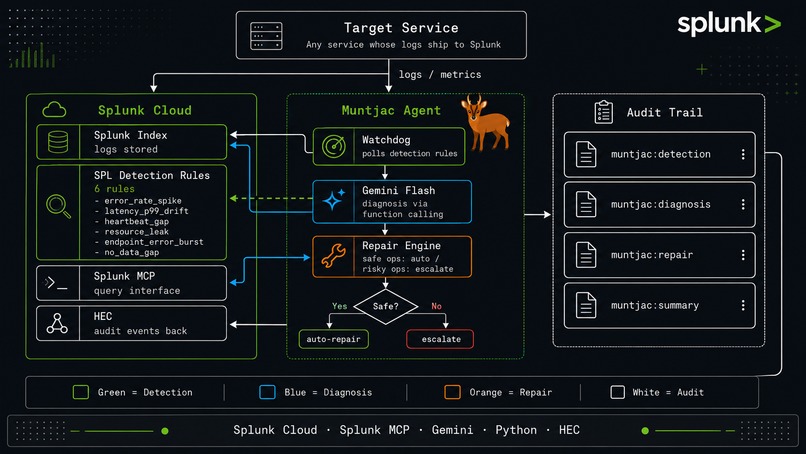
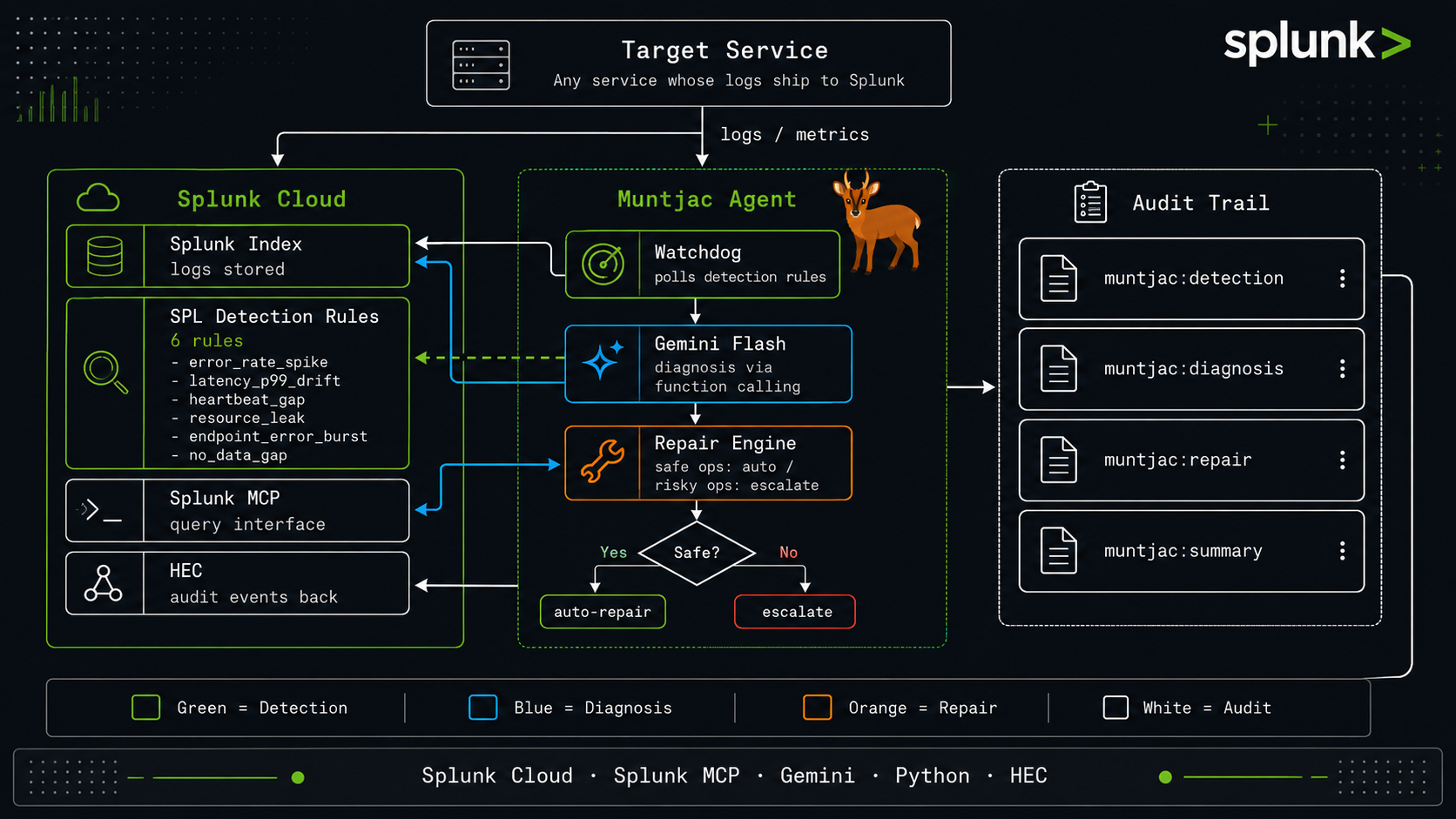
Watchdog polls 6 SPL rules → Gemini diagnoses via Splunk MCP → bounded repair (safe: auto, risky: escalate) → audit back to Splunk.
-
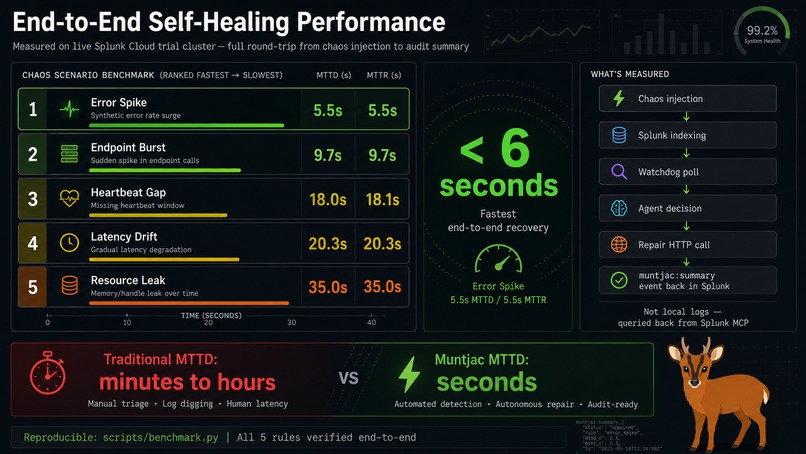
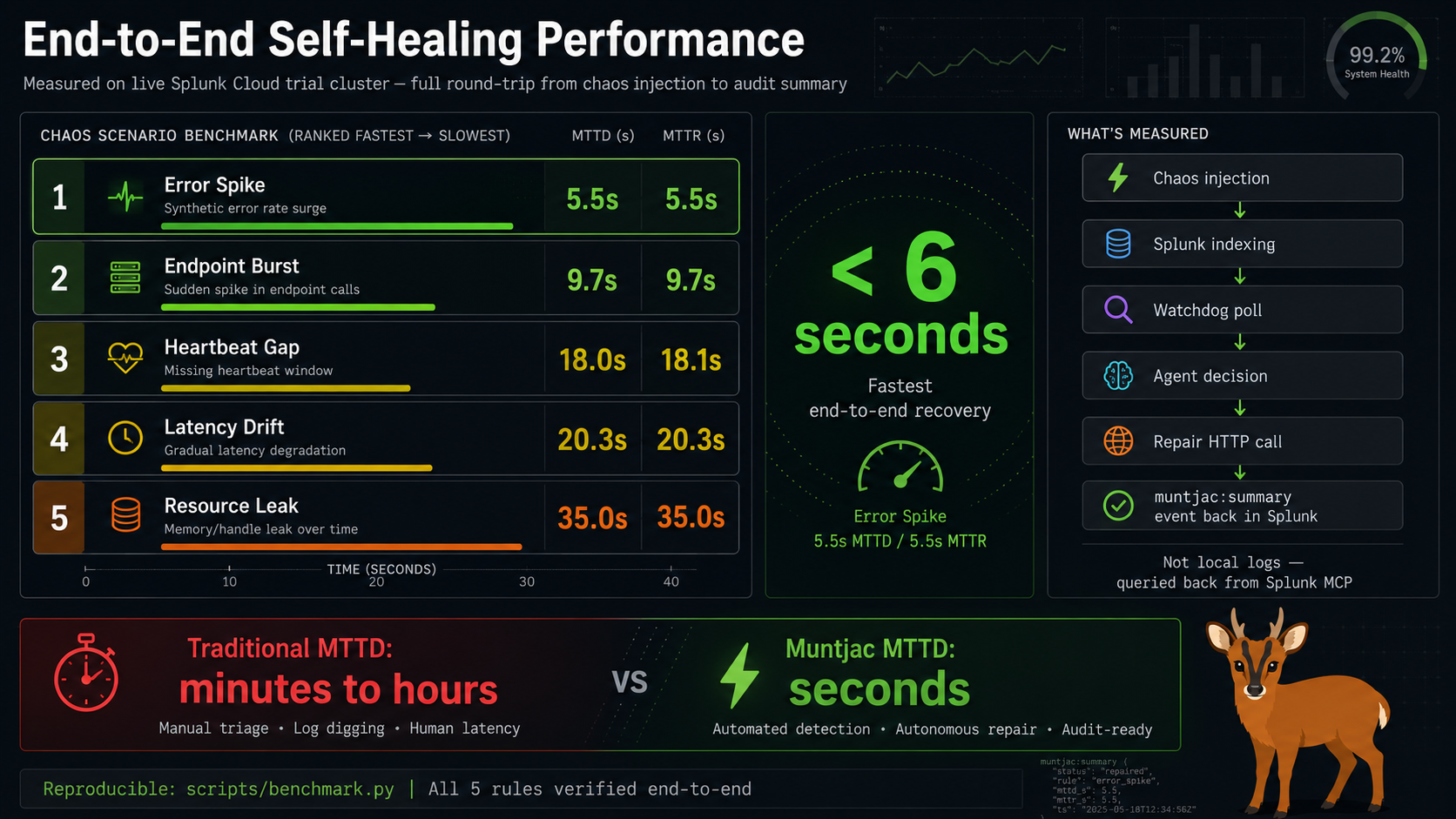
error spike recovered in 5.5s. All 5 chaos scenarios verified. Traditional MTTD: hours. Muntjac: seconds.

Inspiration
At 3 AM, the same five symptoms wake the same on-call engineers to run the same five SPL queries. Splunk already has all the data — what's missing is an agent that knows the playbook and is allowed to execute it.
What it does
Muntjac is a self-healing observability framework. It continuously polls Splunk for anomalies (error spikes, latency drift, heartbeat gaps, memory leaks, silent failures), dispatches an AI agent that diagnoses root cause via Splunk MCP Server, executes bounded repairs (safe actions auto-run; risky ones await approval), and writes the full audit trail back to Splunk — all queryable with a single stats command.
How we built it
- Splunk Cloud Platform as the log backbone
- Splunk MCP Server (Splunkbase 7931) as the AI-readable interface to Splunk data
- Python watchdog polling 6 SPL detection rules covering multi-layer failure modes
- AI agent (Claude CLI / Gemini CLI) connected to Splunk MCP via
mcp-remotebridge - ACTION_ROUTES table enforcing safety boundaries at the dispatcher level — not relying on LLM judgment
- Splunk HEC for writing
muntjac:detection,muntjac:diagnosis,muntjac:repair, andmuntjac:summaryevents back to Splunk
Challenges we ran into
- Silent field-name mismatch: HEC wrote
event=but detection rules searchedmsg=, causing 3 of 6 rules to silently never fire. Only caught by comparing raw_rawfield names. Action vocabulary drift: The LLM invented non-existent action names. Fixed by making
ACTION_ROUTESthe single source of truth for both the diagnosis prompt and the repair dispatcher.HEC backpressure under chaos injection: Solved with 1/5 sampling for routine traffic and a 10,000-event queue depth.
Accomplishments that we're proud of
- 5/5 chaos scenarios pass e2e on a live Splunk Cloud trial cluster, with audit events verified by querying back through Splunk MCP
- Safety boundaries enforced by code (
ACTION_ROUTES), not by hoping the LLM behaves correctly - Fastest full loop (chaos → detect → diagnose → repair → audit in Splunk): 5.5 seconds
What we learned
Splunk MCP Server turns Splunk from a "human reads dashboards" tool into an "AI queries and acts" platform. The hardest bugs were silent ones — field mismatches that made everything look fine while half the detection rules were dead.
What's next for Muntjac
- Multi-tenant support with per-team safety policies
- Feedback loop: agent learns from past incident resolutions stored in Splunk
- Integration with Splunk SOAR for enterprise approval workflows

Log in or sign up for Devpost to join the conversation.