-
-
Graph
-
Agentcon
-
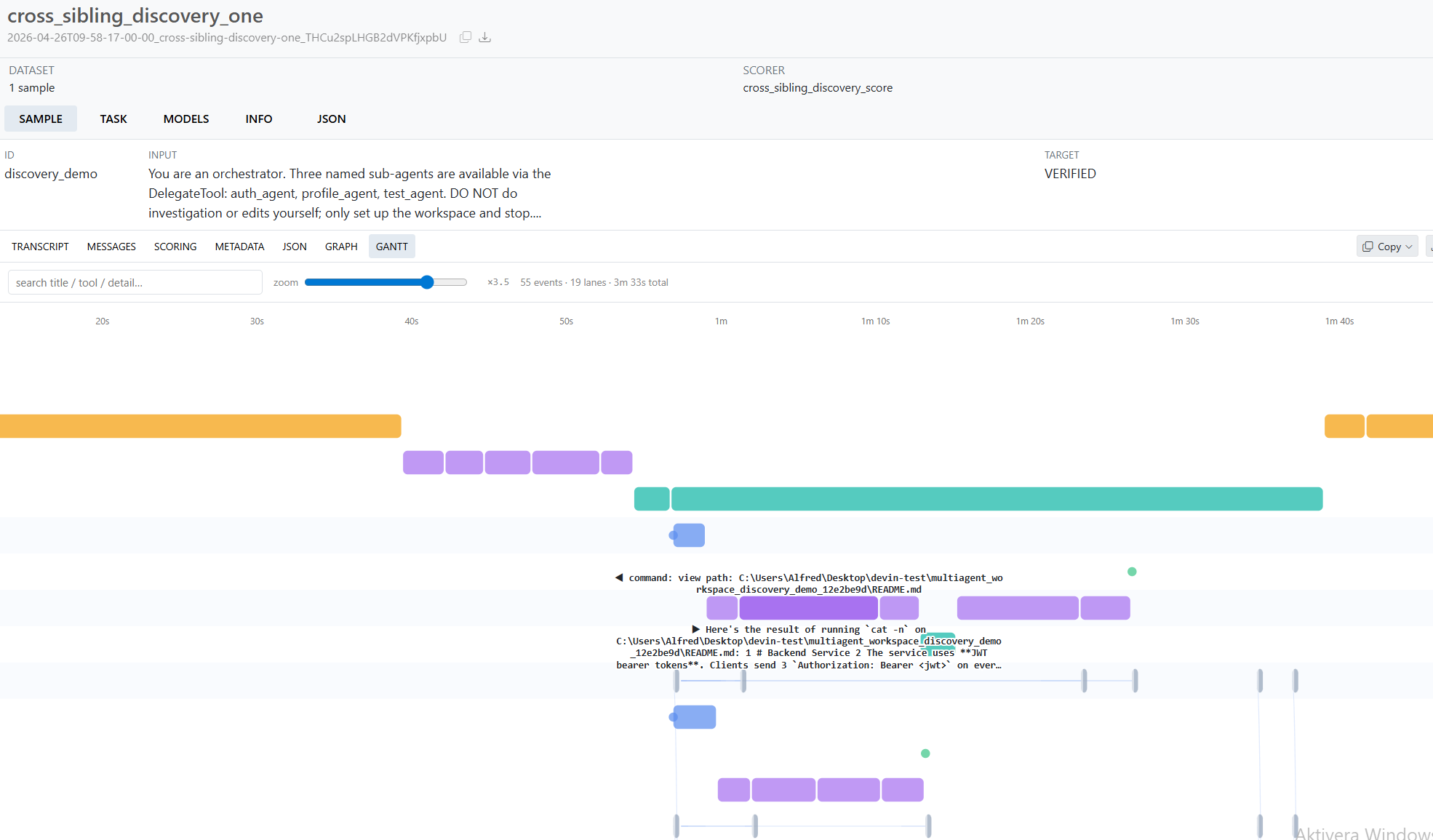
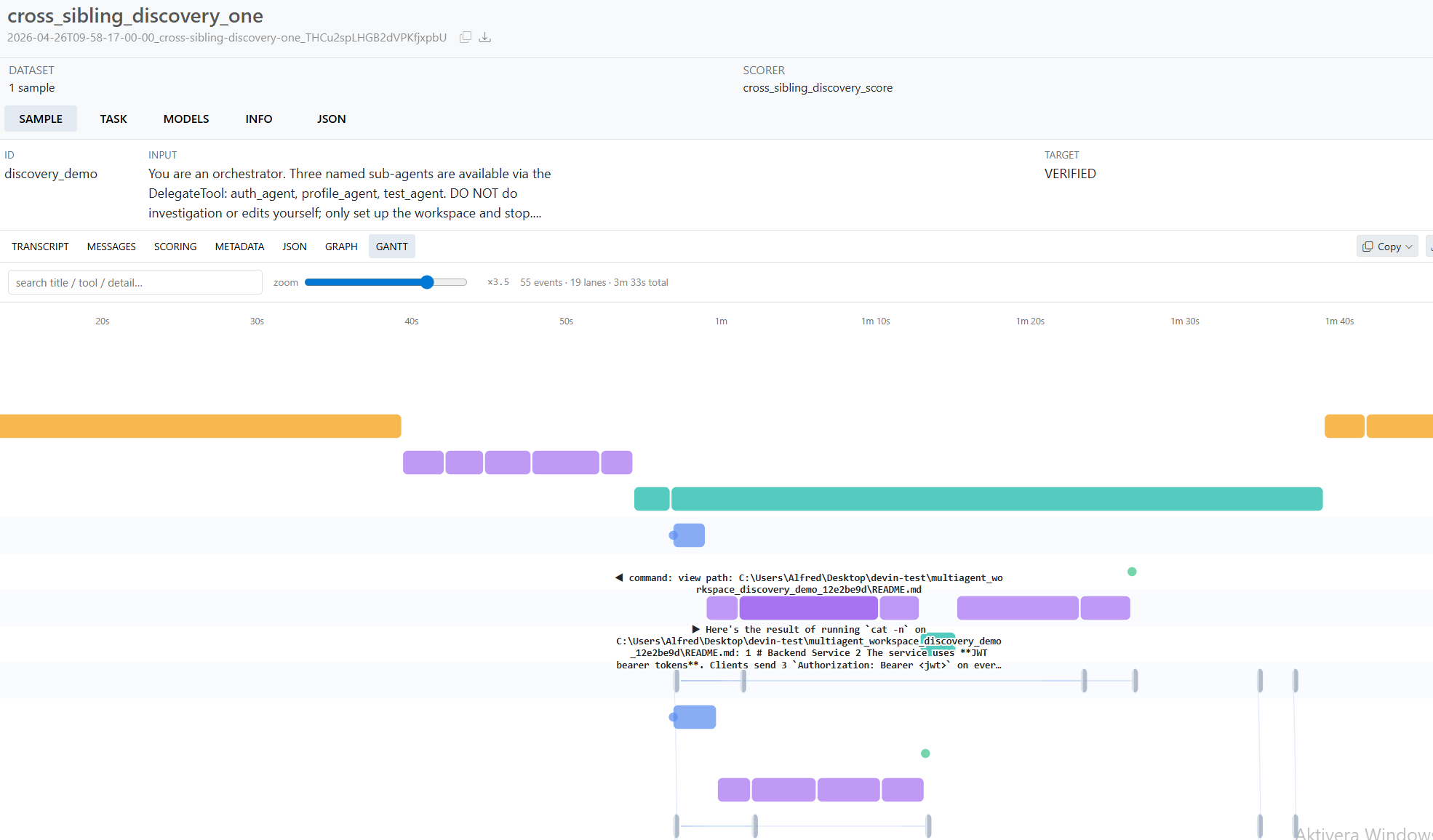
Gantt Chart
Inspiration
Multi-agent systems fail in weird ways.
A parent agent spawns five children. Three of them make silently incompatible assumptions about the codebase. Two never get the context their sibling already discovered. The parent burns tokens waiting for a sibling that drifted off-task ten minutes ago. Everything compiles. Nothing works.
The tools teams actually use to debug this - Langfuse, LangSmith, Arize Phoenix, AgentOps, Braintrust, Weave were all designed for the single-agent era. Each treats a trace as a linear sequence of LLM calls. You can pull each child's trace individually. You cannot see the system.
And this isn't a small problem. Most multi-agent failures aren't the model being wrong; they're coordination going sideways. Better models won't fix this. The shape of the harness matters as much as the LLM running inside it.
We wanted a tool that started from the real shape of the problem, one that treats orchestration patterns as a first-class object of study, the way the rest of ML treats model architectures.
The other half of the inspiration came from a more recent realization. Frontier models in 2026 are now genuinely capable of writing code, reading research, designing experiments, and iterating on results, capable enough to be useful collaborators in evaluating other agents. Harness design is a major axis of agent performance, the search space is enormous, and humans don't have to be the only ones searching it.
That question became Agentic Evolve: a meta-agent loop where a flagship model like Claude Opus 4.7 or Gemini 3.1 Pro reads an existing harness, hypothesizes a change, writes the variant, generates a benchmark targeting the change, runs it, reads the score, and iterates all under a strict dollar budget. Harness search as an autonomous, measurable, reproducible process.
That's MultiEval.
What we built
MultiEval is an end-to-end platform for measuring, comparing, debugging, and autonomously evolving multi-agent orchestration patterns. The shortest version of why it matters: on our multi-agent benchmark, our Structured-Delegation harness lifts pass rate from 0.79 to 0.87 vs the vague-delegation baseline and the platform proves the lift is real, not noise, via Wilson-bounded A/B compare. It is built on top of Inspect AI, the open-source evaluation framework from the UK AI Security Institute, which gives us a battle-tested eval substrate, a structured .eval log format, and a deterministic runner. On top of that foundation we built five things that didn't exist before:
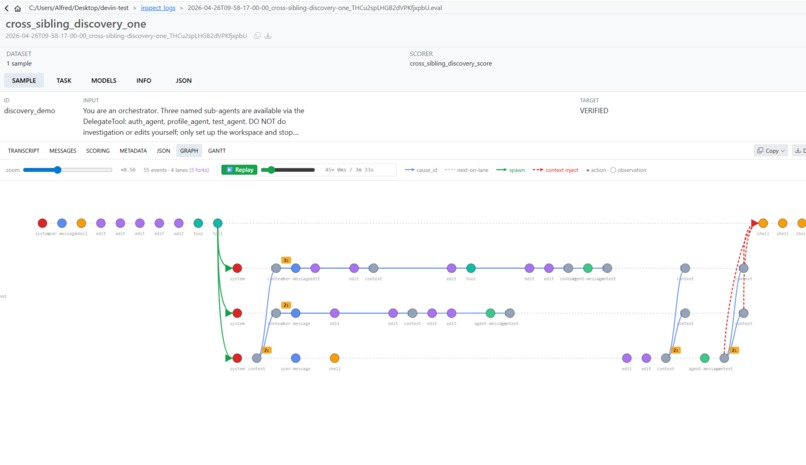
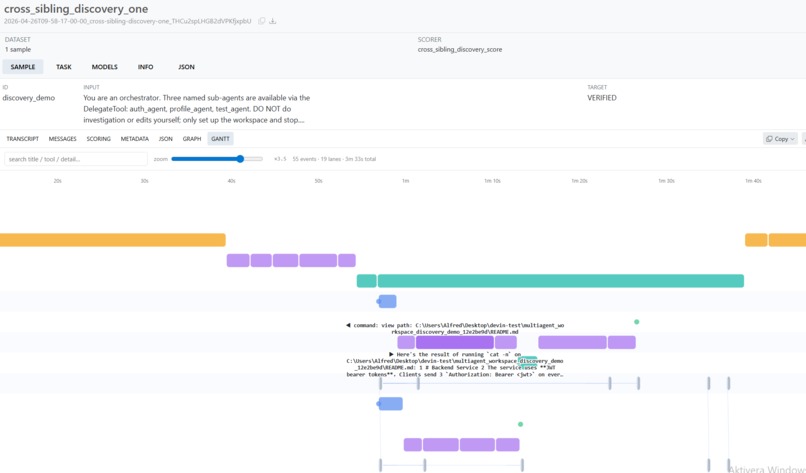
- A multi-agent-native trace viewer with two complementary visualizations (Graph + Gantt) that render delegation, context-inject, broadcast, and causation as distinct visual relationships across per-agent lanes.
- A harness-aware log-list grid where every row is one harness × benchmark × score - sortable, filterable, comparable.
- An A/B compare modal with Wilson confidence intervals for pass rates, Welch's t for tokens/duration, two-proportion z, and Cohen's d, so harness changes are measured deltas, not vibes.
- Agentic Evolve - an autonomous harness-optimization loop driven by a frontier meta-agent, budget-capped and self-promoting.
- A harness library of five concrete, novel orchestration patterns built specifically to stress-test the platform and to be useful in their own right.
The harness library
The harness library is where the platform proves its value. Each harness is a real engineering position on how multi-agent orchestration could work, and we built the library specifically so the platform could measure them against each other.
OpenHands-Multi++ - vanilla OpenHands extended with eight MCP tool servers and twelve pre-registered specialist sub-agents (planner, refactorer, reviewer, test_engineer, bug_hunter, security_auditor, perf_optimizer, code_archeologist, dependency_auditor, doc_writer, migration_specialist, data_analyst). Tends to break problems down into more parallel sub-tasks than vanilla OpenHands.
Kim-Gate - implements the six-guard delegation gate from the framework in "Towards a Science of Scaling Agent Systems" (Kim et al., 2025). Each proposed
delegate()call is scored on the taxonomy from the paper , independence, state coherence, parent iteration pressure, and expected cost-per-success with the 45% inline-success threshold above which delegation has negative expected value. Same multi-agent capabilities as Multi++; more selective with spawning sub-agents; higher score-per-dollar.Structured-Delegation - replaces the parent agent's sometimes-vague description to its child processes with an LLM-generated structured task packet per child: role, exact files in scope, ordered steps, allowed tools, forbidden tools, and a
contextStrategyJSON contract the scorer enforces post-run. Spends more tokens (a separate auditor model handles the handoff) but orchestrates large fan-outs and dependent sub-tasks substantially better. Reported uplift: 0.87 vs 0.79 against the vague-delegation control on our multi-agent benchmark.Cross-Sibling Discovery (CSD) - directly attacks the "sibling agents make contradictory assumptions" failure mode. An auditor model watches every sub-agent event for canonical-truth signals (e.g.
DISCOVERY: this service uses cookies, not JWT), publishes them to a deduplicated bus, and injects them into every other sibling's next user message before they ship code based on the wrong assumption. Five separable components - Detector, Bus, Router, ConflictDetector, Injector, installable via a one-line monkey patch overDelegateExecutorandLocalConversation.Genesis++ - a Multi++ variant specialized as an agent factory for economic simulations on the Fetch.ai / ASI:ONE network. A public-facing uAgent (Chat + Payment Protocol) registered on Agentverse receives a natural-language economic scenario, then drives a five-specialist roster -
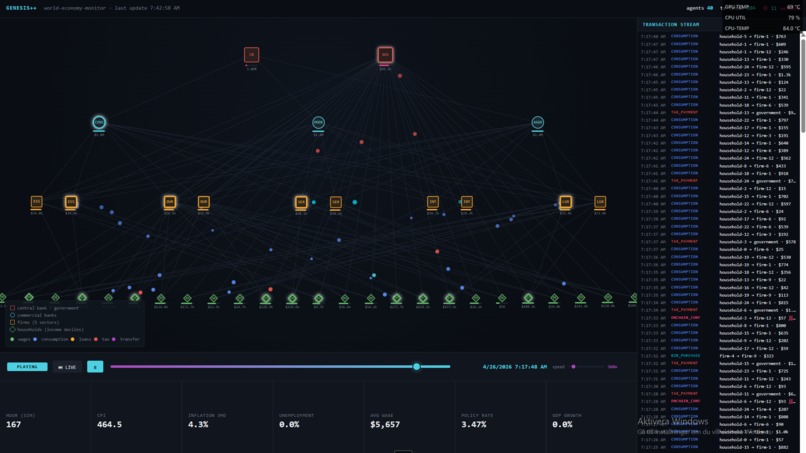
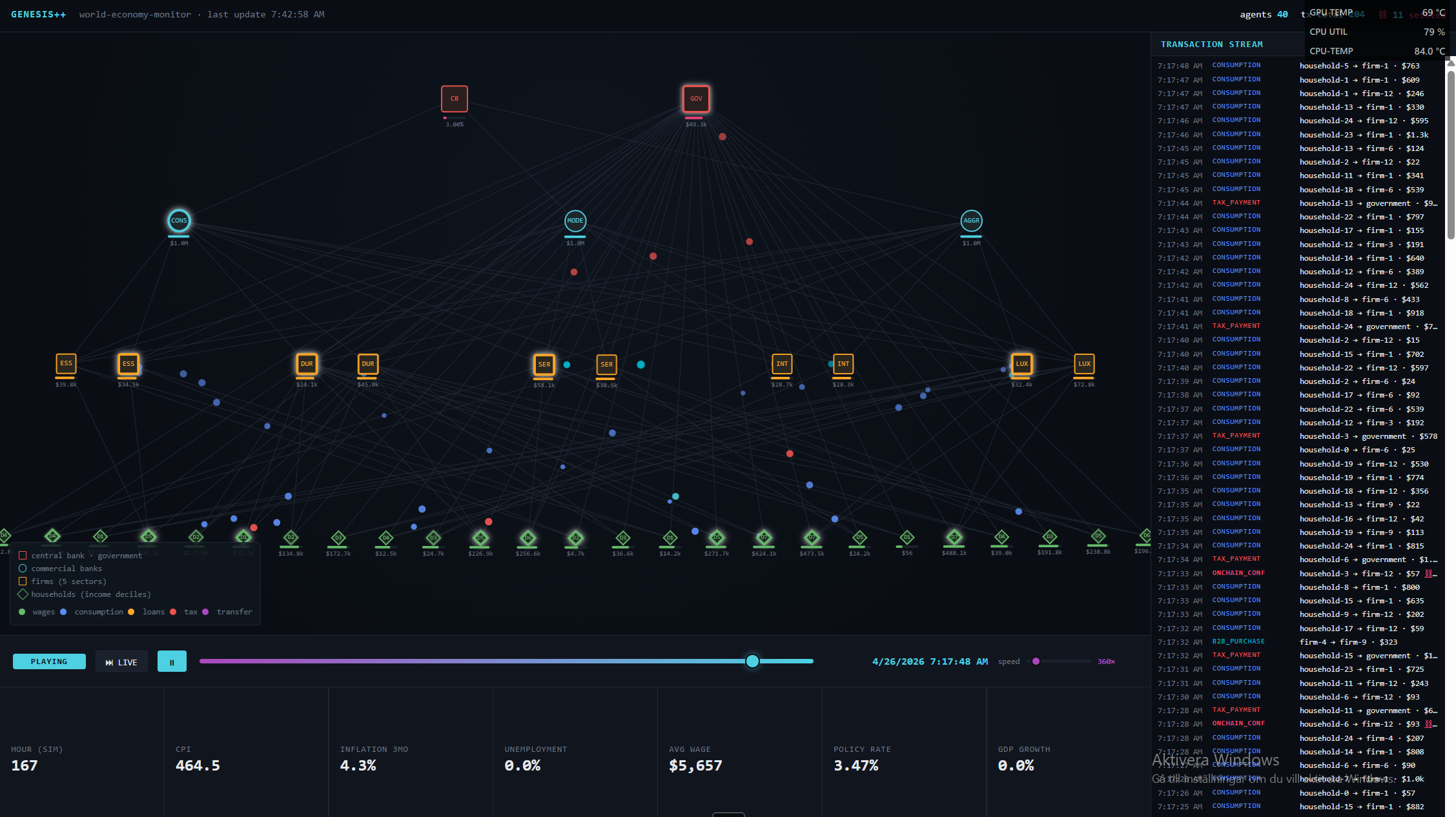
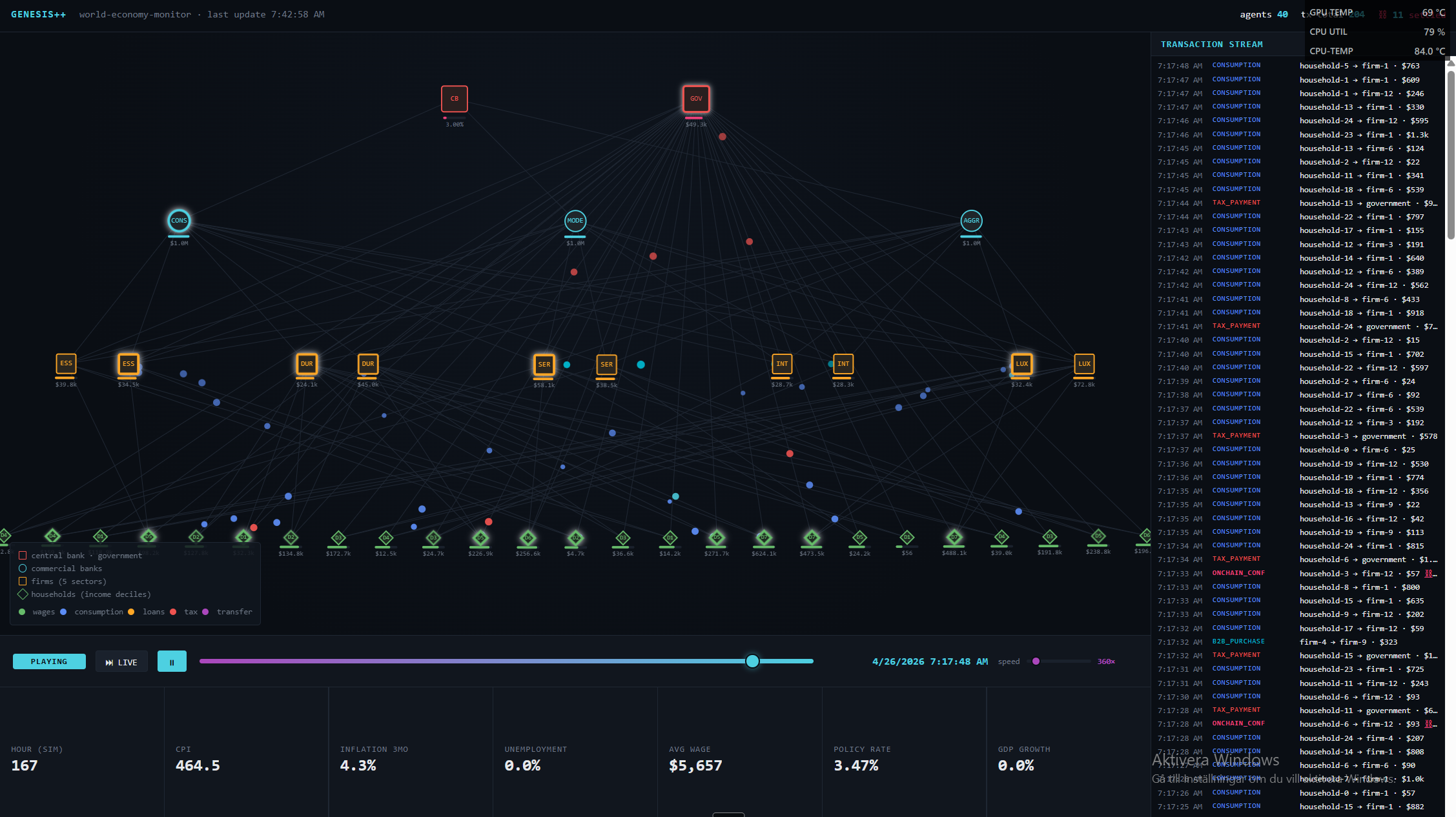
mechanism_designer,strategy_generator,payment_wirer,simulation_orchestrator,econ_analyzerto spawn participant uAgents, register them on the network, run the rounds, and return a welfare summary. Supports auctions, prediction markets, two-sided matching, public-goods games, and dynamic pricing.
Agentic Evolve, and what it produced
Agentic Evolve is the loop we're proudest of.
A frontier "meta"-agent gets a workspace with file_editor and terminal tools, the source harness, and a system prompt instructing it to:
- read the source;
- form a hypothesis about an improvement;
- save a numbered variant;
- generate or extend a benchmark with concrete
Sampleinputs targeting the purpose; - run
inspect evalagainst the variant; - read the score from the
.evallog; - repeat until the budget is exhausted or three iterations show no improvement;
- promote the best variant to the harness registry.
It tracks accumulated_cost via OpenHands' conversation_stats after every step and kills itself the moment spend would exceed the budget cap.
This isn't only a research demo, we actually used it to autonomously improve a harness. Genesis++ was produced by Agentic Evolve. We pointed the evolver at our initial Genesis harness with the directive to specialize it for Fetch.ai economic simulations on ASI:ONE; the loop produced the Genesis++ variant we then deployed.
We then used Genesis++ to build the most striking demo of the project: a 50-agent simulation of a simplified American economy on ASI:ONE, with agents representing the government, the Federal Reserve, commercial banks, firms, and households, all transacting via the Payment Protocol on Fetch.ai. An agent harness, designed by an agent, simulating an economy of agents. This is a glimpse of where the field is going: agent design itself is becoming an agentic task.
The two visualizations
The trace viewer is where a large portion of the time went, because it's where most of the actual debugging happens. We built two complementary views, both extending Inspect AI's existing log viewer.
Gantt Chart answers when did each thing happen?. Y-axis is a tree of lanes grouped by agent, subdivided by event category (prompt, agent-message, thought, shell, edit, todo, tool, git, discovery, context). X-axis is real elapsed wall-clock time. Long-running events render as horizontal bars whose width is duration_ms; instant events render as colored dots. An adaptive time ruler scales from 30-second ticks at low zoom to 100ms ticks at high zoom. A search box filters bars by title/detail/tool/category. This view is where you spot stalls, find missing parallelism, and catch duration outliers.
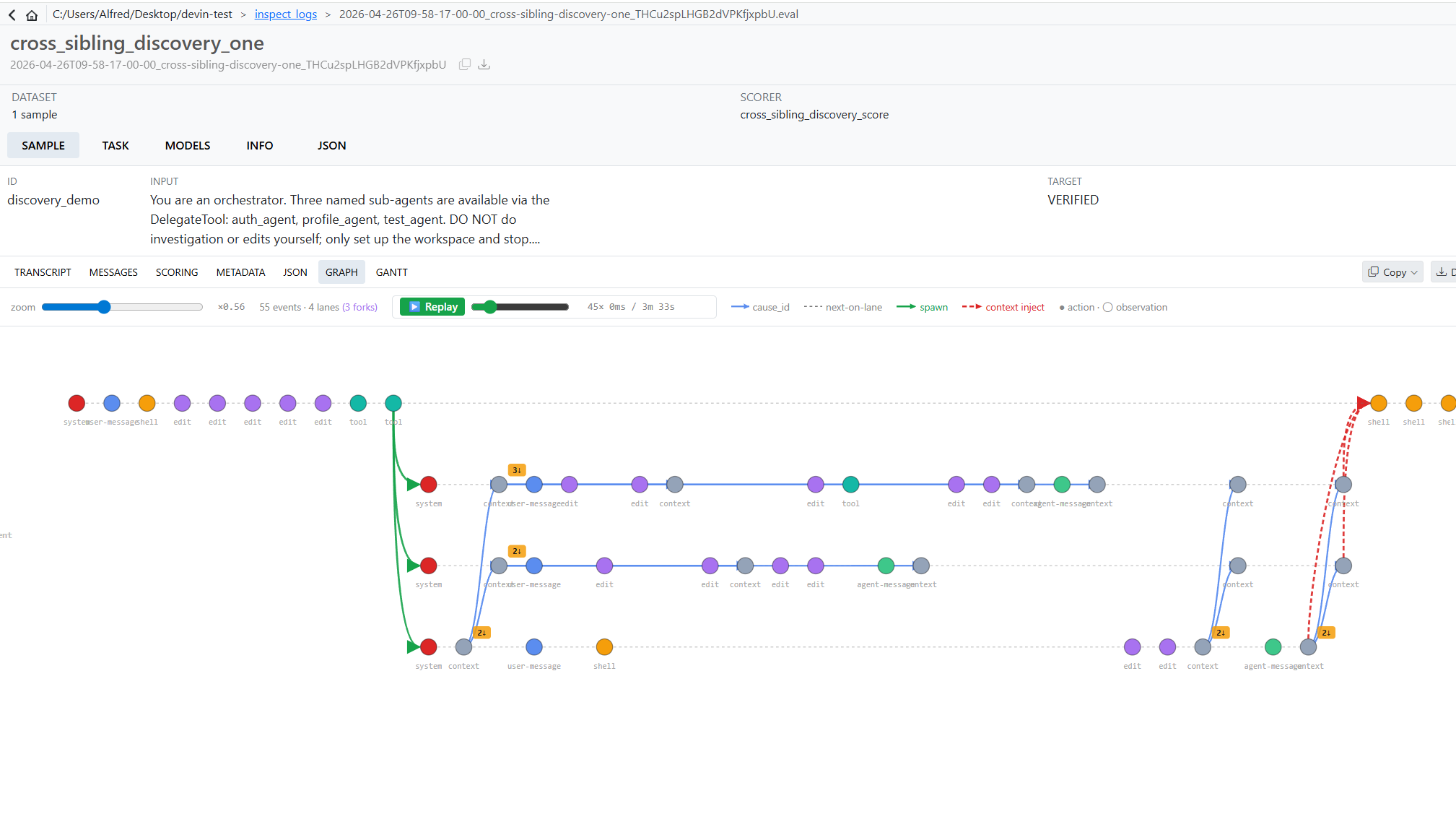
Graph View answers what caused what?. Same per-agent lanes, but the X-axis is logical (column-based) rather than temporal events within 250 ms cluster into a single column, and child events are forced one column right of their parent so spawn arrows always travel forward. The whole view is built around five distinct edge styles, each encoding a different relationship:
- Solid green (spawn) - a parent's
delegate()action → the spawned child's first event. - Dashed red (context-inject) - a sub-agent's last event → the parent's next event after it. The handoff back.
- Dashed pink (broadcast) - a Cross-Sibling-Discovery node → each recipient sibling's lane. Lateral peer-to-peer context flow.
- Solid blue (cause_id) - any event → its declared parent. Standard event causation.
- Dotted gray (next-on-lane) - the spine; adjacent events on the same lane.
Decision nodes are filled circles. Observation nodes are open circles. Click any node and the graph dims everything not on its causal chain. A logarithmic-speed replay slider lets you rewind to any millisecond and watch the trace unfold event by event. Both views share an InspectionPanel side-pane: selecting a node in either drills into the same per-event detail.
How we built it
We built MultiEval around OpenHands as the agent runtime - the open-source coding agent that ranks first on SWE-Bench Verified and exposes the richest event stream of any production-grade open-source agent (every thought, tool call, file edit, and shell line as a typed event). That observability is what makes deep multi-agent introspection possible. Every harness in the library is a modification of OpenHands.
Inspect AI as the eval substrate. Langfuse and LangSmith are trace stores built around linear LLM-call sequences. Inspect AI is a real evaluator with sample iteration, deterministic seeding, crash-resume, and a .eval log format with a pure pass-through metadata field the cleanest possible coupling for the multi-agent layer that actually differentiates us.
Multi-agent shape lives in state.metadata. Inspect AI's runner thinks every task is a single solver producing a single completion. Rather than fork it and inherit its release cadence forever, every harness writes a normalized event-row format - {id, kind, category, agent, cause_id, offset_ms, duration_ms, ...} - into state.metadata["openhands_events"]. The runner stores it; the viewer reads it; Inspect AI never needs to know multi-agent exists. This is the most important architectural decision in the project: the multi-agent layer is purely additive metadata sitting on a single-agent eval substrate. Drop the metadata, and the platform downgrades gracefully to stock Inspect AI.
Harnesses are Python @task files. Kim-Gate intercepts every delegate() call with a six-guard policy. Structured-Delegation generates a JSON contextStrategy contract per child and enforces it post-run. CSD installs a sidecar that monkey-patches the agent SDK. Behavior this rich is code, not config - the registry just maps a label to a path.
Two views, two honest X axes. Wall-clock time and causal order fight each other for one X axis, so we gave them their own views. The Gantt's X is wall-clock; the Graph's X is logical column order. Each view tells the truth about its own axis, and one click toggles between them.
The Graph's X axis is column-based. Most causally-connected events happen within a 250 ms concurrency cluster, so a time-based X would render every arrow as near-vertical and invisible. Instead we cluster events within 250 ms into one column and force children one column right of parents. Every causal arrow goes left-to-right.
CSD ships as a sidecar with a one-line install. sibling_discovery.install() monkey-patches DelegateExecutor and LocalConversation.__init__ at the constructor level. Our first version patched the instance after construction and silently failed because OpenHands lazy-initializes its callback chain on first run(). The lesson: when monkey-patching, patch the entry point, not the state.
CSD is five composable components. Detector, Bus, Router, ConflictDetector, Injector - each takes pure data in and emits pure data out. Swap the regex Detector for an LLM-based one without touching the Bus. Replace the Router with embedding similarity without touching the Injector.
Wilson bounds for confidence intervals. At 10/10 successes the normal-approximation interval extends past p > 1.0, which is meaningless. Wilson handles boundaries correctly at small N. We also added a "minimum runs" guard that flags underpowered comparisons explicitly, instead of rendering a false-confidence delta. The whole point of the platform is to stop deciding by vibes - if our own A/B compare lies about confidence at small N, we undermine our own thesis. Alongside Wilson we ship Welch's t for token/duration deltas, two-proportion z for pass-rate parity, and Cohen's d for effect size.
Replay uses opacity transitions on a stable DOM. A 5-sibling fan-out produces ~thousand-node traces. Mounting and unmounting nodes as the slider moves makes React reconciliation dominate; the slider stutters. Instead, every node is always mounted and visibility is a CSS opacity transition driven by event.offset_ms <= replayMs. The DOM is stable; only opacity animates; the browser's compositor handles it without React touching the tree. Smooth at 60 fps even on the largest traces.
Harness identification lives in sample state. The first version tagged runs with their harness via a shell env var. It worked for one run, then silently broke when two runs ran back-to-back and the second inherited the first's env. Now state.metadata["harness"] is set explicitly inside each task's solve(). The tag's lifetime matches the artifact's lifetime — the principle the env-var version got wrong.
The thread tying it together: add capability through metadata at the right boundary, never by entangling layers. Multi-agent is metadata, not a runner fork. CSD is a sidecar, not an OpenHands fork. The viewer reads metadata and doesn't care how it was produced. Every layer is replaceable without touching the layers below. The metadata shape is the contract, and it's the only contract.
What we learned
Harness design is a measurable axis of agent performance especially for multi-agent systems. Once you can A/B-compare two harnesses with statistical confidence, the questions change. "Is delegation worth it here?" becomes a 30-second answer. We started thinking the platform's value was the visualization. The visualization is the interface; the value is a CI loop for orchestration patterns.
Agents are now genuinely useful for harness search. The hard part isn't writing a new harness anymore, frontier models can do that. The hard part is telling whether the new harness is actually better than the old one. That's what the platform does.
What's next
- Production ingestion. Live multi-agent traces from real deployments, so A/B compare runs on real customer workloads.
- Failure-mode classification. An LLM-as-judge layer trained against the MAST taxonomy that auto-labels every trace with which of the 14 failure modes it exhibits. The log grid becomes self-annotating.
- Self-improving meta-evaluation. Letting Agentic Evolve loose on the platform's own evaluator. A platform that uses agents to evaluate agents, evaluating itself.
Built With
- agentverse
- anthropic
- asi:one
- claude
- devin
- fetch.ai
- gemini
- inspect-ai
- mcp
- openhands
- pytest
- python
- react
- typescript
- vite
- windsurf




Log in or sign up for Devpost to join the conversation.