
Inspiration
Data is an asset in this digital world, and enormous amounts of data were generated across all fields. In the healthcare industry, data refers to all patient-related data. A general architecture for disease prediction in the healthcare industry has been proposed here. One disease is the focus of many of the current models for each analysis. Examples include a diabetes analysis, a cancer analysis, and a skin disease analysis, among others. There is currently no system that can simultaneously analyze multiple diseases. As a result, our primary focus is on providing users with prompt and precise disease predictions based on the symptoms they experience and the diagnosis they are given. As a result, we propose a system that makes use of machine learning algorithms to predict a variety of diseases. We will analyze diabetes, heart disease, and Parkinson's disease in this system. Later, numerous additional diseases may be added. We are going to use machine learning algorithms and servlet to deploy multiple disease prediction systems. Python pickling is used to preserve the model's behavior. This system analysis is crucial because it allows for a more accurate and efficient disease detection by taking into account all of the disease's underlying factors. The behavior of the final model will be recorded in a Python Pickle file. A considerable lot of the current AI models for medical care examination are focusing on one infection for every investigation. The first, for instance, is used for heart analysis, the second for diabetes analysis, and so on for Parkinson's disease. Users must navigate multiple sites in order to predict multiple diseases. There is no normal framework where one investigation can perform more than one illness expectation. The lower accuracy of some of the models can have a significant impact on patients' health. When an organization wants to analyze the health reports of its patients, it must use a lot of models, which costs money and takes time. Few parameters are taken into account by some of the current systems, which can lead to inaccurate results.
What it does
Currently, if a patient shows any symptoms, he or she must see a doctor or go to the hospital to get a diagnosis for the disease. However, our primary objective is to lessen the number of efforts patients make solely to diagnose the disease. Due to the late diagnosis of their disease, many patients are losing their lives. Therefore, our primary objective is to reduce these deaths. An Multiple Disease Prediction Using Machine Learning is proposed as a solution to the aforementioned issues with the existing system. It is possible to predict multiple diseases simultaneously with multiple disease prediction. Therefore, the user does not need to travel to various locations to predict the diseases. We're looking at liver, heart, and Parkinson's diseases. because there is a connection between all three diseases. We utilized various supervised machine learning algorithms like logistic regression and SVM to carry out multiple disease analyses. Additionally, we have implemented this project using Python. Additionally, we have presented and implemented these models on the Anaconda and streamlet platforms.
How we built it
DATA COLLECTION For diabetes analysis initially Pima Indian Diabetes Dataset, the data set which was acquired from a hospital in Frankfurt, Germany is used. For diabetic retinopathy over 150 GB image data from the UCI machine learning repository are used. For heart disease analysis Cleveland, Hungarian and Switzerland heart disease patient's data sets are used. And for cancer disease prediction used Breast Cancer Wisconsin (Diagnostic) Data Set which is available in machine learning repository. In the current analysis in addition to those data sets used other live data sets by visiting corresponding hospitals. The importance of this analysis is by consulting the doctors, they collected the necessary parameters which will cause the disease and also due to that disease any other disease likely to occur. After doing this analysis there is a chance of reducing mortality ratio because if able to predict the maximum disease chances of occurring so that it can warn the patients in advance for treatment. DATA PREPROCESSING For a system to predict proper results, first, it should be trained properly with existing data. Pre-Processing the data is important so that good quality data is used for training the model. Data cleaning and removal of noise are some of the processes involved in pre-processing. We used the Diabetes Dataset (PIDD) of the UCI Machine Learning Repository. For heart disease analysis Cleveland, Hungarian, and Switzerland heart disease patient data sets are used. And for Parkinson's Data Set which is available in the machine learning repository. Data from various sources has been collected and aggregated. Now by using the preprocessing techniques Data Cleaning: Data is cleansed through processes such as filling in missing values, thus resolving the inconsistencies in the data. x Data Reduction: The analysis becomes hard when dealing with a huge database. Hence, we eliminate those independent variables(symptoms) which might have less or no impact on the target variable(disease). TRAIN AND TEST SPLIT As per industry standards, train sets and tests are prepared. By using Scikit learn train_test_split method to split the data as 70% for training and 30% for testing are divided. Example: diabetes_feature_train, diabetes_feature_test, diabetes_label_train, diabetes_label test = train_test_split (diabetes_features, diabetes_label, test_size=0.3, random_state=0) 6.4 Model Building Multiple disease prediction is a classification problem. So, we have implemented various classification algorithms like Logistic regression, SVM, and Naïve Bias Classifier to choose the algorithm with the best results. The next step is building the prediction version. First, we need training and testing of the data by using the classification algorithm then we are fitting the model and loading the model by using a pickle module... Second, by using the Python module Streamlit we are developing the user interface where the user is able to see the prediction of disease. The methodology for this project includes the collection of data, the preprocessing of the data, the split of the train and test data, the loading of the dataset for training the model, the application of logistic regression or SVM, the training of the model, prediction, and finding precision, and deployment with anaconda and streamlet.
Model building
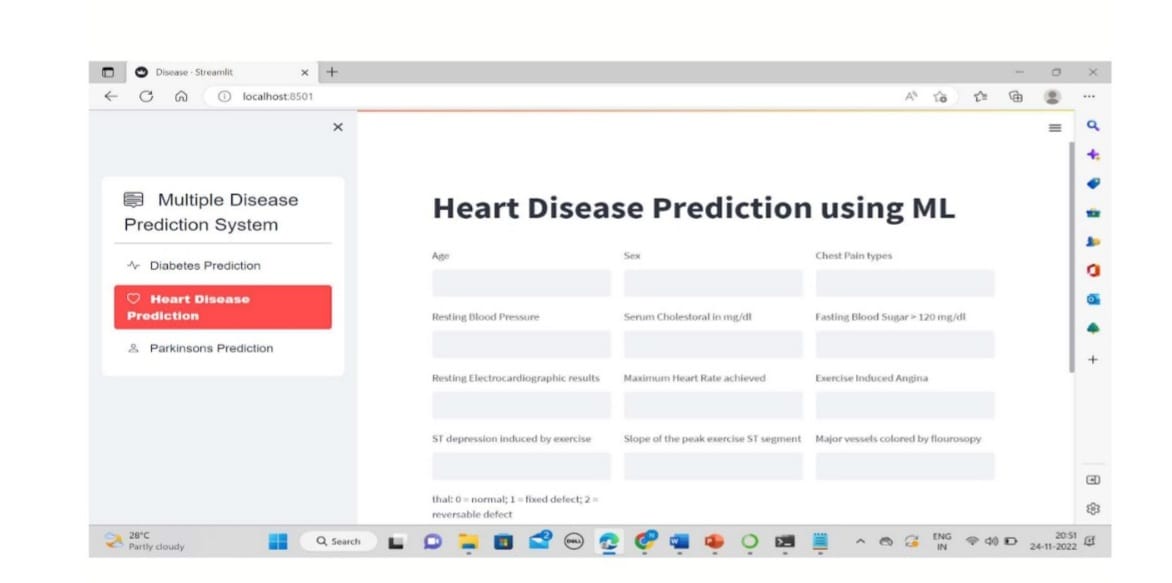
Prediction of multiple diseases is a classification problem. Therefore, in order to select the best classification method, we have implemented Logistic regression SVM and Naive Bayes classifier. The construction of the prediction version is the next step. First, we need to train and test the data with the classification algorithm. Next, we need to fit the model and load it with the pickle model. Finally, we are developing the user interface with the Python module streamlet so that the user can see the disease prediction. Models can be consumed at the front end once the streamlet is designed. The website displays an input screen about heart disease.
Conclusion
Comparatively, our proposed system achieves a high level of accuracy. In this section, we attempt to incorporate some of the healthcare-specific features of machine learning into our system. When a disease is predicted for a patient instead of a direct diagnosis, certain machine learning algorithms are used to implement measure learning. As a result, healthcare can become smarter and better. The diabetes disease prediction model used SVM, the heart disease prediction model used logistic regression, and the Parkinson's disease prediction model used SVM because they provided the best accuracy. There, when the patient adds a disease-related parameter, it will display whether or not the patient has the selected disease. If the patient input value is invalid, an error message will be displayed. We deployed this model using Streamlet. It is currently being utilized for the prediction and analysis of clinical works.ml is one of the most effective disease prediction systems in use today. ml is currently also being used for prediction and analysis, such as dealing with incorrect data in our system and identifying errors in the dataset. It is debatable whether or not the optimal application and implementation of ML algorithms can serve as a great source of assistance in the field of health care, enhancing and facilitating the work of physicians and ultimately leading to an increase in the effectiveness and quality of patient care.
What's next for Multiple disease prediction system
In this system, we are going to analyze diabetes, heart disease, and Parkinson's disease. Later, many more diseases can be included instead of direct diagnosis when a disease is predicted for a patient. Machine learning is then implemented using a variety of algorithms, and healthcare can become smarter and better. In our project, we have used logistic regression and SVM. In the future, we will be using a variety of algorithms to predict many more diseases.
Built With
- anaconda
- colab
- machine-learning
- python
- spyder
- streamlit



Log in or sign up for Devpost to join the conversation.