-
-
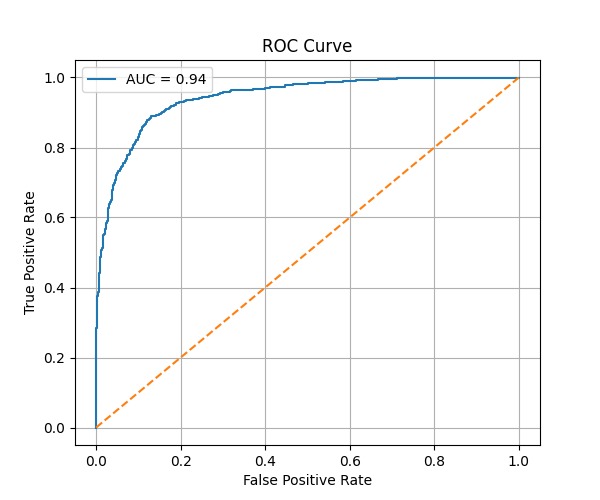
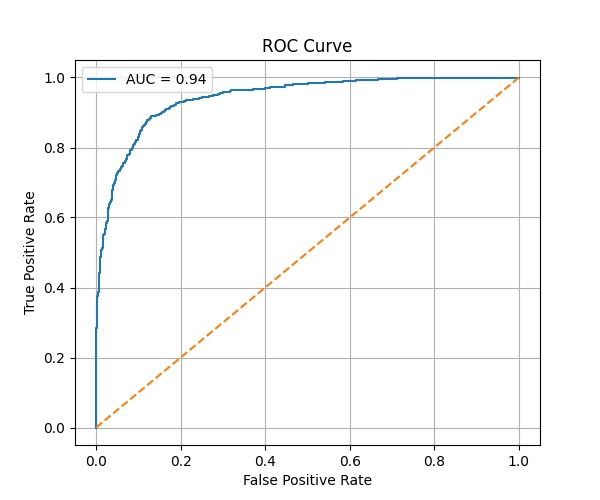
ROC Curve illustrating the model’s ability to distinguish toxic and non-toxic text.
🧠 About the Project
💡 Inspiration
With the rapid growth of online platforms and social media, the spread of toxic and harmful content has become a serious concern. Moderating such content manually is inefficient and time-consuming. This inspired us to build an AI system that can automatically detect toxic language, especially in multilingual environments like English and Hindi.
⚙️ What it does
This project classifies text into:
- 0 → Non-toxic
- 1 → Toxic
It helps identify abusive, offensive, or harmful content in user-generated text.
🏗️ How we built it
We followed a structured machine learning pipeline:
Data Preprocessing
- Lowercased text
- Removed URLs and unwanted characters
- Preserved both Hindi and English text
Feature Extraction
- Used TF-IDF Vectorization
- Captured both single words and phrases using n-grams
Model Training
- Applied Logistic Regression
- Split data into training and validation sets
Evaluation
- Used ROC-AUC as the main metric
The ROC-AUC score is calculated as:
$$ AUC = \int_{0}^{1} TPR(FPR) \, d(FPR) $$
Where:
- TPR (True Positive Rate) = $\frac{TP}{TP + FN}$
- FPR (False Positive Rate) = $\frac{FP}{FP + TN}$
📈 Results
The model achieved a ROC-AUC score of 0.94, indicating strong performance in distinguishing toxic and non-toxic text.
⚠️ Challenges we faced
- Handling multilingual text (Hindi + English)
- Dealing with encoding issues in CSV files
- Reducing false positives in classification
- Understanding and implementing evaluation metrics like ROC-AUC
📚 What we learned
- Importance of proper text preprocessing in NLP
- How TF-IDF captures textual patterns
- Difference between evaluation metrics like accuracy, F1-score, and ROC-AUC
- Building a reproducible machine learning pipeline
🚀 Future Improvements
- Use BERT or transformer-based models for better contextual understanding
- Improve handling of sarcasm and nuanced language
- Optimize model performance with hyperparameter tuning
- Deploy as a real-time API for content moderation

Log in or sign up for Devpost to join the conversation.