-
-
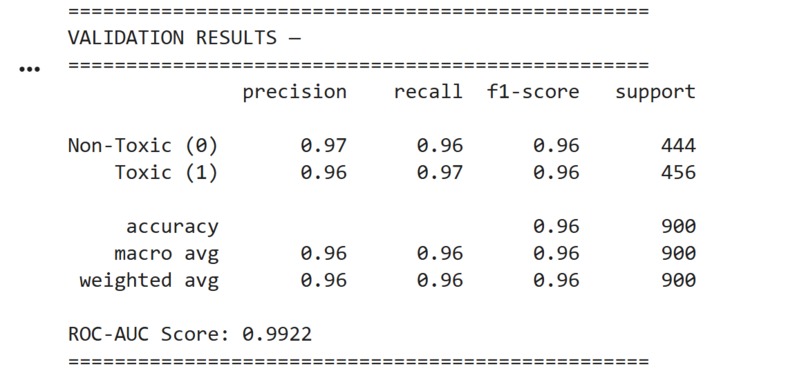
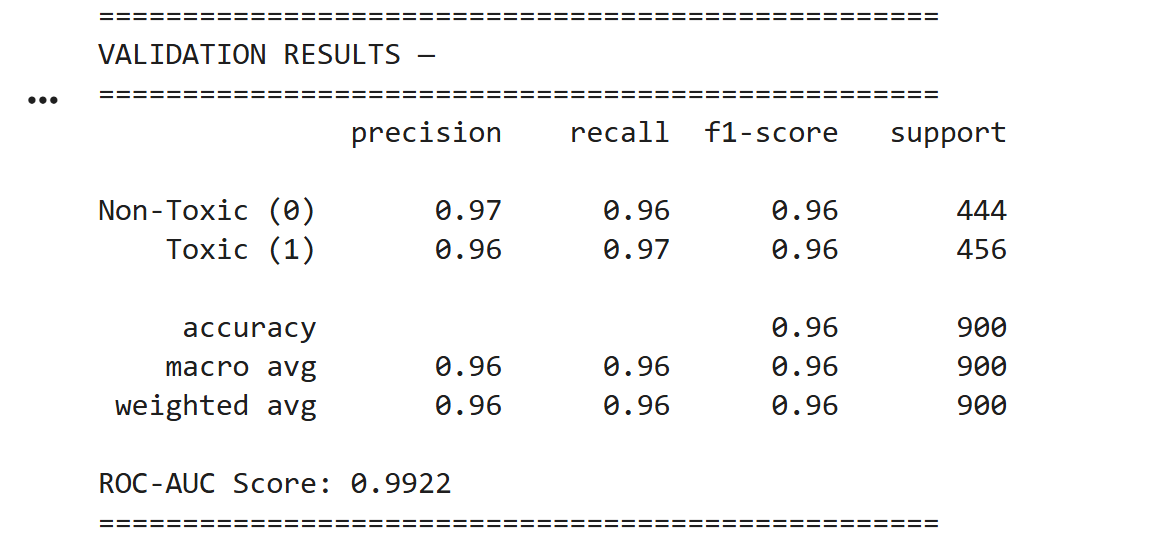
This is the screenshot of the ROC-AUC score achieved by the model which is = 99.2% and this shows the precision and accuracy of this model
-

This is the screenshot of the final validation of the model

Inspiration
Toxic content crosses language barriers — hate speech, threats, and abuse exist in every language. Building a scalable multilingual moderation system that works across Hindi and English was the core motivation for this challenge.
What I Built
A binary toxic comment classifier using XLM-RoBERTa-base — a cross-lingual transformer model supporting 100 languages — fine-tuned to classify comments as Toxic (1) or Non-Toxic (0).
How I Built It
- Used XLM-RoBERTa-base for native multilingual support across Hindi and English
- Fine-tuned for 3 epochs on 9,000 labeled comments
- 90/10 train-validation split with seed=42 for reproducibility
- ROC-AUC computed using softmax probabilities for reliable ranking
- max_length=128, batch_size=16, fp16=True
- Platform: Google Colab T4 GPU
Results
Non-Toxic (0) → Precision: 0.97 | Recall: 0.96 | F1: 0.96
Toxic (1) → Precision: 0.96 | Recall: 0.97 | F1: 0.96
✅ ROC-AUC Score: 0.9922
Challenges Faced
- Handling multilingual text (Hindi + English) without any language-specific preprocessing
- Perfectly balanced dataset (50-50) required careful evaluation using ROC-AUC over accuracy
- Excel file format (.xlsx) required special handling compared to standard CSV
What I Learned
XLM-RoBERTa handles multilingual text natively without any translation or language detection preprocessing. Cross-lingual transfer learning is extremely powerful for low-resource language tasks like Hindi toxic comment detection.
Built With
- google-colab
- huggingface-transformers
- numpy
- openpyxl
- pandas
- python
- pytorch
- scikit-learn
- t4-gpu
- xlm-roberta


Log in or sign up for Devpost to join the conversation.