-
-

-
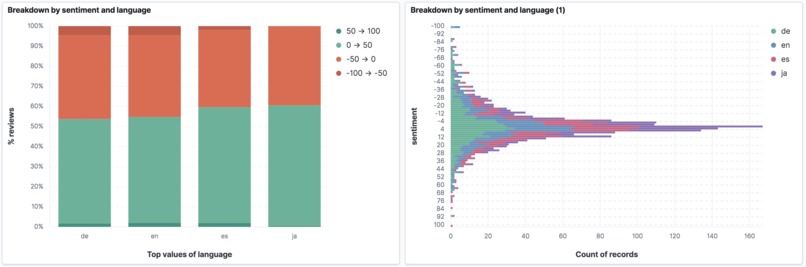
Breakdown by sentiment and language
-
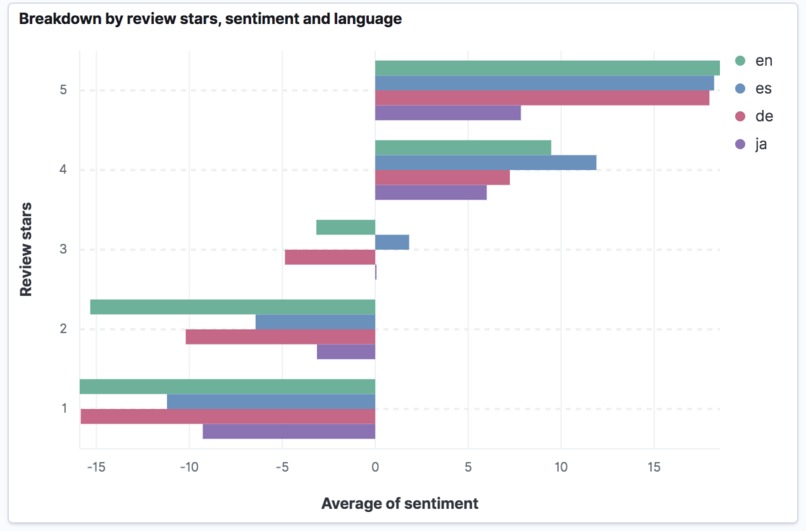
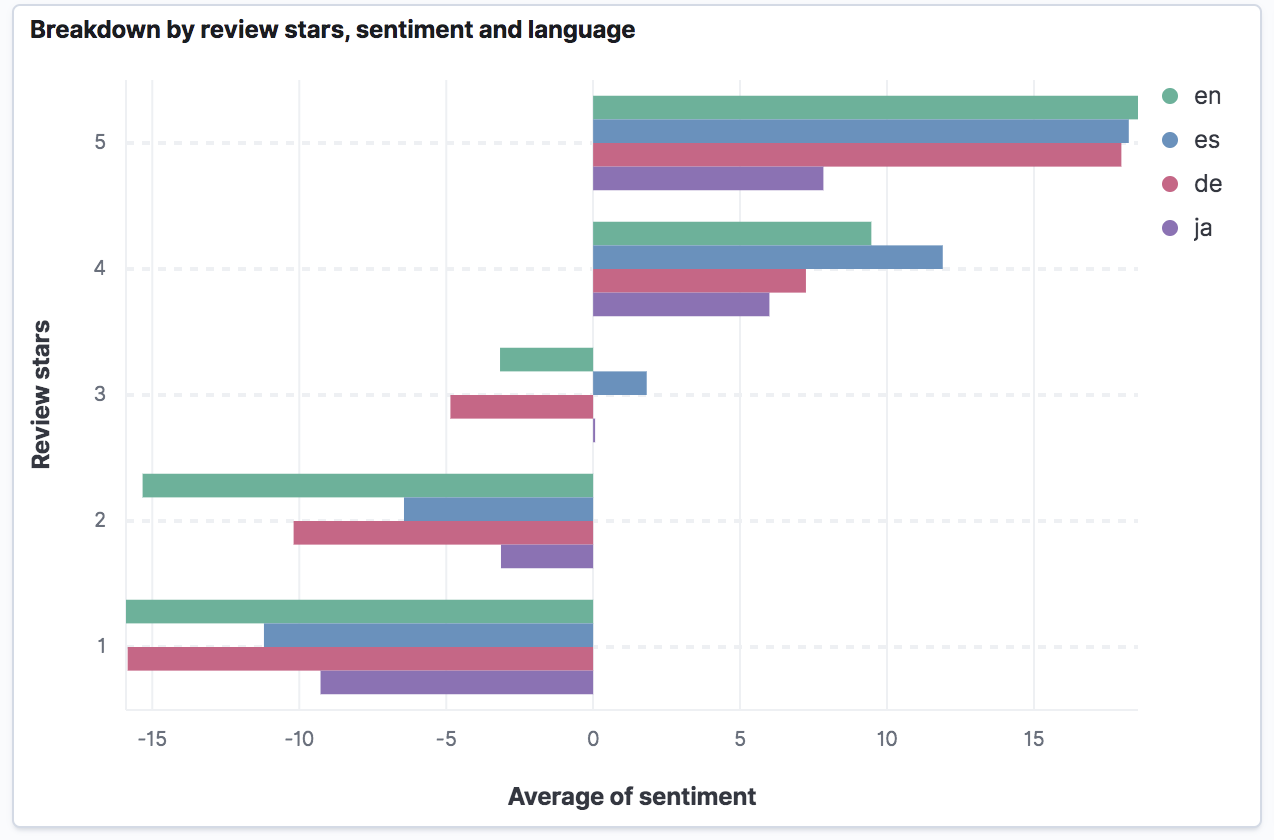
Breakdown by sentiment, language, and review stars
-
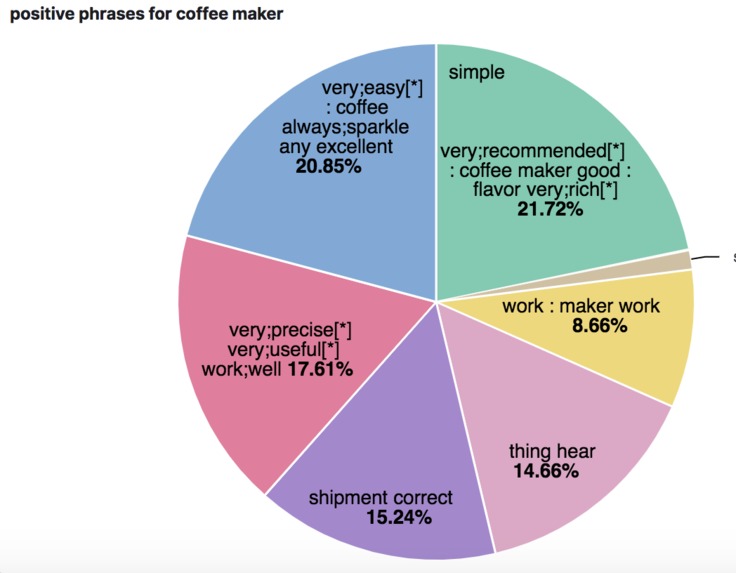
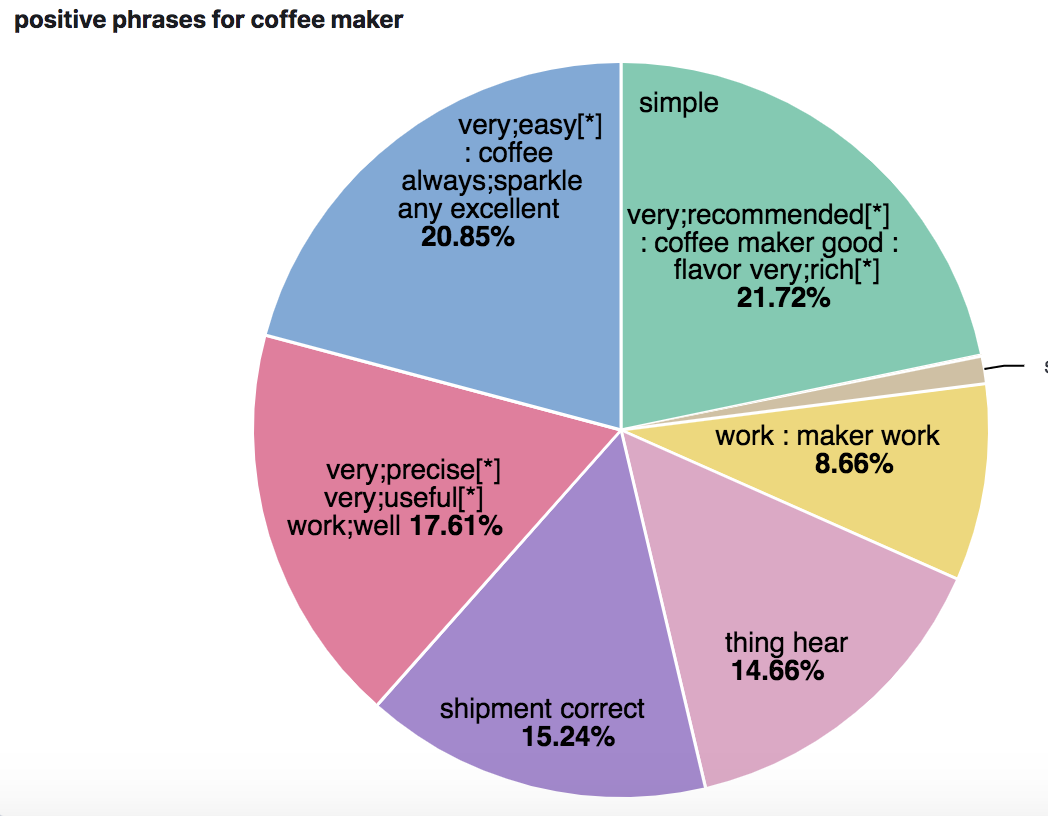
Positive phrases for coffee maker

Inspiration
The inspiration for this project stems from the fact that many organisations, from SMEs to corporates, gather user feedback yet are not always capable of analysing it in depth. It becomes even more challenging for organisations operating in different geographies as user feedback may include multilingual content and may be mixed in nature, e.g. users may provide positive feedback for some aspects of a product or service and criticise others in the same review. Sentiment analysis is often done at a coarse level (either positive or negative) and having fine-grained information on what customers may dislike would help organisations provide better services and products.
What it does
By leveraging expert.ai functionality, together with the state of the art tooling for information retrieval and machine translation, we make sure that user feedback collections
- are made searchable using review content
- can be filtered on different entries from the knowledge graph and sentiment as provided by expert.ai and other metadata
- are analysed at a fine-grained level by presenting phrases that indicate positive or negative sentiment to an end-user for a better understanding of mixed reviews
- are translated into English before they are processed by expert.ai sentiment module. This has been done because expert.ai offers sentiment analysis for English.
How we built it
To exemplify diverse functionality of expert.ai we opted for the dataset of multilingual Amazon reviews on products as described here, in particular its subset on kitchen products. Every review is translated into English if its original language is not English (i.e., German, Japanese, or Spanish) and processed by expert.ai API to extract relevant entities and sentiment information. This utilises not only sentiment analysis outcomes but also information from the knowledge graph, which could be particularly useful for filtering reviews in the future. We also recursively extract all phrases that are judged as positive or negative, to provide more insights into product or service aspects that are valued or criticised by customers. The next step is to index extracted data into a search engine, whereby the original review is being augmented with the analysis from expert.ai. By doing so, organisations are able to analyse reviews at a more fine-grained level and go beyond standard review indexing. For information retrieval, we use bm25 that has been the standard in the industry for many years, though it can be easily replaced with other retrieval methods, such as dense retrieval techniques.
Our tech stack includes the back-end in python, front-end in React, and deployment via Netlify. For search functionality we use Elastic, for machine translation MarianMT models and expert.ai for linguistic and sentiment analysis. Elastic is being hosted in the AWS cloud environment. Since we are using Elastic stack for search, we have also built a Kibana dashboard, to exemplify the types of analyses that can be conducted on the indexed data, see our video. We have noticed that the number of review stars strongly correlates with the overall sentiment regardless of a language, which provides additional support for the use of machine-translated data.
Challenges we ran into
Using labels from the knowledge graph as-is for indexing resulted in the problem because of the dot in their strings as they would split by default when indexing data into a search engine. To alleviate the problem with indexing, we replaced the dot with the underscore. We extract lemmata/lemmas from positive and negative phrases recursively, and phrases can be either noun phrases or verb phrases or other phrases. This makes it challenging to decide on how to display the order of lemmata/lemmas to an end-user. We've opted for the direct recursive strategy (e.g., 'very good coffee' after parsing json becomes 'coffee very;good[*]') but this also means that "reviewers have complained" is turned into "reviewers complain" and negation will be displayed as "product arrive not;yet" for the sentence that includes "product has not yet arrived". This is fine for verb phrases but the order is reversed for adjectival or noun phrases.
Accomplishments that we're proud of
The NLP field has changed tremendously in the past years and we are proud of being able to leverage those developments and combine several different technologies for the synergetic effect. For instance, using machine translation yielded reasonable translations to be processed by expert.ai and the sentiment of translated reviews often correlates with the sentiment of the original review.
What we learned
We have learned a lot about expert.ai functionality and how to combine it with search and build a UI for the demo.
What's next for Multilingual review analyser
It's just a start! User studies would be helpful to determine how best to represent sentiment information in search results at the fine-grained level. Also, it would be helpful for a user to provide feedback when (s)he disagrees with the sentiment assessment. Last but not least, one could test various retrieval techniques and assess machine translation quality in more detail.
Built With
- amazon-web-services
- elastic
- expert.ai
- netlify
- python
- react

Log in or sign up for Devpost to join the conversation.