-
-
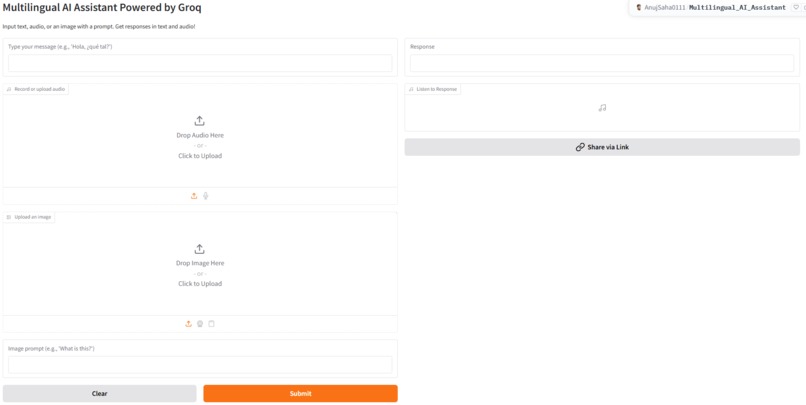
User Inferface
-

Text Input
-
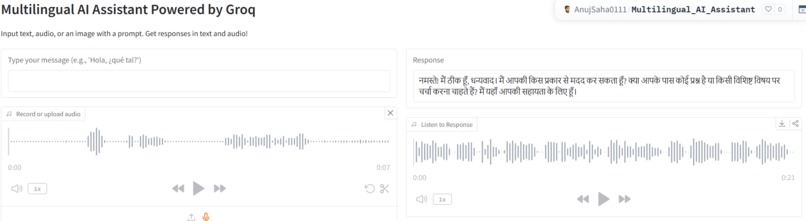
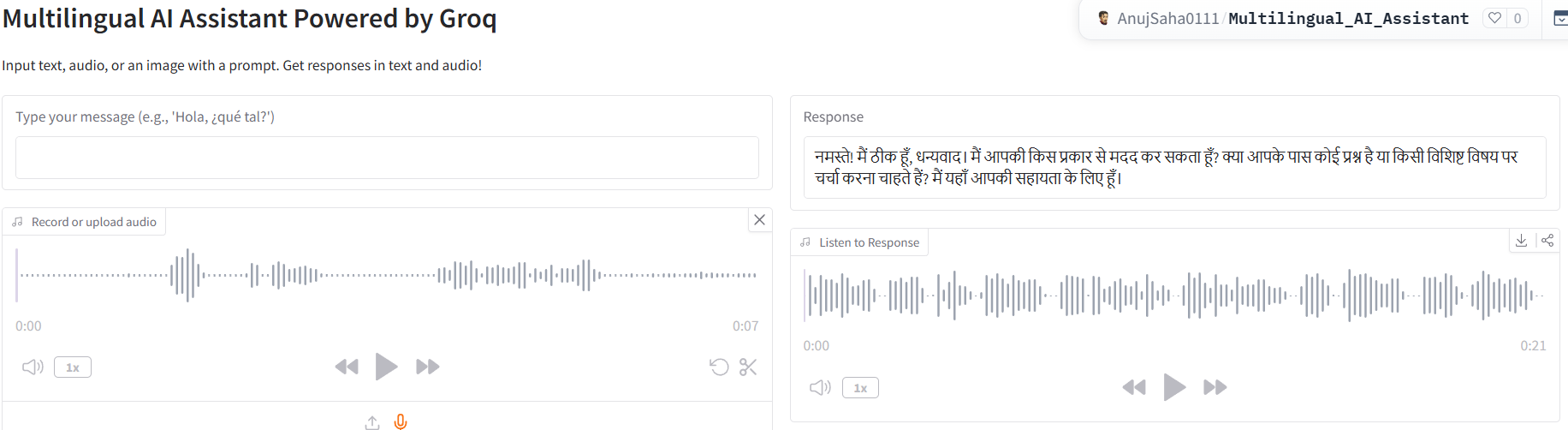
Audio Input
-
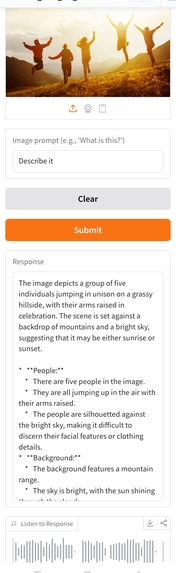
Image Input

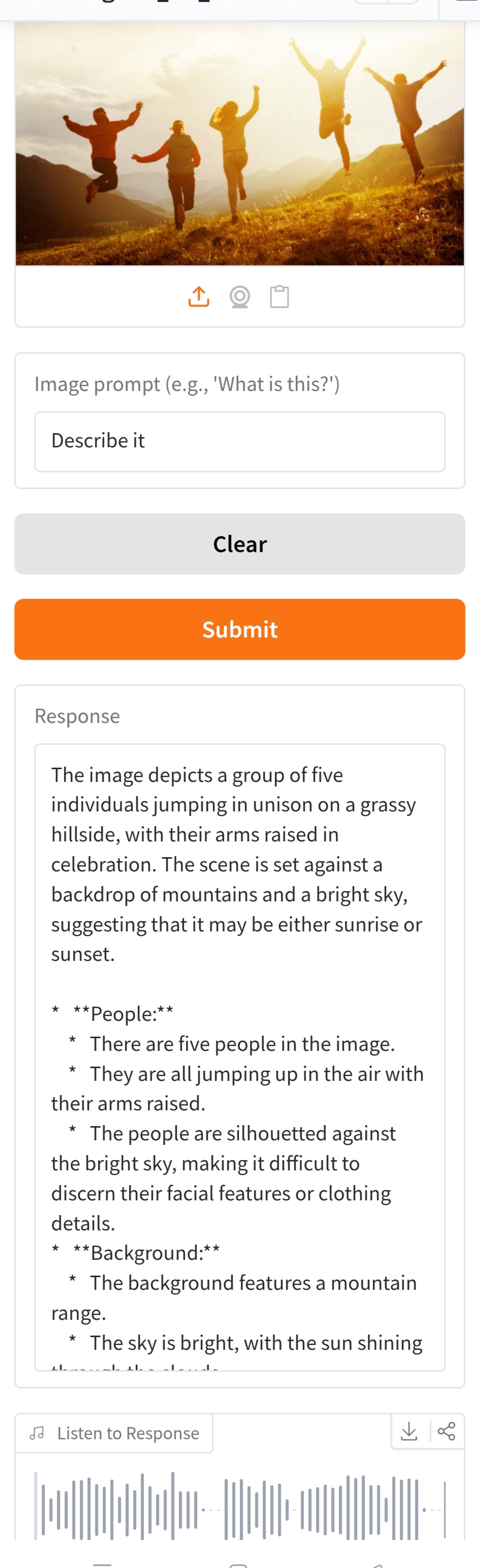
Inspiration
The Multilingual AI Assistant was inspired by the need to bridge communication gaps in a globalized world. The idea stemmed from personal experiences with language barriers during travel and the growing demand for real-time, accessible translation tools. We aimed to create a solution that leverages cutting-edge AI to handle text, audio, and image inputs seamlessly.
What it does
This project offers a versatile AI assistant that translates and responds to text, audio, and image inputs across multiple languages. Users can type a message, record audio, or upload an image with a prompt, and the assistant provides text responses along with synthesized audio output. Supported languages include English, Spanish, French, German, Italian, Chinese, Japanese, and Korean.
How we built it
We built the Multilingual AI Assistant using Python, integrating the Groq API for advanced language models (llama-3.3-70b-versatile and llava-v1.5-7b-4096-preview) and audio transcription (whisper-large-v3). The gTTS library generates audio responses, while Gradio creates an interactive user interface. Base64 encoding handles image processing, and language detection is powered by the langdetect library, all tied together with environment variables for secure API key management.
Challenges we ran into
We encountered issues with real-time audio processing due to file handling complexities and occasional API rate limits. Image recognition required careful prompt engineering to ensure accurate text extraction, and ensuring compatibility across diverse language models posed additional hurdles. Debugging multi-input workflows in Gradio also took significant effort.
Accomplishments that we're proud of
We’re proud to have created a multi-modal assistant that successfully integrates text, audio, and image translation in a single interface. Achieving smooth language detection and audio synthesis across eight languages, along with a user-friendly Gradio setup, marks a significant milestone. The project’s ability to handle real-world scenarios like travel signs demonstrates its practical value.
What we learned
We gained deep insights into multi-modal AI integration, learning to optimize API calls and handle diverse input types. We improved our skills in error handling, particularly with audio and image processing, and explored the potential of Groq’s high-performance models. Collaboration and iterative testing were key to overcoming technical challenges.
What's next for Multilingual AI Assistant
Next, we plan to expand language support, enhance real-time processing speed, and add offline capabilities. Improving image recognition accuracy and integrating more natural voice options are also on the horizon. We aim to deploy this as a web application and reach a broader audience.
Built With
- base64
- gradio
- groq
- gtts
- langdetect

Log in or sign up for Devpost to join the conversation.