-
-
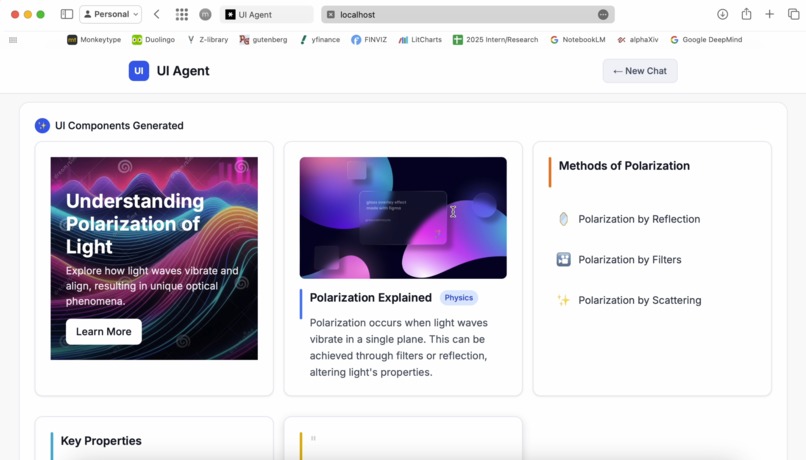
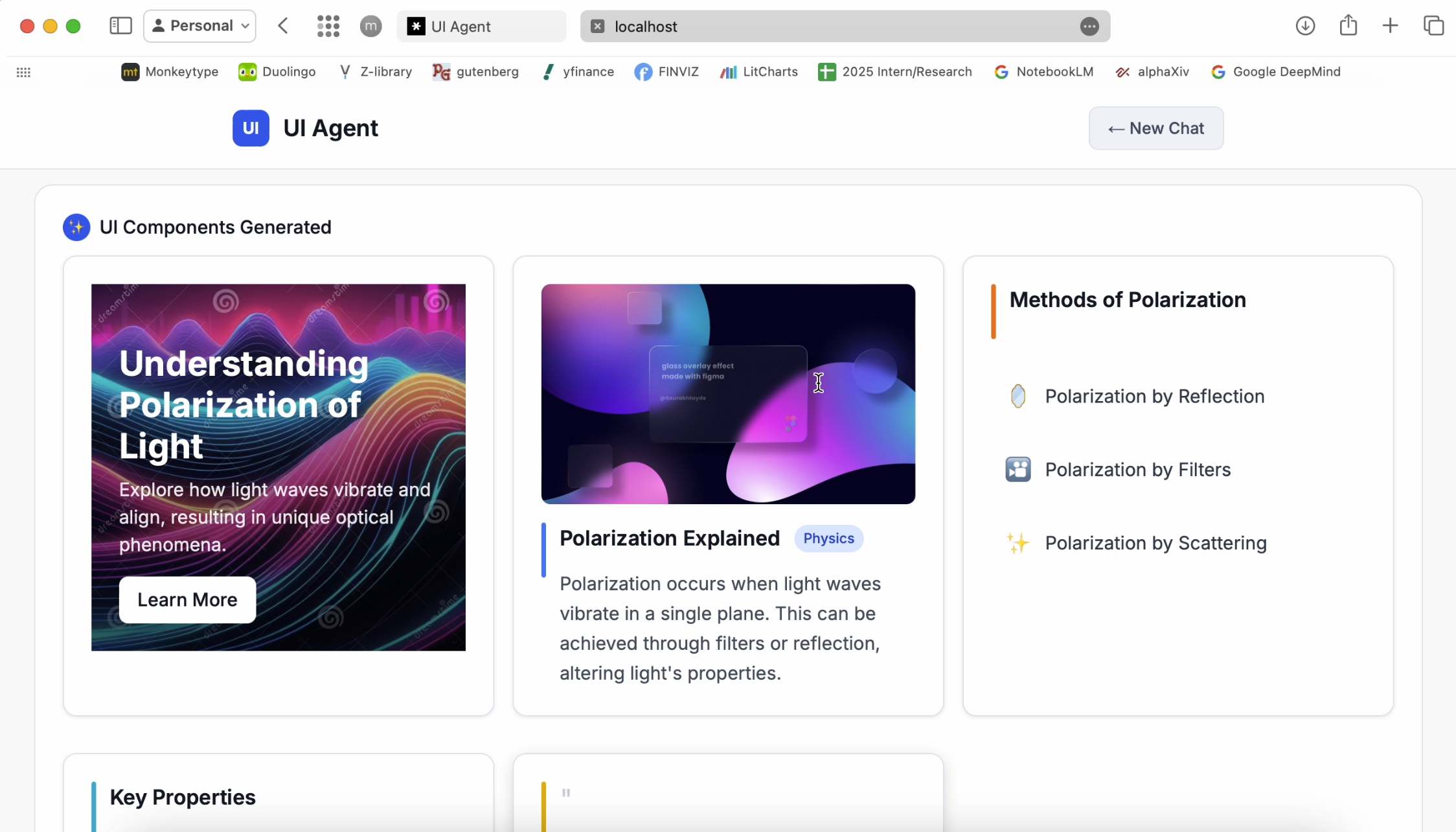
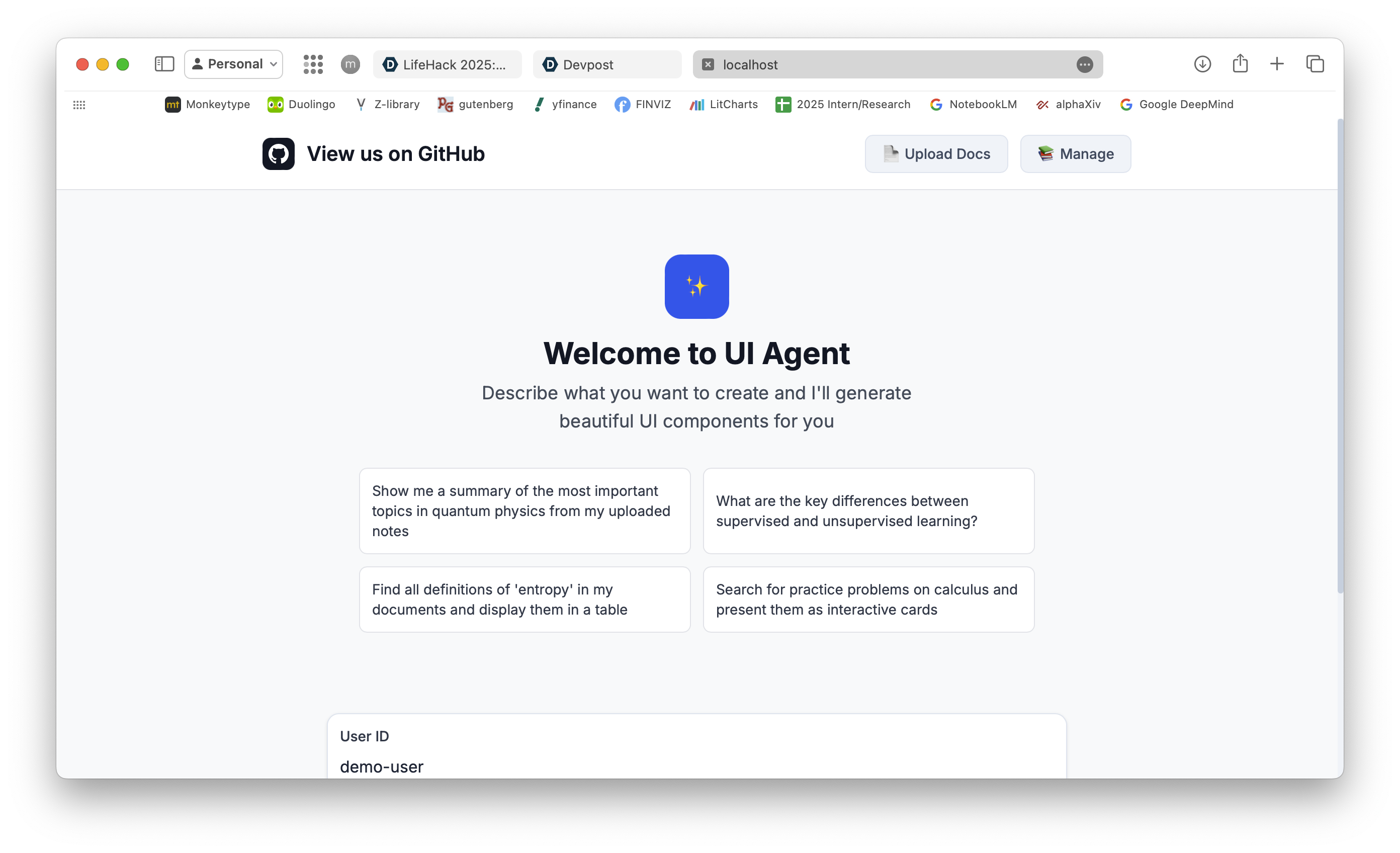
Dynamically generated UI
-
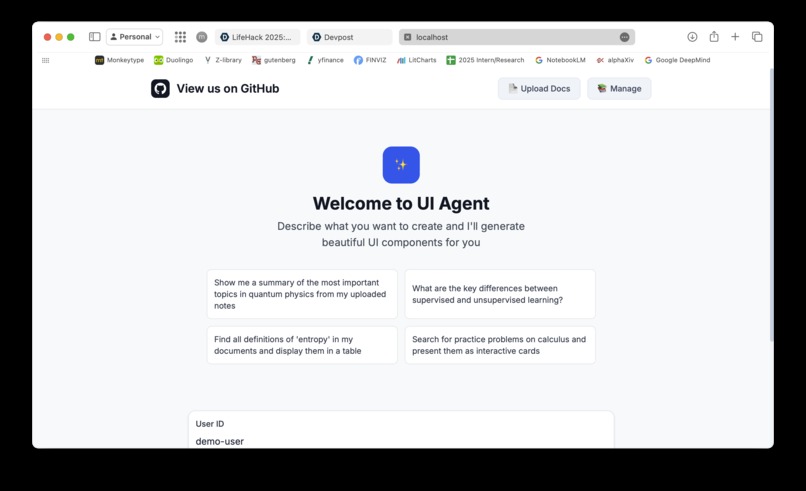
User friendly interface
-
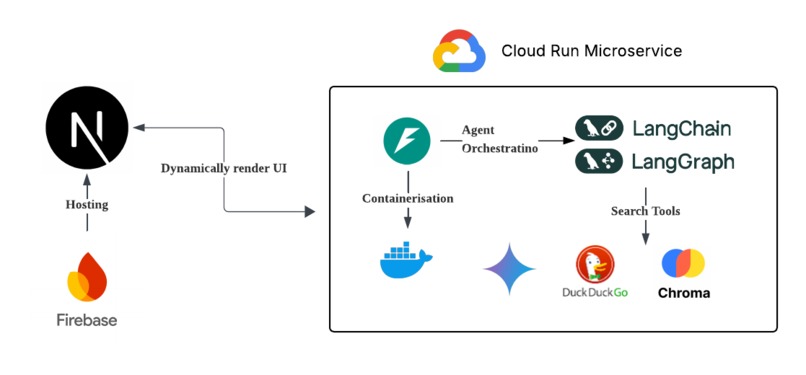
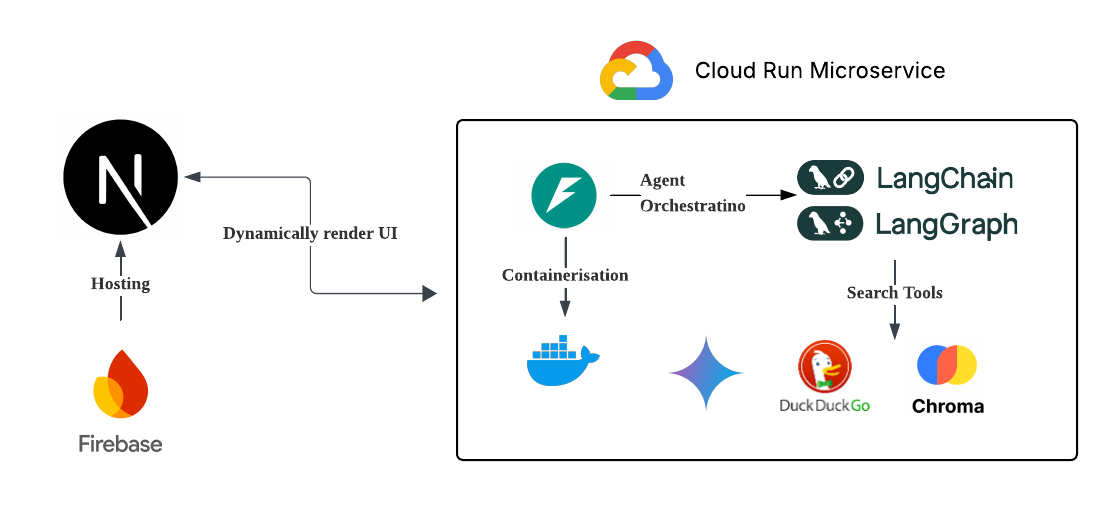
Multi-agent orchestration with cloud deployment
Inspiration
Why are AI agents or chatbots constrained to a simple, traditional text based interface? Even though the AI industry evolved rapidly in the last few years since the launch of ChatGPT, we noticed most LLM -- including advanced agents nowadays -- are still constrained to the original chat based interface. This means that people who prefer other modes of learning will find it difficult to use these chat interfaces.
So, why can't we make the AI go beyond text and learn to express itself better visually? We believe this is not only a key step towards personalised, accessible education, it is a stepping stone towards the future of agentic web!
What it does
Our AI-powered educational assistant goes beyond chat to generate dynamic, visual interfaces tailored to your learning needs. Instead of just text, the AI can present answers as cards, tables, galleries, or custom layouts, choosing the best format for each context.
With advanced multimodal capabilities, RAG, searches, and real-time image generation, the system delivers responses enriched with images, structured data, and interactive elements—making complex topics clearer and learning more engaging.
Key Features:
- Ask questions naturally about your documents or any topic, even the latest news
- Get personalized, visually rich answers by uploading PDF, PPTX, DOCX, and image files
- Interact with custom UIs—cards, tables, galleries, and more
Examples:
- Visual summaries of your notes
- Practice problems as interactive cards
- Side-by-side comparisons in tables
- Sortable lists of definitions from your files
How we built it and Tech Stack
We have three agents orchestrated in LangGraph using components and tools from LangChain
Research Agent
- Purpose: Gathers comprehensive information from multiple sources
- Tools: RAG search, web search, image search
- LLM: Gemini 2.0 Flash for research planning and synthesis
- Output: Consolidated knowledge base with documents, search results, and images
UI Designer Agent
- Purpose: Creates interactive UI specifications based on research findings
- Tools: UI image search, Imagen generation for custom visuals
- LLM: Gemini 2.0 Flash (high creativity) for UI design
- Output: Dynamic UI components with embedded content and generated images
LangGraph Orchestrator
- Purpose: Coordinates agent workflow and state management
- Features: Tool condition routing, state persistence, iteration control
- Flow: Research → UI Design → Response Generation
Backend
- Framework: FastAPI with Uvicorn
- AI/ML: LangChain, LangGraph, Google Gemini 2.0 Flash
- Vector Database: ChromaDB with Google Embeddings
- Search: DuckDuckGo Search API
- Image Generation: Google Imagen
- Document Processing: Unstructured, PyPDF, python-docx
Frontend
- Framework: Next.js 14 with TypeScript
- Styling: Tailwind CSS
- Components: Custom dynamic UI renderers
- Build: Static export for Firebase Hosting
Infrastructure
- Backend Hosting: Google Cloud Run (serverless)
- Frontend Hosting: Firebase Hosting
- CI/CD: Google Cloud Build
- Storage: Google Cloud Storage (optional)
Challenges we ran into
Limitations with customisability when we started with Google Agent Development Kit (ADK) so we had to migrate to LangGraph and design our own graph workflow. Cloud deployment was also tricky since building each container takes long and iterations are slow.
Accomplishments that we're proud of
It works! (First time building multi-agent system for all of us!)
What’s next for MultiFlex
MCP Exploration (Model Context Protocol):
Deepen our Model Context Protocol to dynamically adjust context windows, enabling the system to retain and prioritize relevant information across sessions, documents, and user interactions. This will allow more coherent, long-form dialogues and richer knowledge tracing over time.A2A Collaboration (Agent-to-Agent):
Implement peer collaboration between agents (research, design, and orchestration) to share intermediate insights, negotiate priorities, and co-solve complex requests, further boosting accuracy and creativity.Continuous Audio Monitoring & Transcription:
Introduce an “always-on” audio capture module (like Amazon's Alexa) that transcribes live speech into searchable text, enabling real-time Q&A on spoken lectures, meetings, or study sessions.SignGemma: Sign Language Support:
Launch SignGemma, our upcoming real-time sign-language interpreter, which translates live camera feed of sign language into text and speech, making educational content accessible to the Deaf community.Global Children’s Templates:
Expand our template library with age-appropriate, culturally diverse learning modules, ranging from early literacy to STEM explorations, so educators worldwide can deploy ready-made frameworks for every child’s unique needs.
Built With
- chromadb
- docker
- fastapi
- firebase
- gemini
- google-cloud
- google-cloud-run
- langchain
- langgraph
- next.js
- python
- tailwind-css
- typescript










Log in or sign up for Devpost to join the conversation.