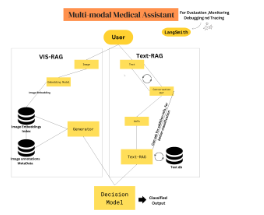
Multi-Modal Medical Assistant for Skin Diseases (Ansh Lulla, Advik Sharma) Overview The Multi-Modal Medical Assistant integrates Visual Retrieval-Augmented Generation VISRAG and Text Retrieval-Augmented Generation Text-RAG to analyze multi-modal medical data for classification tasks. It leverages LangSmith for evaluation, monitoring, and debugging, ensuring efficient and accurate decision-making. VIS-RAG: Visual Data Pipeline Input Image of the Skin Disease. Embedding Model Encodes image features into vector embeddings for similarity analysis. Image Index Stores embeddings for retrieval. Metadata Annotations Adds labels and contextual information. Generator Produces outputs, such as diagnostic insights or annotated images. Output Image-based diagnostic results or features for decision-making. Text-RAG: Text Data Pipeline Input Textual data (e.g., symptoms, reports). Text Database Retrieves relevant medical knowledge using embeddings. Conversational Augmentation Dynamically queries users for additional context to refine inputs. Multi-Modal Medical Assistant for Skin Diseases2 Generator Processes inputs and retrieved data for detailed analysis. Output Text-based diagnostic results or augmented insights. Integration Workflow VISRAG and Text-RAG independently process visual and textual inputs. Outputs from both pipelines are combined via a Decision Model, generating a comprehensive, classified result. LangSmith tools trace data flow, ensuring transparency and debuggability. Benefits Multi-Modal Retrieval Combines visual and textual embeddings for enriched analysis. Dynamic Augmentation Enhances input quality through iterative clarifications. LangSmith Monitoring Tracks data flow for debugging and evaluation. Efficient Embedding Storage Utilizes vector indexing for fast, scalable retrieval. Unified Decision Output Delivers actionable, multi-modal insights. Diagrammatic Representation Multi-Modal Medical Assistant for Skin Diseases3Applications Healthcare decisions often require correlating visual data (e.g., medical imaging) with textual data (e.g., patient records, clinical notes). The integration of VISRAG and Text-RAG enables enhanced decision-making through the Multi-Modal Data Integration. For radiology, dermatology, and pathology, VISRAG processes image data with high precision, supporting accurate diagnoses. Text-RAG efficiently processes the symptoms, and patient histories, providing valuable insights for decision support and efficient diagnosis. Conclusion The Multi-Modal Medical Assistant enhances healthcare facilities by integrating visual and textual data analysis, enabling accurate diagnostics and personalized care. Its dynamic retrieval and multi-modal fusion ensure efficiency and adaptability across diverse medical applications. This system thus represents a significant step towards leveraging Generative AI for improved patient outcomes and advanced medical research.
Built With
- langchain
- mistral
- pixtral
- python
- snowflake

Log in or sign up for Devpost to join the conversation.