-
-
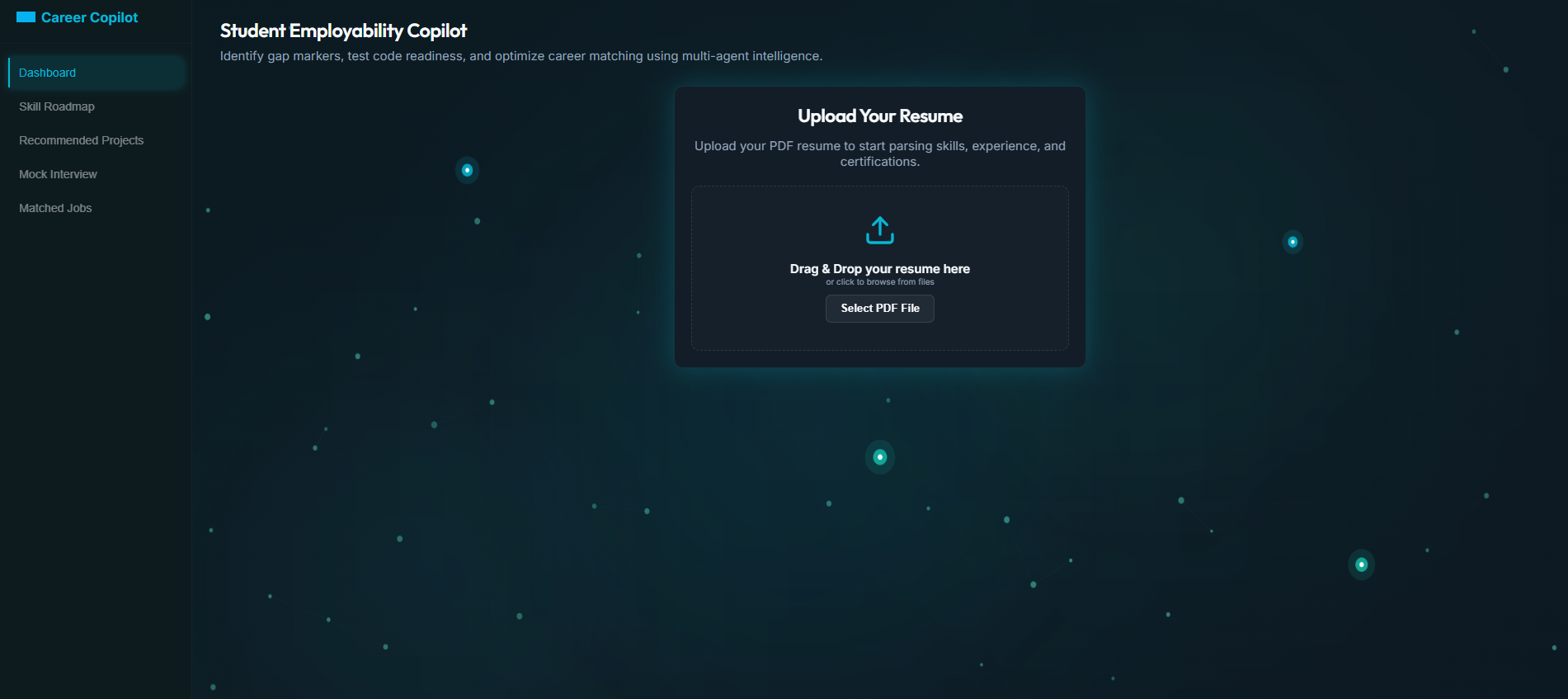
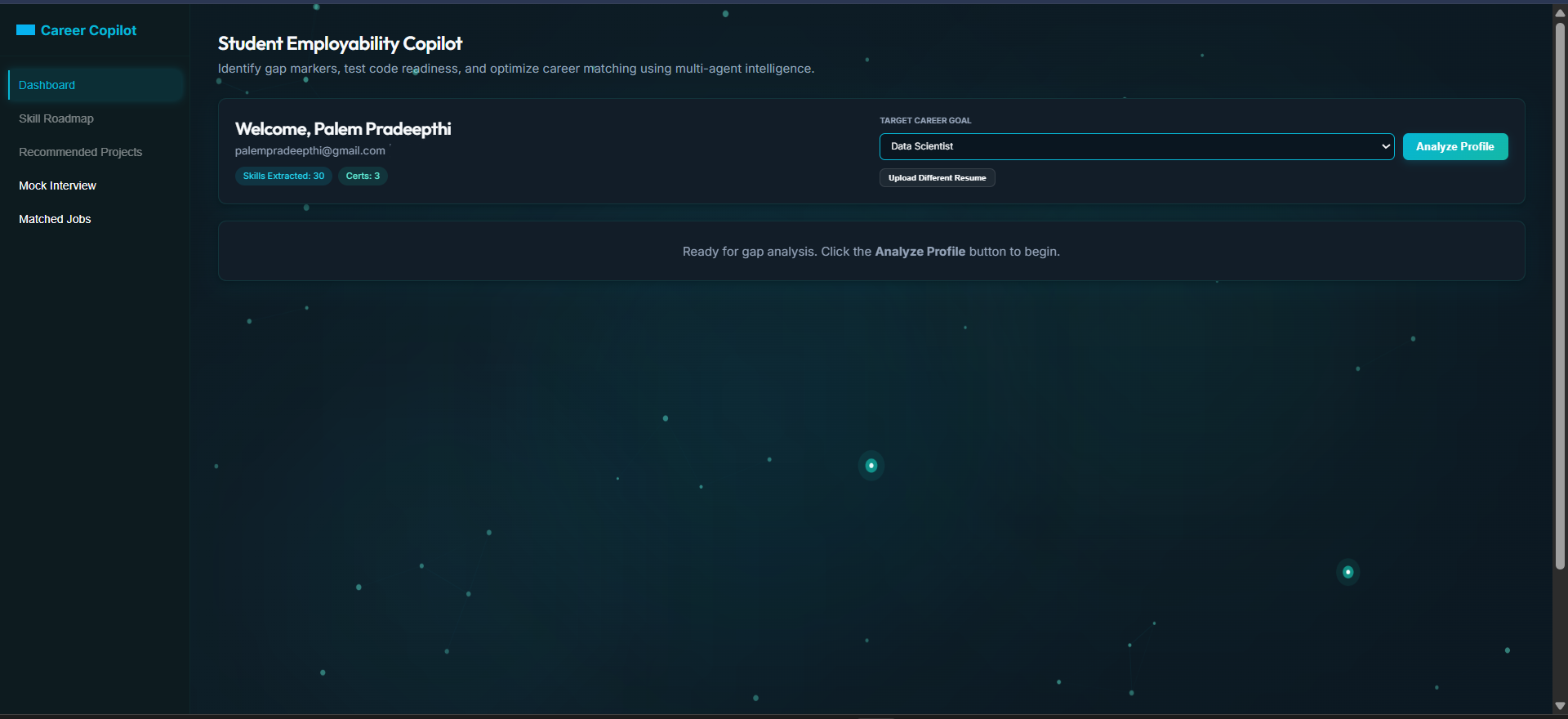
The Opening Page
-
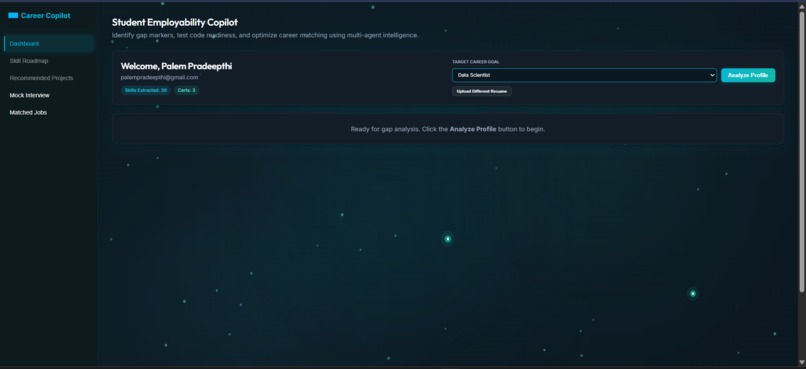
When Resume was Uploaded !
-
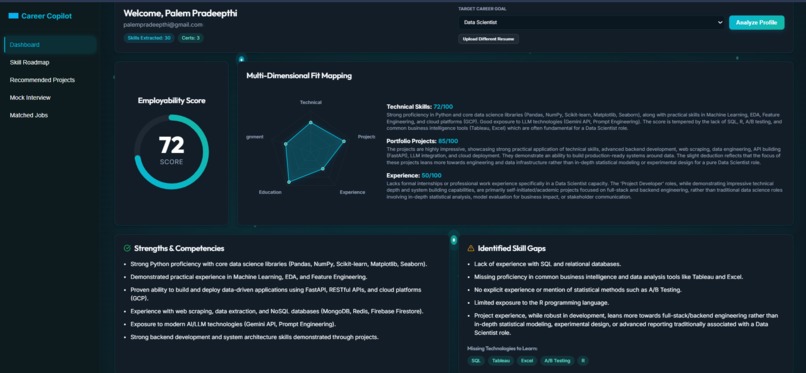
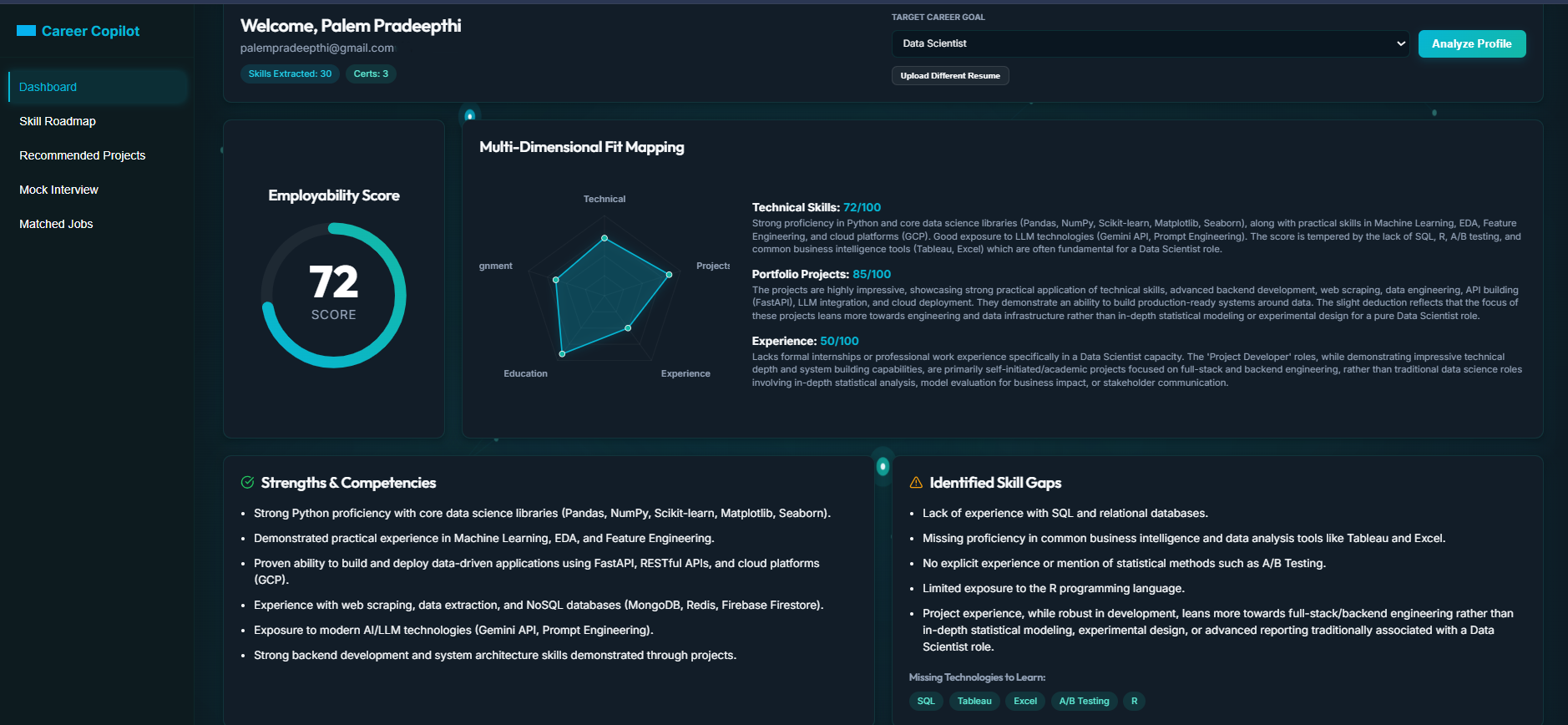
Resume Analysis with personalized dashboard.
-
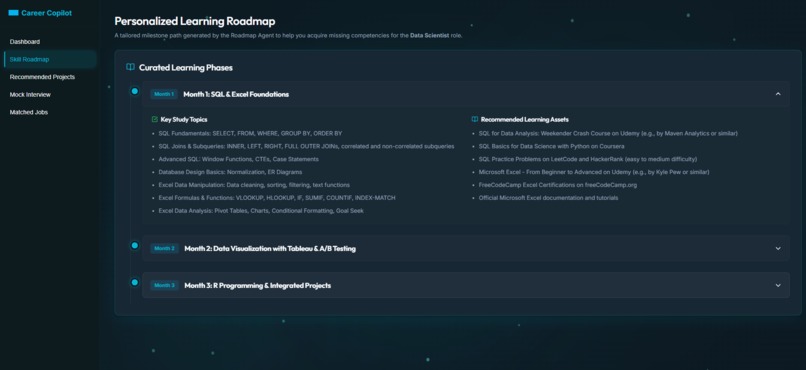
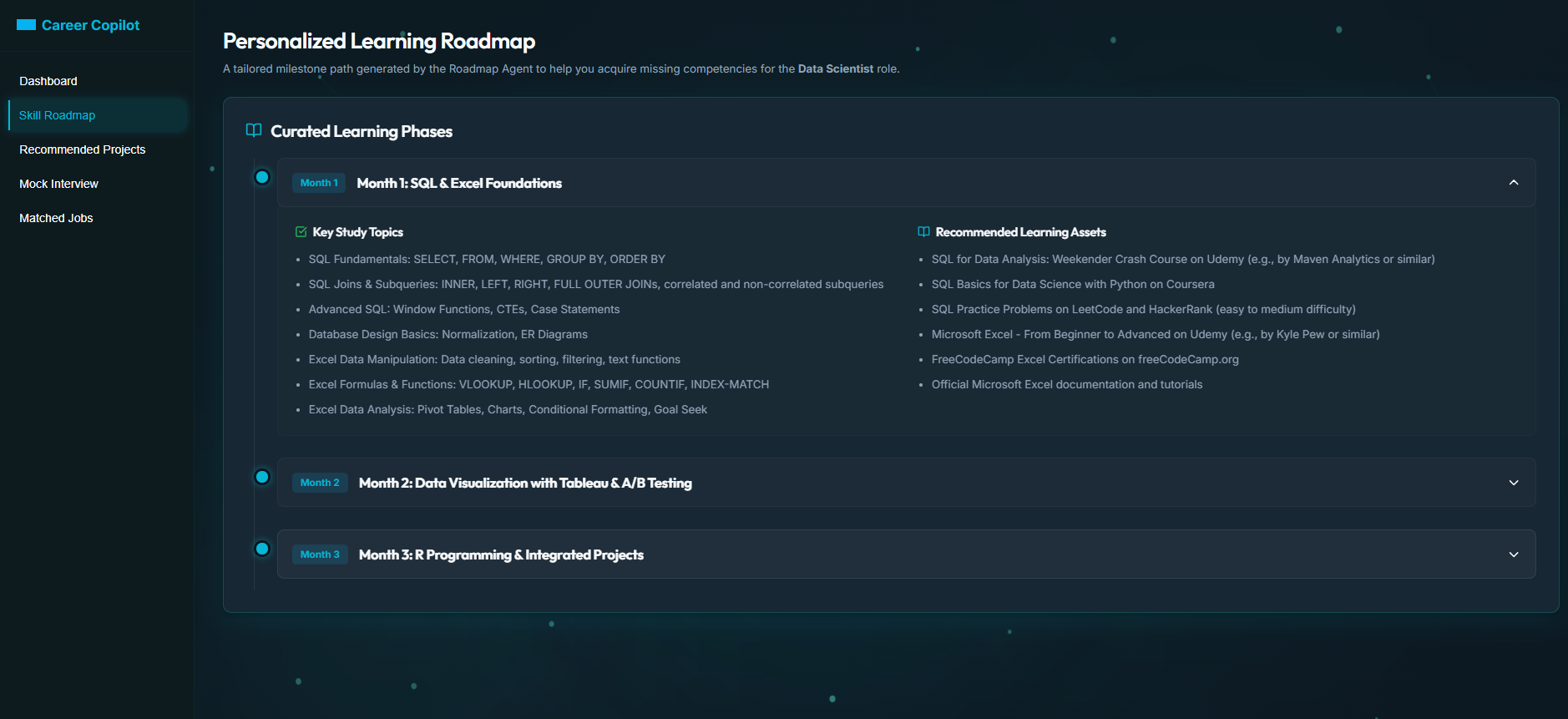
Personalized Learning Roadmap - with all the resources
-
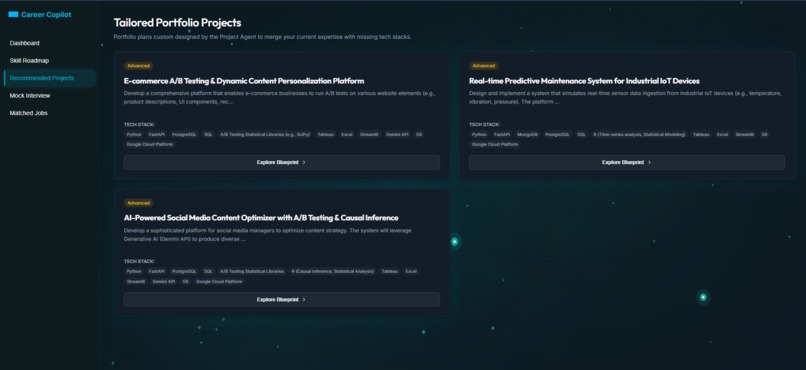
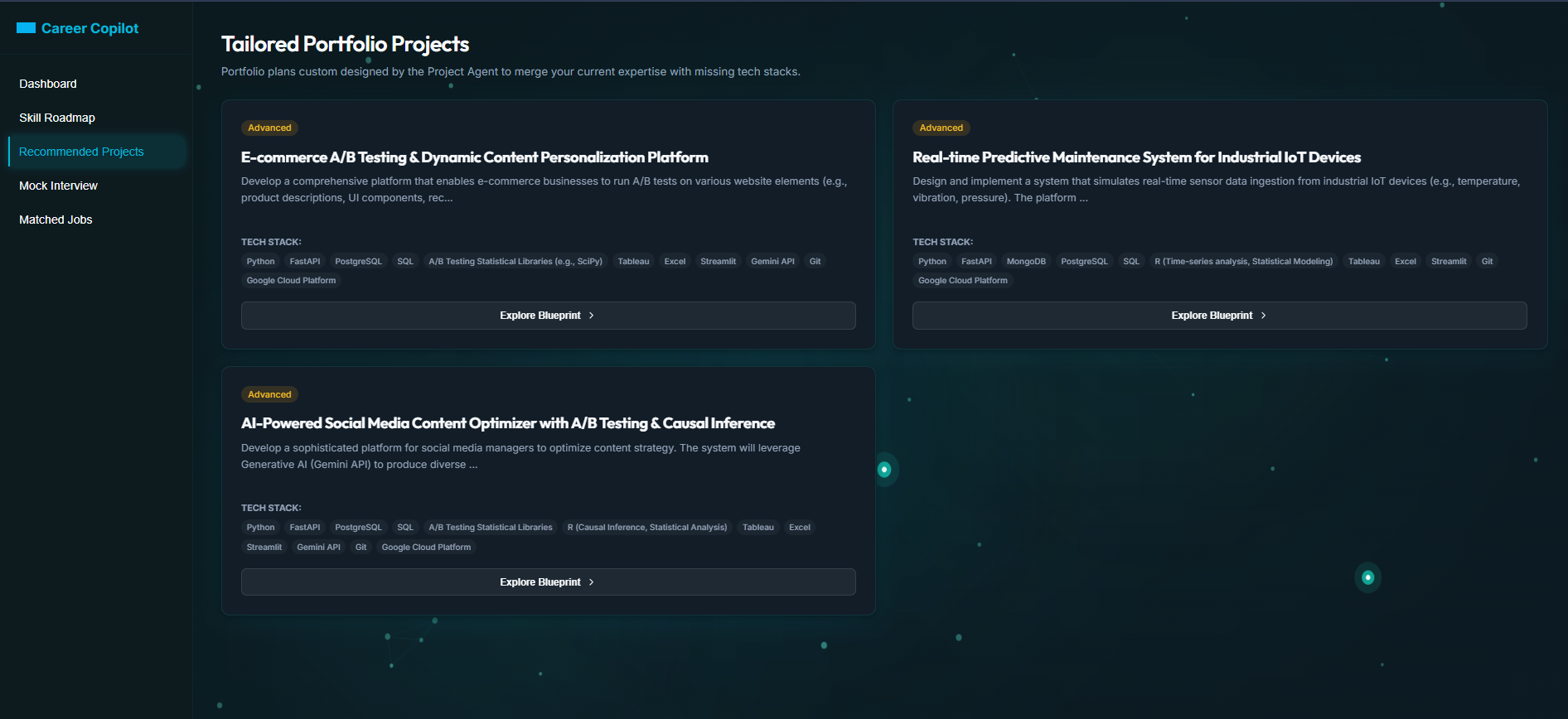
Tailored Portfolio Projects - which adds value to the resume
-
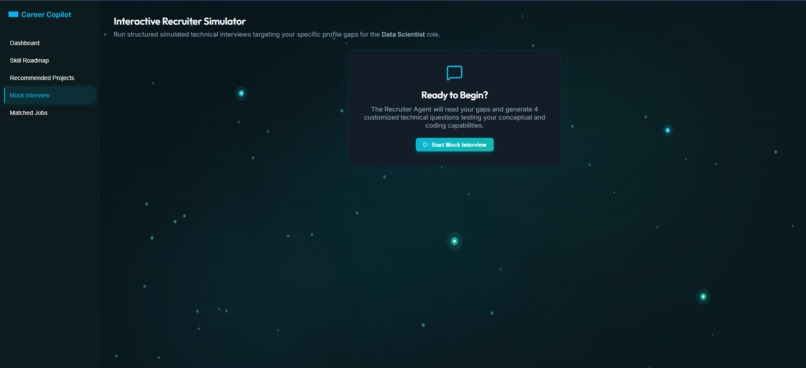
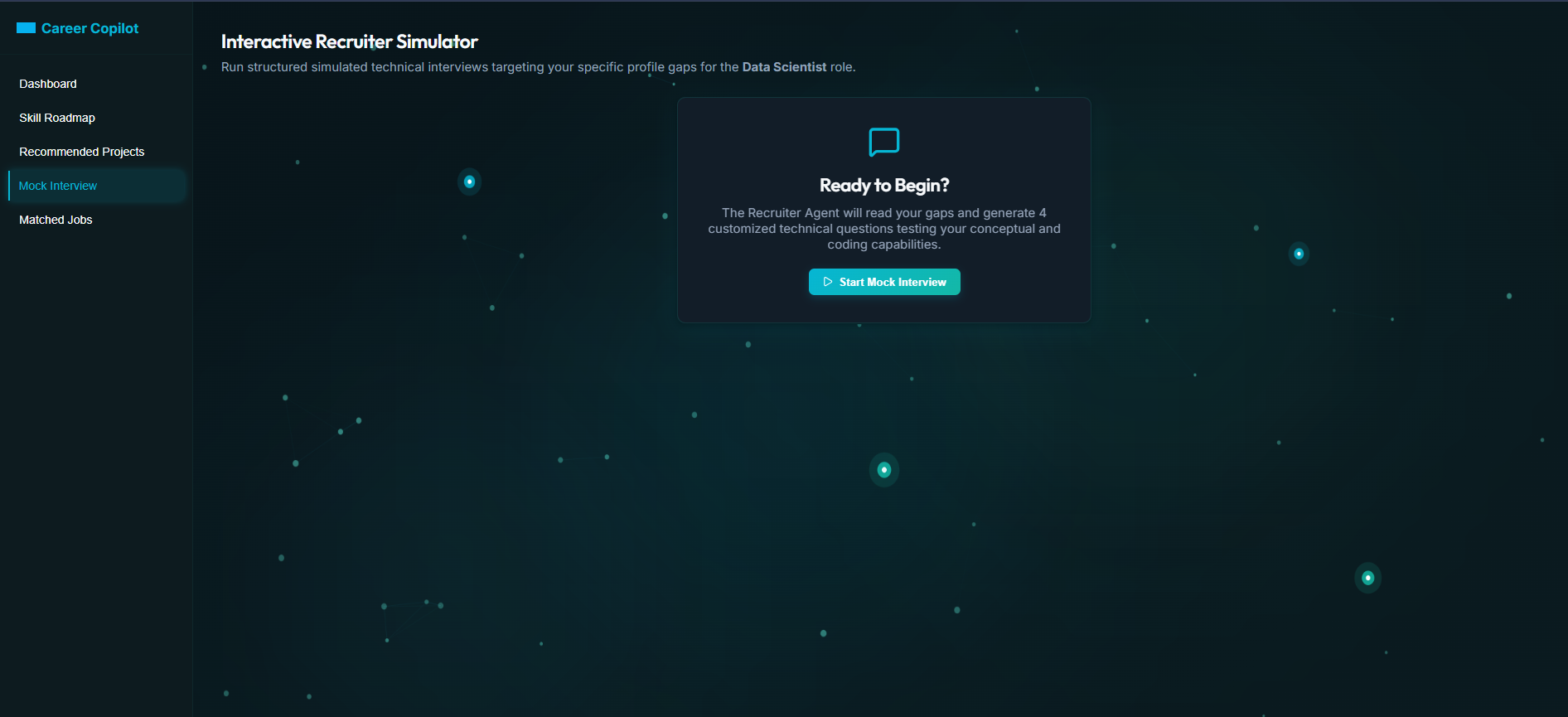
Personalized - Intersctive Recruiter Simulator
-
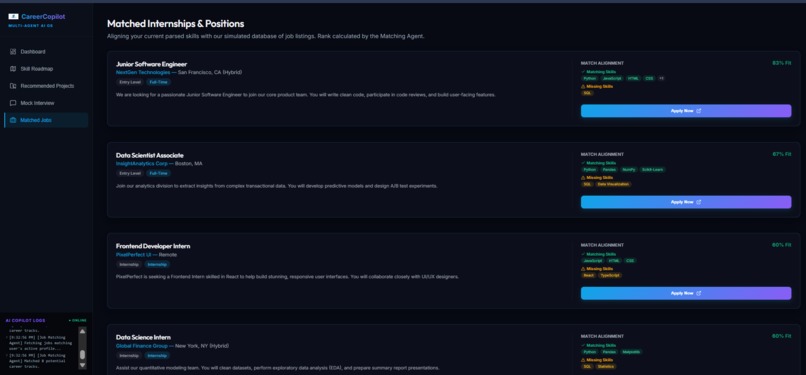
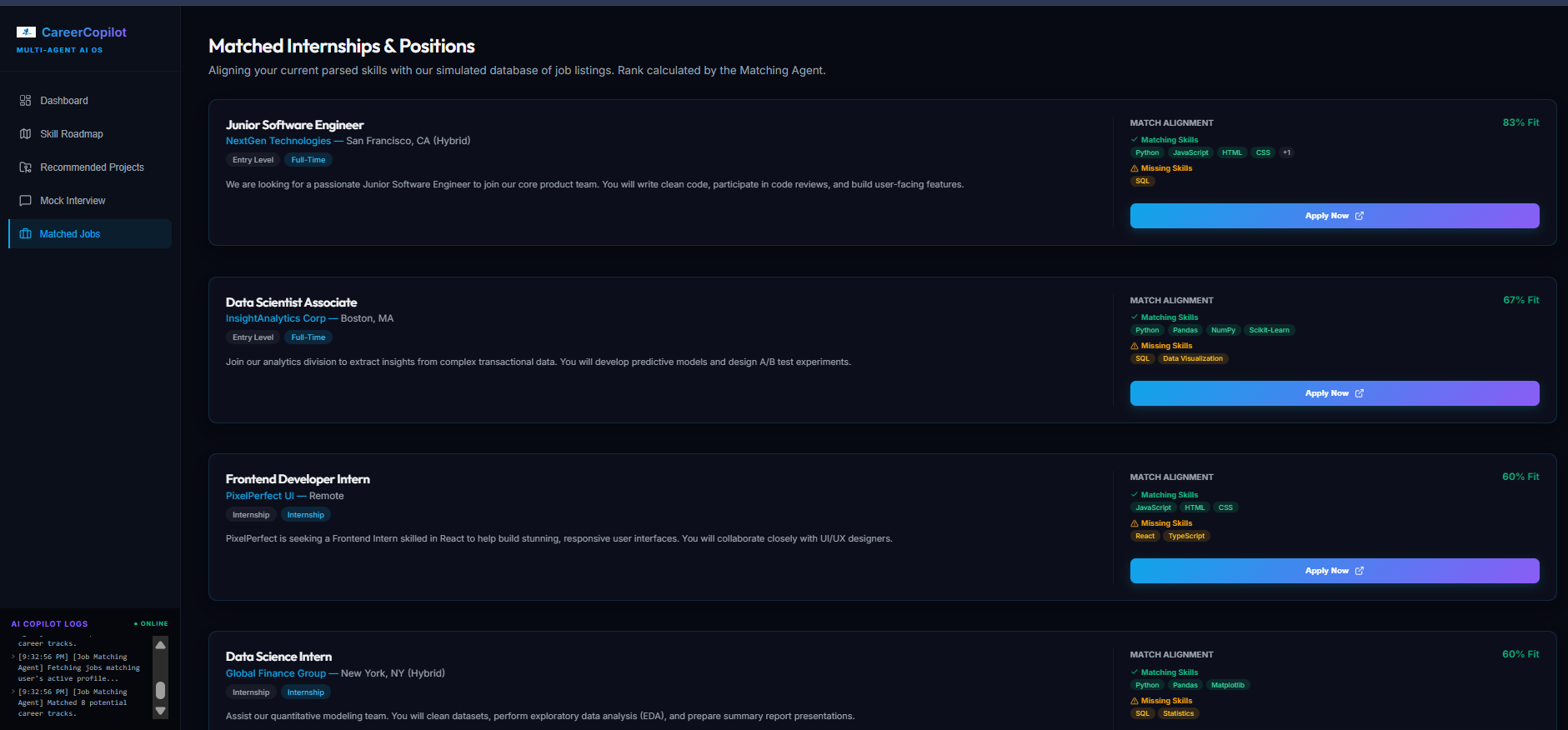
Personalized Matched Internships and Job roles
Inspiration
Every semester, thousands of students graduate with degrees but no clear map to their first job. The gap between what universities teach and what recruiters actually look for has never been wider. Friends spent weeks preparing for interviews without knowing which skills were actually missing from their profiles, or which projects would move the needle for recruiters. Career offices gave generic advice. Existing tools offered courses, but nothing that tied it all together into a personalized, intelligent action plan.
That frustration became the spark — a platform where a student uploads their resume and immediately gets a complete AI-driven career audit: skill gaps identified, a score assigned, a monthly roadmap generated, portfolio projects suggested, and even a live mock recruiter interview — all in one place.
What it does
The Multi-Agent AI Employability Copilot is an intelligent career platform powered by 7 specialized AI agents, each with a single focused responsibility:
- Resume Parser Agent — Converts raw PDF resume text into a structured student profile using Gemini's JSON API
- Skill Gap Analyzer Agent — Semantically matches the student's skills against standard role benchmarks (not just keyword matching — it understands that "FastAPI" covers "REST APIs")
- Employability Scoring Agent — Computes a weighted career-readiness score out of 100 across four dimensions
- Roadmap Generator Agent — Produces a structured monthly milestone plan to close identified skill gaps
- Project Recommender Agent — Suggests innovative portfolio projects that directly bridge the gaps
- Interview Coach Agent — Simulates a real technical recruiter screening conversation and evaluates answers
- Job Matching Agent — Ranks seed job listings by skill-alignment metrics against the student's profile The Employability Score is computed as a weighted composite: $$S_{\text{overall}} = 0.40 \cdot S_{\text{technical}} + 0.25 \cdot S_{\text{experience}} + 0.20 \cdot S_{\text{projects}} + 0.15 \cdot S_{\text{education}}$$ Where each sub-score \( S_i \in [0, 100] \) reflects real-world recruiter priorities — technical depth matters most, followed by hands-on experience. --- ## How we built it
Tech Stack:
- Frontend: React (Vite) + Lucide Icons + custom Canvas Particle System + Vanilla CSS
- Backend: Python + FastAPI + SQLAlchemy
- Database: SQLite (local) / PostgreSQL (Supabase-compatible)
- AI Engine: Gemini 2.5 Flash API (structured JSON mode)
All 7 agents inherit from a shared
BaseAgentclass built on a clean OOP paradigm: ```python class BaseAgent: def init(self, name: str, system_instruction: str): self.name = name self.system_instruction = system_instruction def query_llm_json(self, prompt: str) -> dict: # Calls Gemini 2.5 Flash and parses structured JSON output ...
Challenges we ran into
1. Making AI outputs reliable and structured
LLMs are probabilistic — they sometimes wrap responses in markdown or hallucinate extra fields. We enforced strict JSON schemas in every agent's system prompt and built a sanitizer that strips formatting before parsing. We treat every LLM response like untrusted input, validated against an expected contract before use.
2. Semantic skill matching
Simple string matching completely fails for resume analysis. A student who knows FastAPI satisfies the REST APIs benchmark — but a keyword matcher would flag it as missing. We rewrote the Skill Gap Analyzer to reason semantically, reducing false negatives dramatically. The gap between a student's skill set \( S_{\text{student}} \) and role benchmark \( S_{\text{role}} \) is now measured by semantic overlap, not exact intersection:
$$\text{Gap Score} = 1 - \frac{|S_{\text{student}} \cap S_{\text{role}}|}{|S_{\text{role}}|}$$
3. Stateful interview simulation over a stateless API
The Interview Coach needed to feel like a continuous recruiter conversation, but FastAPI endpoints are stateless. We solved this by injecting the full conversation history \( H = [m_1, m_2, \ldots, m_n] \) into each Gemini call as context, reconstructing conversational continuity on every turn without server-side session state.
4. Canvas animation performance
Rendering 60+ floating particles and 100+ dynamic connection lines simultaneously on a glassmorphic layout was expensive. We optimized by only connecting node pairs \( (i, j) \) where the Euclidean distance satisfies:
$$d(i,j) = \sqrt{(x_i - x_j)^2 + (y_i - y_j)^2} \leq 120 \text{ px}$$
This reduced render operations by over 70% and kept animations at a smooth 60fps.
Accomplishments that we're proud of
- Orchestrating 7 independent AI agents in a clean, extensible pipeline — each agent's JSON output feeds precisely into the next with zero ambiguity
- A weighted employability score that students and recruiters independently agree feels accurate: $$S_{\text{overall}} = 0.40 \cdot S_{\text{technical}} + 0.25 \cdot S_{\text{experience}} + 0.20 \cdot S_{\text{projects}} + 0.15 \cdot S_{\text{education}}$$
- Semantic skill gap analysis that understands context, not just keywords — a leap beyond any existing resume scanner we tested
- A live mock interview coach that simulates real recruiter conversations, evaluates answers in real time, and delivers structured written feedback
- A premium glassmorphic UI with an animated particle canvas running at 60fps — built entirely with Vanilla CSS and the HTML5 Canvas API, no external animation libraries
What we learned
1. Prompt engineering is a real engineering discipline Reliable, schema-compliant JSON from an LLM every single time requires careful system instructions, strict output constraints, and defensive parsing. We learned to never trust raw LLM output — always validate, always have fallbacks. 2. Multi-agent systems need explicit contracts Each agent must define a precise input/output JSON schema. Without clear contracts, chaining agents becomes fragile. Thinking of agents like microservices — with versioned interfaces — was the key architectural insight. 3. Semantic reasoning beats pattern matching Encoding intent into prompts (e.g., teaching the gap analyzer to reason about equivalences) produced dramatically better results than any rule-based skill matcher could. The quality improvement is non-linear — small prompt changes yielded large accuracy gains. 4. Weighted scoring requires calibration The composite score formula \( S_{\text{overall}} = \sum_{k} w_k \cdot S_k \) is only meaningful if the weights \( w_k \) reflect real-world recruiter priorities. We iterated on the weight distribution through multiple test profiles until scores aligned with what hiring managers intuitively expected. 5. Canvas performance needs spatial awareness
requestAnimationFrame alone doesn't guarantee 60fps. Throttling redraws and filtering connections using proximity conditions like \( d(i,j) \leq \delta \) was essential to make the UI feel alive without draining CPU.
What's next for Multi-Agent Student Employability Copilot
We want this to become a continuous career companion — not a one-time audit but an evolving tracker that measures student growth over time. As a student adds skills, their score updates: $$\Delta S = S_{\text{overall}}^{(t+1)} - S_{\text{overall}}^{(t)} = \sum_{k} w_k \cdot (S_k^{(t+1)} - S_k^{(t)})$$ When \( \Delta S \) crosses a threshold, the student gets notified they are now competitive for their target role. Planned next agents:
- LinkedIn Optimizer Agent — rewrites LinkedIn sections for ATS and recruiter visibility
- Salary Benchmark Agent — pulls real-time market compensation data by role and geography
- Cover Letter Agent — generates tailored cover letters for specific job listings
- Progress Tracker Agent — monitors week-over-week skill growth and sends personalized nudges The multi-agent architecture makes all of this extensible by design — new agents plug in without touching any existing ones. The career gap is a solvable problem. We just need smarter tools. 🎓

Log in or sign up for Devpost to join the conversation.