-
-
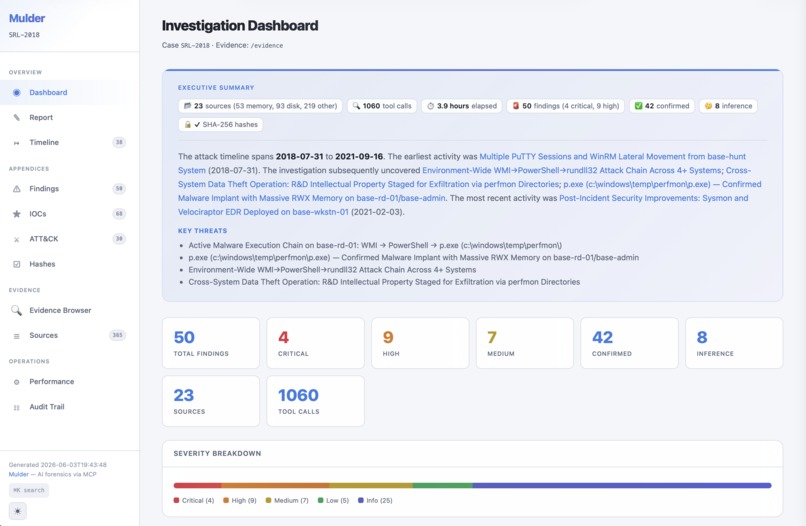
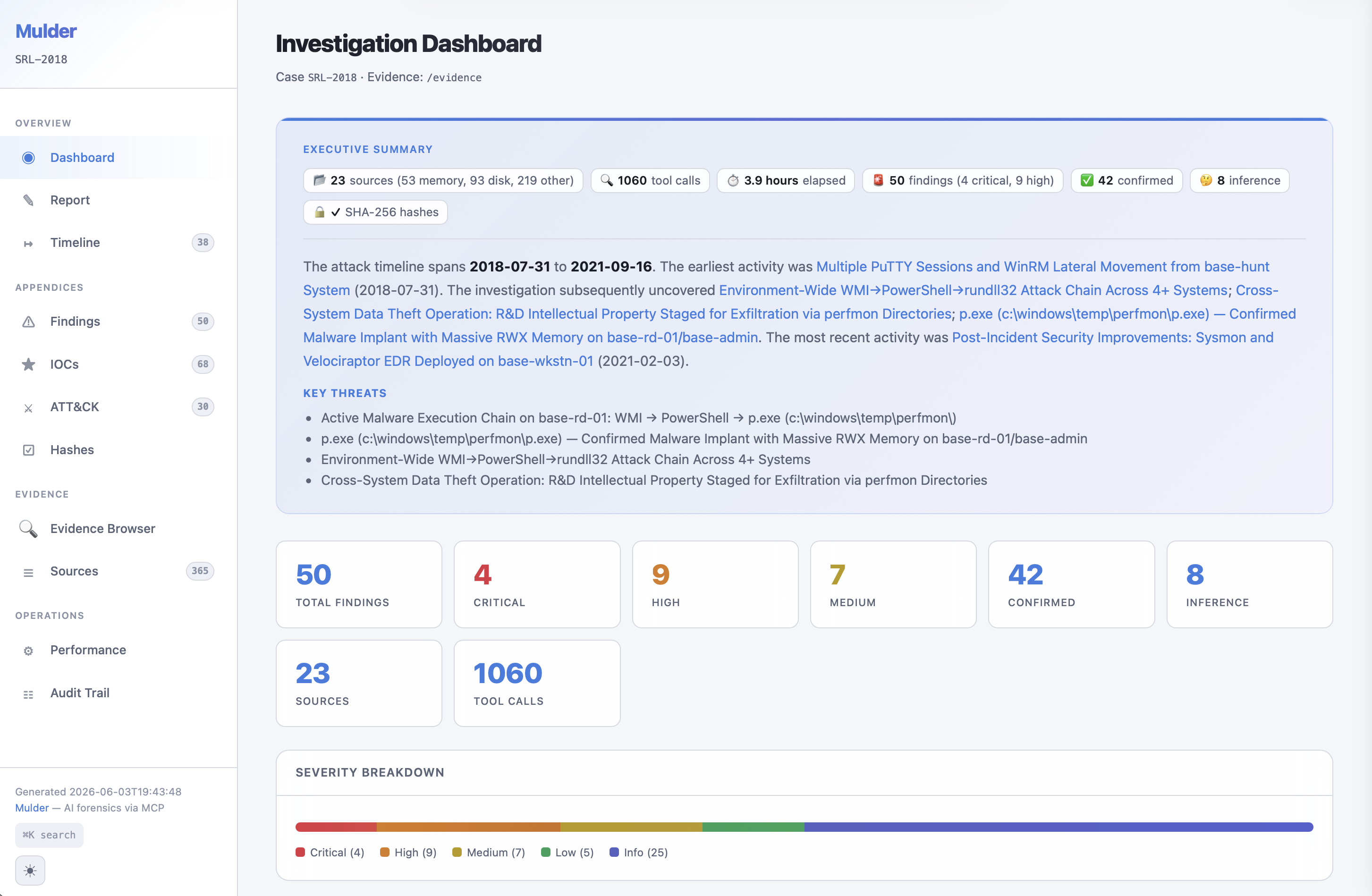
Investigation HTML report homepage (SRL-2018)
-
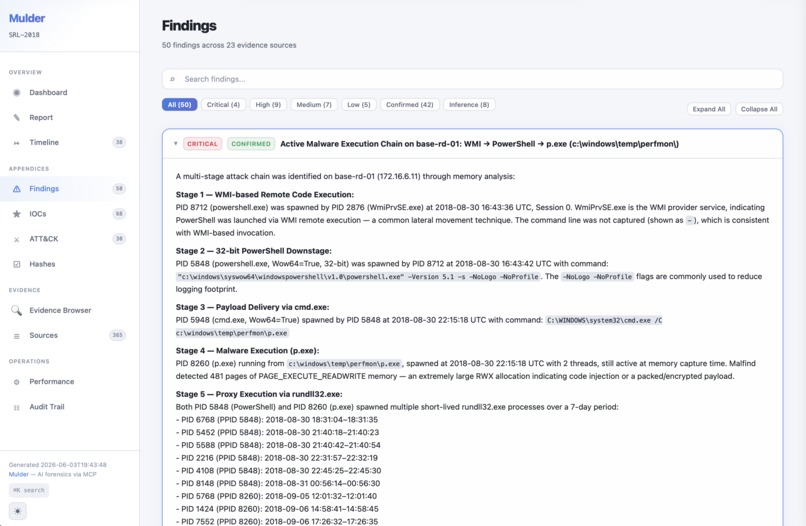
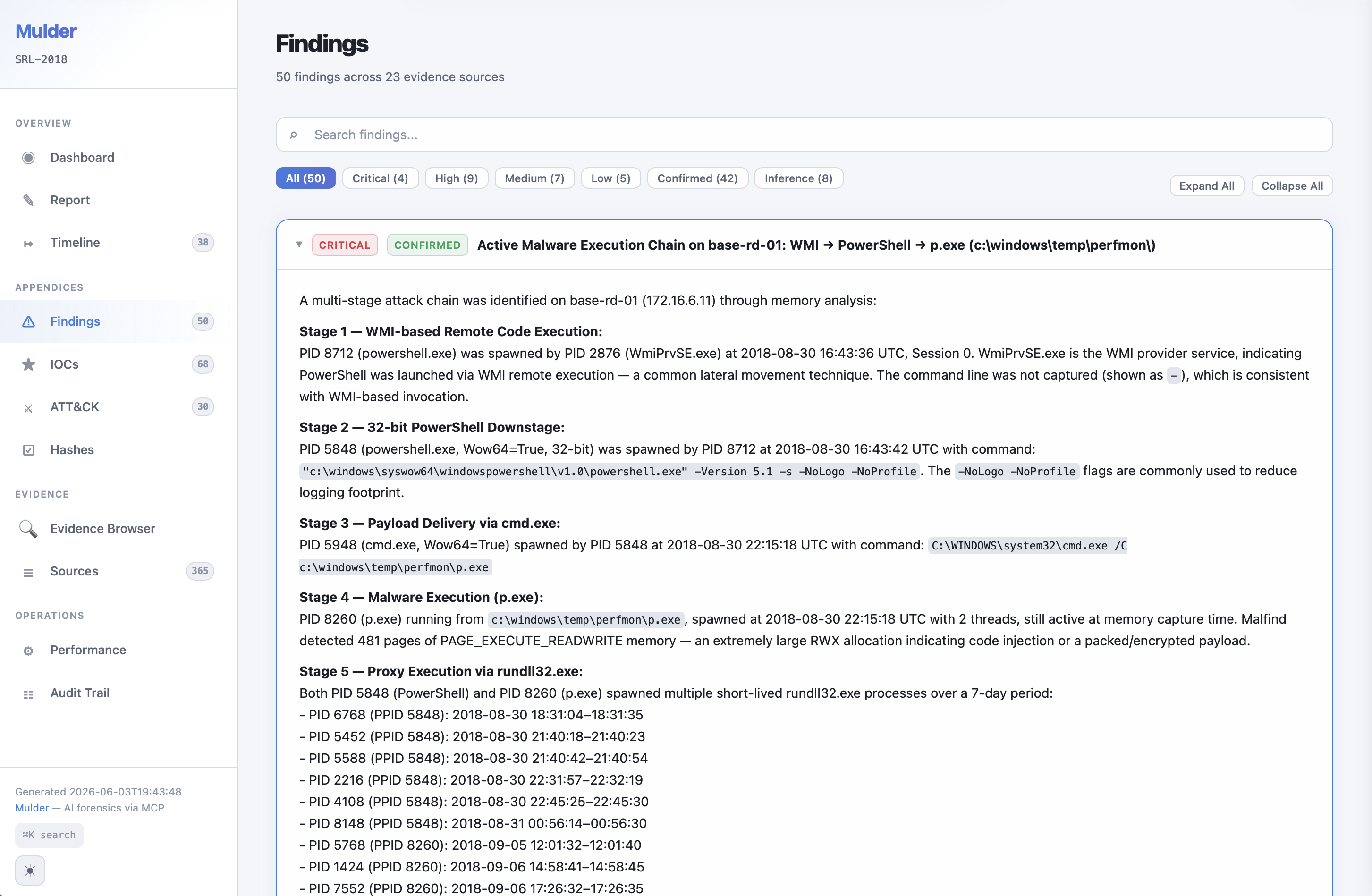
Investigation report findings example (SRL-2018)
-
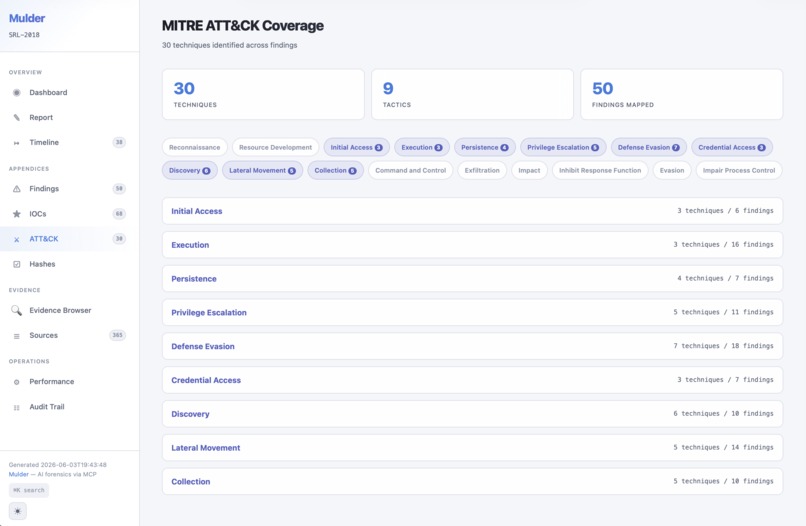
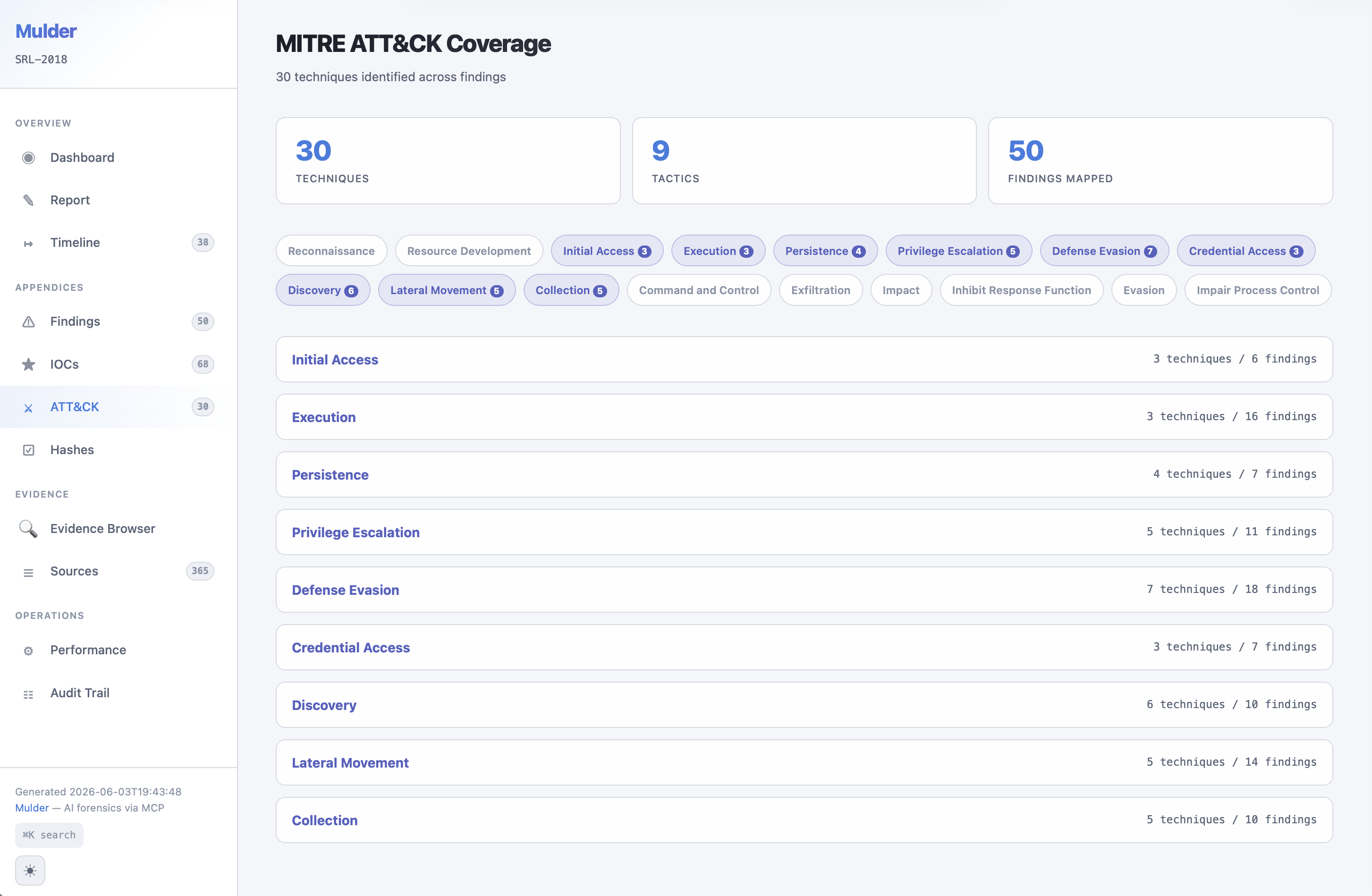
Investigation report MITRE ATT&CK page (SRL-2018)
-
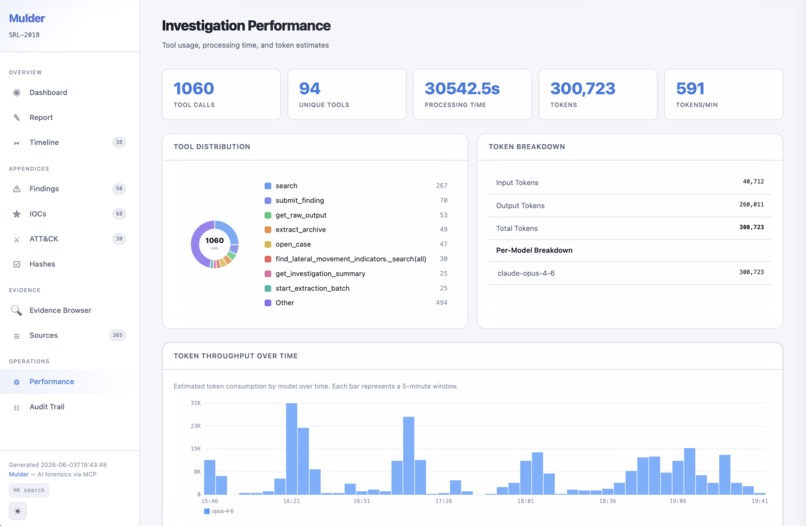
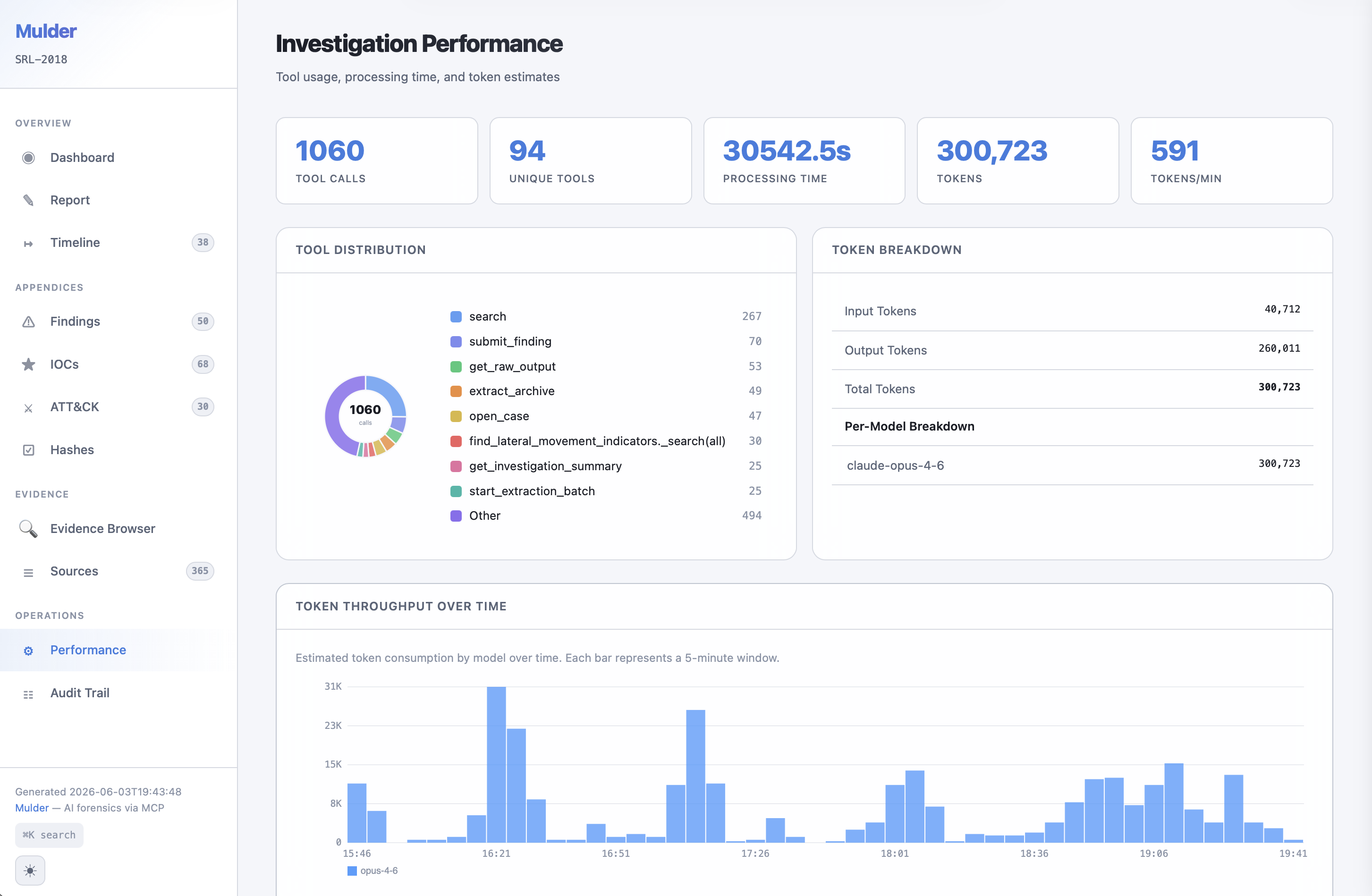
Investigation report performance tracking (SRL-2018)
-
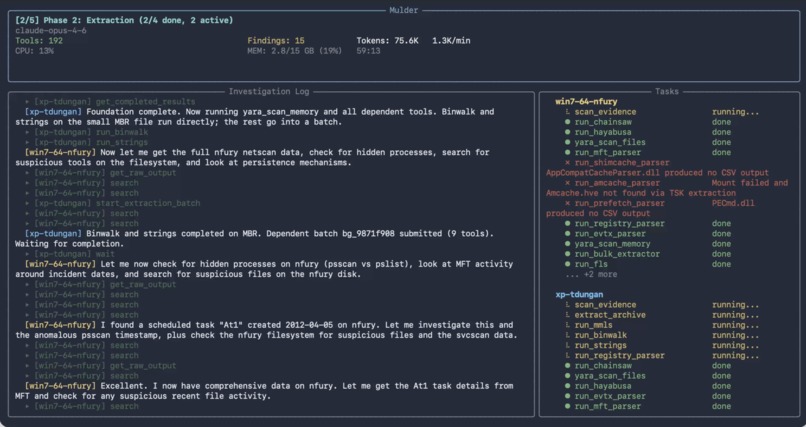
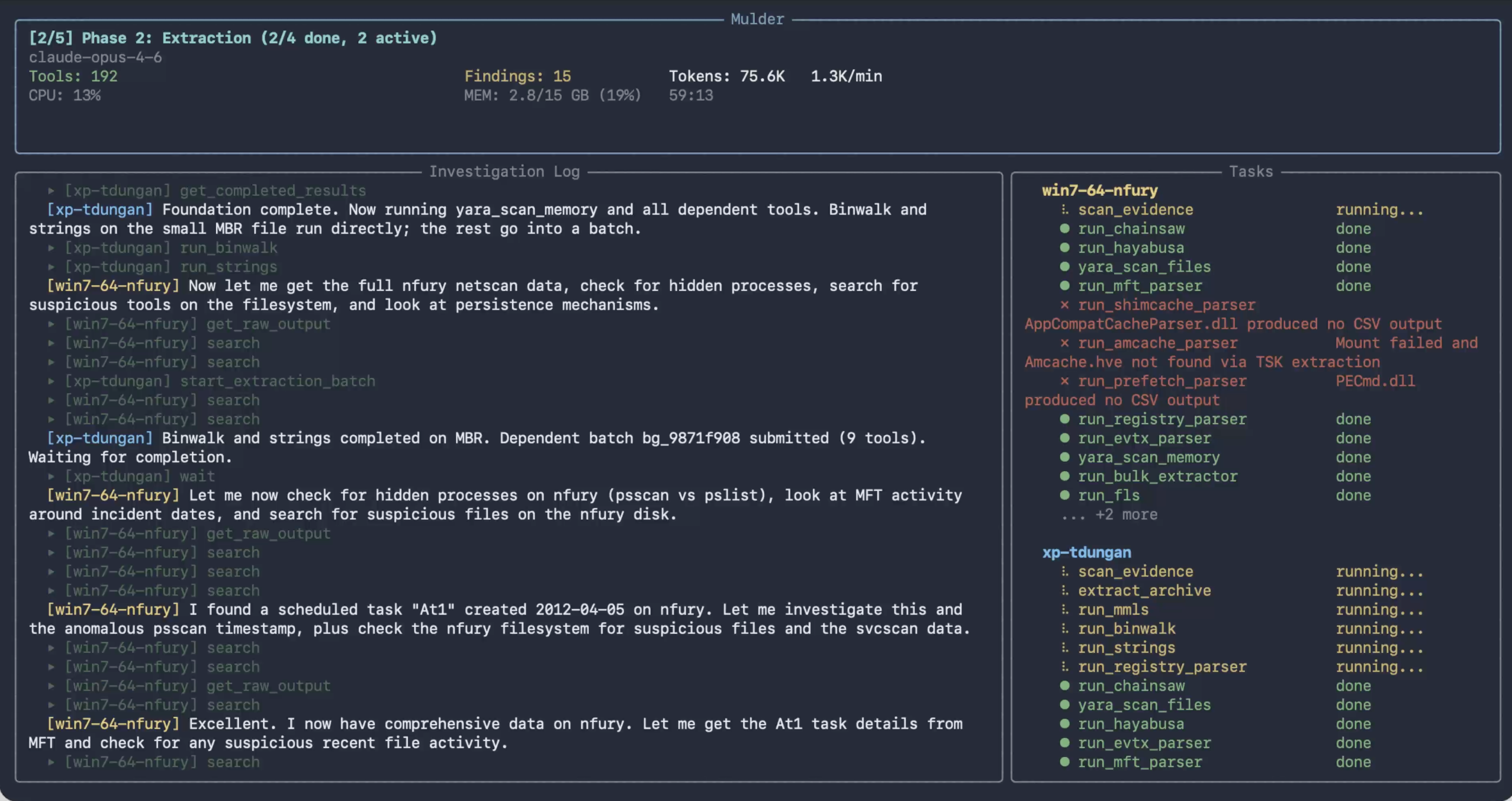
Mulder CLI mid-investigation
-
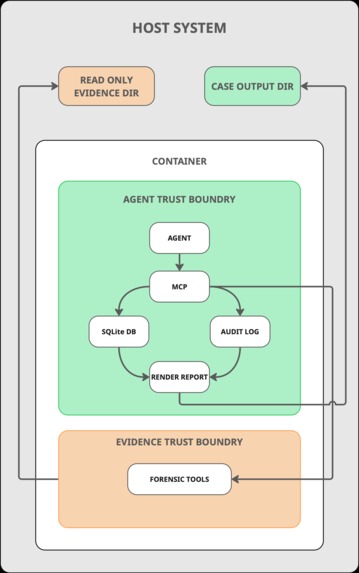
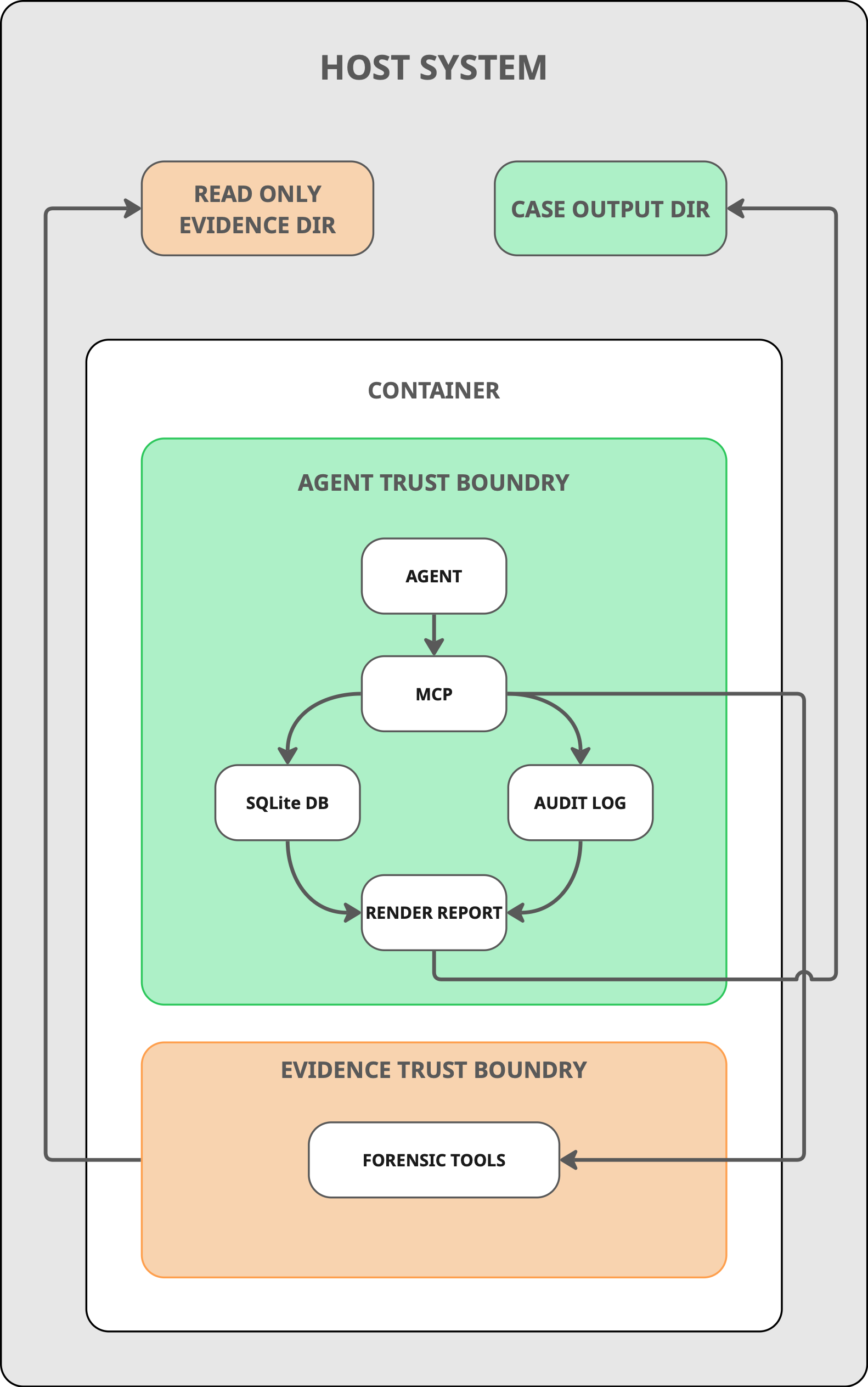
Architecture diagram
Inspiration
This hackathon posed a genuinely difficult challenge: how do you build an AI agent that can sift through hundreds of gigabytes worth of digital forensic evidence autonomously AND produce output you can trust? To combat this, I have built something where fabricating evidence is prevented by the architecture.
I am a senior software engineer at Red Hat, building developer tools like CI/CD pipeline and test failure analysis, deep research agents, and other non-AI-related tools. I have experience in the agentic AI space, but have never delved into the DFIR landscape. The closest I have come to this space is my expired Security+ certification. I approached this project from a systems design perspective rather than trying to automate a workflow I am already comfortable with.
My inspiration for this project comes from a strong interest in using AI for good, and to FIND EVIL!
What it does
Mulder takes a directory of forensic evidence (disk images, memory dumps, PCAPs, event logs) and runs a fully autonomous investigation. You mount the evidence, start the container, and run mulder investigate. Mulder is given 145+ typed forensic tools exposed through MCP and runs through a five-phase pipeline: catalog, extraction, cross-system analysis, alternative narrative, and report. Quality gates between each phase enforce structural criteria before proceeding.
Phases 2 through 4 use a three-role pipeline: planner, executor, analyst. The planner decides which tools to run. The executor calls them. The analyst interprets results and submits findings. When the analyst spots gaps, it can request follow-up cycles that send the pipeline back through planning and execution. These roles are enforced by tool allowlists at the orchestrator level, not by prompting.
The Alternative Narrative phase exists because the agent was consistently overconfident in early testing. It would run a handful of tools, find something suspicious, and submit a high-severity finding before doing the work to rule out benign explanations. Rather than trying to prompt my way out of that, I built a dedicated adversarial phase: a separate agent with its own context that challenges every major conclusion, searches for counter-evidence, and runs coverage audits to identify tools that were applicable but never invoked. In the NIST Data Leakage test case, the agent reconstructed the complete exfiltration timeline across four evidence items, identified both anti-forensics tools deployed (CCleaner, Eraser), correctly detected file masquerading across USB and optical media, and achieved a 90% detection rate against a 55-page official NIST answer key with one false positive out of 33 findings.
How I built it
The core design decision is that the MCP server is the security boundary. Every forensic tool is exposed as a typed function with validated parameters. For example, if the agent wanted to run Volatility, it calls run_volatility(plugin="pslist", memory_path="..."), not a shell command. The server does not have a command execution interface, so there is nothing for the agent to exploit or misuse.
The second key decision is using a local database as a universal buffer. Raw tool output gets normalized into indexed rows in a per-case SQLite database with FTS5 full-text search. The agent never holds forensic output in its context window. It runs a tool, the results get chunked into 4,096-character windows and indexed, and then the agent queries the database for what it needs. This is what makes large cases tractable. The SRL-2018 investigation processed 120 GB of evidence across 11 systems with over 1,500 tool calls.
Anti-hallucination is handled at the API boundary. When the agent submits a finding, it must cite evidence_refs that are real tool_call_id values from the append-only audit log (audit log example). The server validates every reference before accepting the finding. If any ID doesn't match a real tool invocation, the submission is rejected. Every finding in the final report traces back through a provenance chain: finding to tool call to source file.
The container ships with everything needed to run: 35+ forensic binaries, Volatility symbol tables, 3,700+ Sigma rules for Hayabusa, YARA signature sets, and MITRE ATT&CK data. It supports Anthropic API, Vertex AI, Amazon Bedrock, and any LiteLLM-supported provider.
Challenges I ran into
Getting the agent to actually do thorough work. The hardest problem was not technical infrastructure. It was getting the agent to run enough tools before drawing conclusions. In early versions, the agent would see a suspicious process and immediately submit a high-severity finding without checking event logs, disk artifacts, or network captures. The planner/executor/analyst split helped by separating "what tools to run" from "what do the results mean." Quality gates helped by requiring minimum source counts before proceeding. But the biggest improvement came from the Alternative Narrative phase, which structurally forces a second look at every major conclusion.
Concurrency and SQLite. When the orchestrator runs parallel extractions across multiple systems, multiple threads write to the database simultaneously. SQLite doesn't support concurrent writers. Early versions hit constant SQLITE_BUSY errors. The fix was a dedicated writer thread with a queue: worker threads submit writes and block until completion, while WAL mode handles concurrent reads.
Dockerizing 35+ forensic tools. The container includes Volatility 3, Sleuthkit, Plaso, Hayabusa, YARA, Zeek, Suricata, ClamAV, radare2, EZ Tools, and many more. Some of these have conflicting dependencies. Some only build on specific architectures. The Dockerfile is not elegant, but it works.
What I learned
Architecture beats prompting for invariants. Prompts are good for guiding investigative strategy. Architecture is good for things that must never happen. "The agent cannot cite evidence that doesn't exist" is an architectural invariant, not a prompt instruction. The evidence-ref validation, the tool allowlists per role, the read-only evidence mount, the SQLite authorizer: these are all enforced in code. When the agent tries to submit a finding with a fabricated tool call ID, the server rejects it.
Self-correction needs its own phase, not a postscript. Building a dedicated adversarial phase with a separate agent and its own context produces actual corrections. The Alternative Narrative phase works because it's a separate pipeline invocation with a mandate to find counter-evidence, not a prompt appendix asking the agent to be careful.
What's next for Mulder
I'm not really sure; I suppose some of that will be driven by feedback from the DFIR community. If this is a tool that the community wants to use, I am absolutely interested in continuing to work on it and taking suggestions and contributions from others. I think there are many directions this project could go in, but I will need guidance from the community that may use it to determine what's next.




Log in or sign up for Devpost to join the conversation.