
Much_Sentiment
Project for UIowa Big Data Hackathon October 2016
Goal: How do the debates impact a candidate's chances for presidency?
As WashU students who were not selected to attend the presidential debate on October 9, we asked ourselves, how could we remain politically engaged while nnot being present at WashU's campus? We decided to analyze historical debate transcripts and try our hand at some natural language processing. We looked at the presidential debates starting from 1960 through 2012 to identify word frequency vectors, sophistication of diction, and sentence length to determine how the candidates presented themselves and their campaigns to the American people. We also looked at the effect of the debate performances on political polls (both before and after the debate), as well as the stock markets response.
We began by creating a schema for our MongoDB that would be both flexible and specific in terms of what data we might need to insert or query from it. In our database, we created three collections: speakers, debates, and performances. The speakers collection represents that candidates participating in the debates and includes information like their political party, whether they were the incumbent or not, and their home state. The debates collection covers information pertaining specifically to the transcript. This includes data like the word frequency vectors. The performance table holds data pertaining to the outcome of the debate (like the stock market's response and the political polls before and after the debate).
After agreeing on the schema, we set out to parse all of the different transcripts. We faced challenges such as having multiple moderators facilitate the debate, multiple names in reference to the same candidate, and an inconsistent html scheme used the same tags to identify laughter and speech, for example. We used beautiful soup to handle most of our data parsing and splitting, and a pymongo client to insert into the MongoDB. We tested as we worked through a Jupyter Notebook.
While we worked on parsing, we also worked on getting our application set up. At first, we decided on using NodeJS with an Express server to handle any API calls pertaining to the database. Unfortunately, we realized that none of us knew how to use the data we received to create visualizations in d3, so we ended up switching to a Python/Flask framework. This was more consistent with the rest of the work that we had done in our parsing, and allowed us to use tools like Bokeh to create interactive visualizations. We host our Flask application, called Much Sentiment, on the following Heroku server: (replaced by ec2 instance)
https://52.38.154.245:8888/tree/Much_Sentiment_Flask
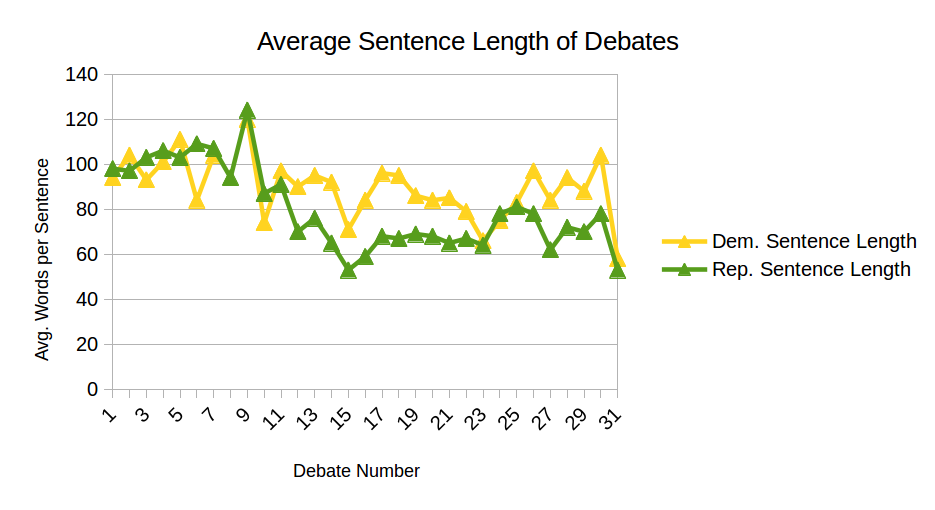
Based on the analysis we were able to complete, we did discover a statistically significant trend downwards in sentence length that continued on through the past month's debate. Sophistication of diction, on the other hand, did not show any pattern, contrary to our assumptions based on prevailing popular opinion.

Log in or sign up for Devpost to join the conversation.