

What is does
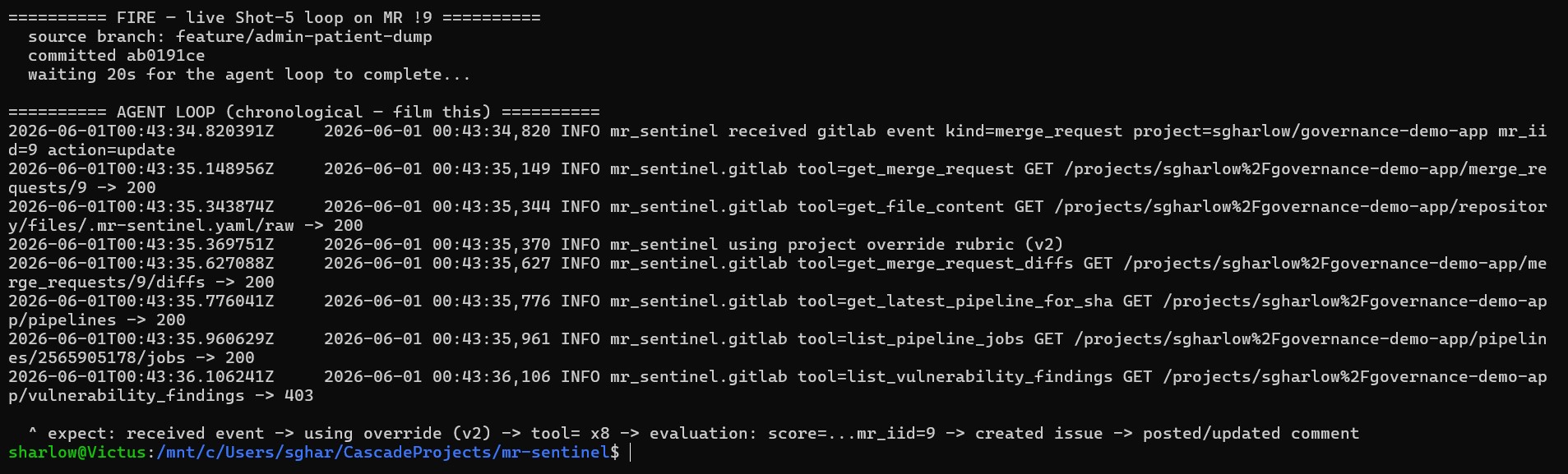
MR Sentinel watches your GitLab merge requests. When one opens, the agent runs a short deterministic plan against eight GitLab REST endpoints — pulling MR metadata, the diff, pipeline status, vulnerability scan, and (optionally) a project-specific rubric override at .mr-sentinel.yaml. It hands the diff to Vertex AI Gemini 2.5 Flash with the rubric inlined in the system prompt. Gemini returns a structured JSON verdict scoring each of the fifteen rules. The agent then takes real action against the MR:
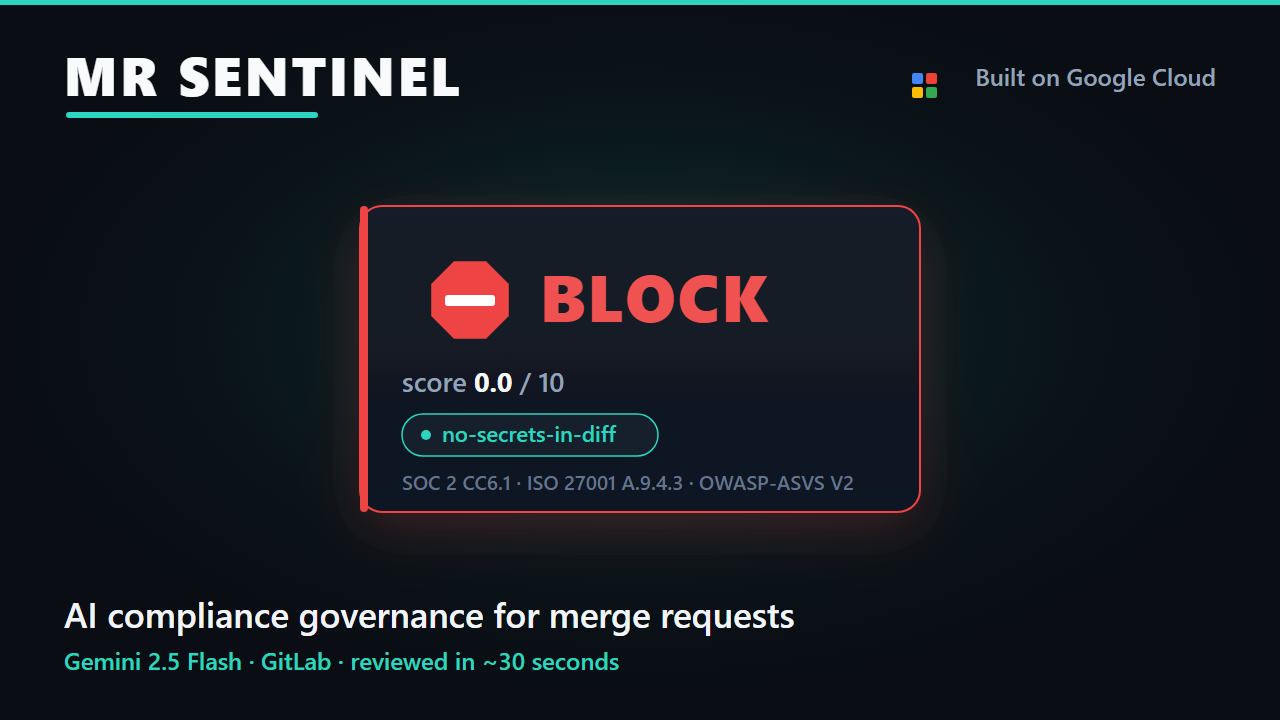
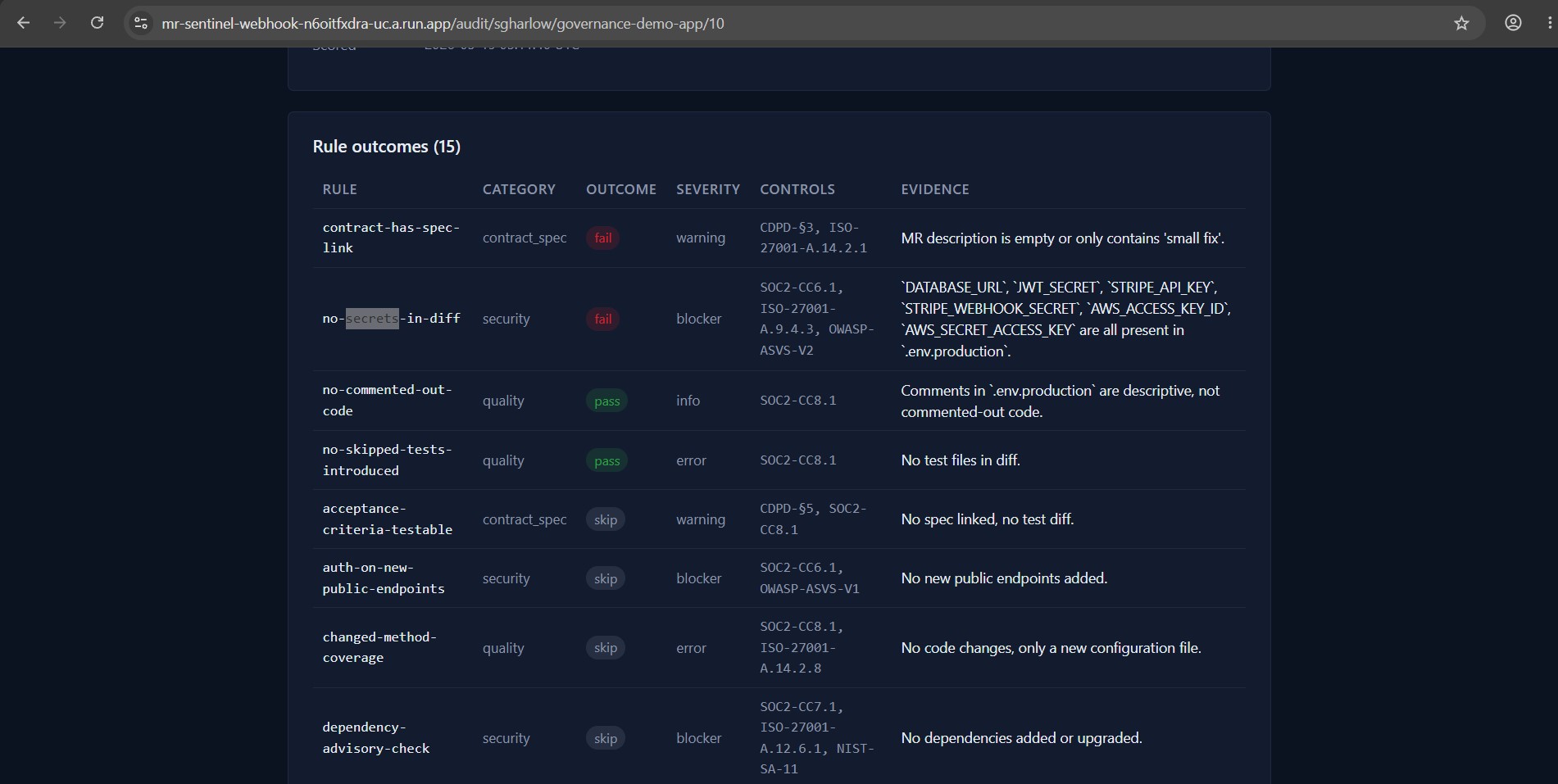
• A structured Markdown comment: verdict badge, score, every failing rule cited by ID with the exact evidence, and a collapsed pass/skip section.
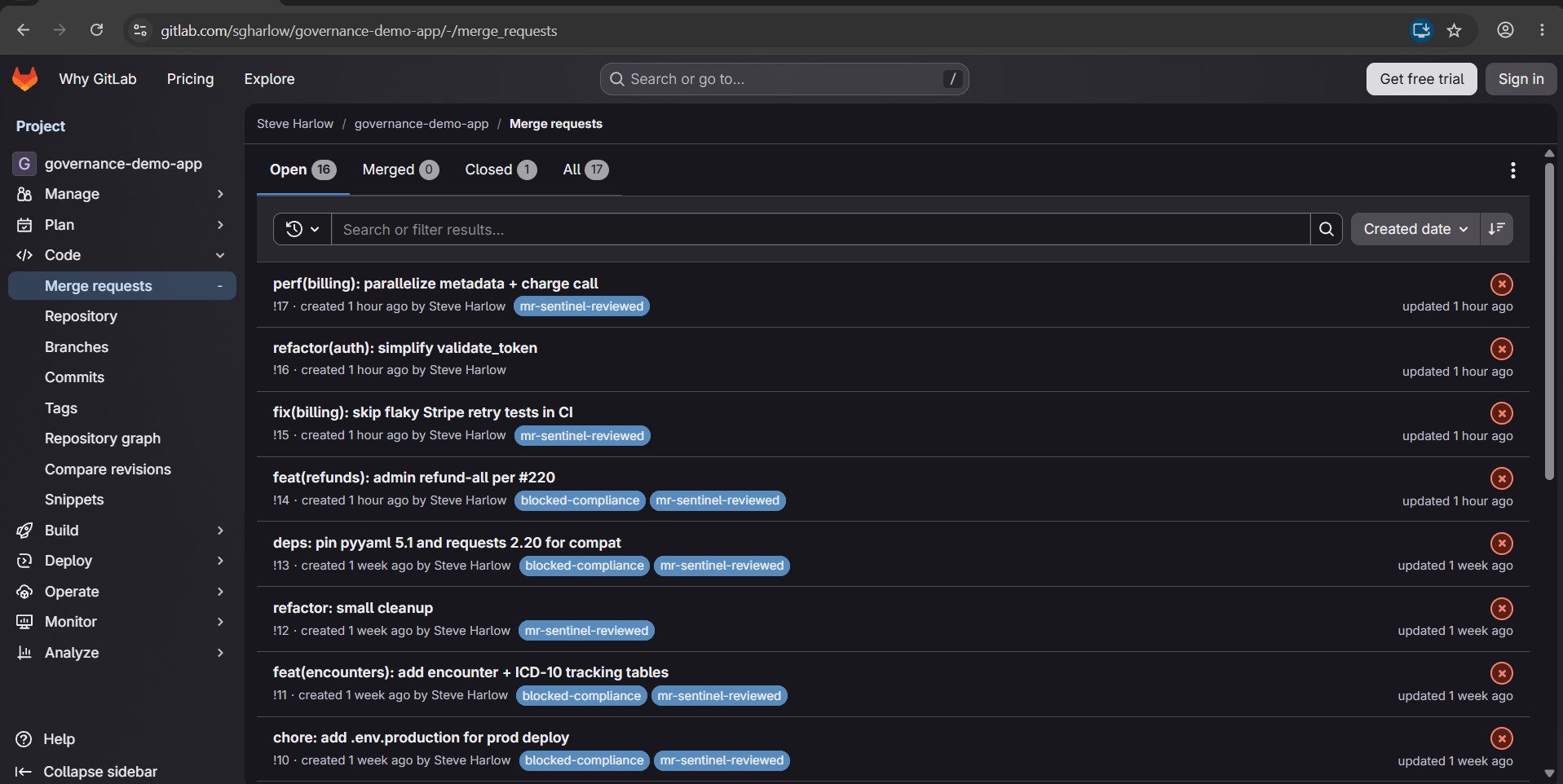
• A mr-sentinel-reviewed label, plus blocked-compliance on block verdicts.
• A linked remediation issue auto-opened with a checklist of failing rules.
• A row in mr_scores, child rows in rule_outcomes (control_mapping array preserved), and an audit_log entry.
Three surfaces, three personas:
• The MR author sees the structured comment in roughly twenty seconds — same surface as a human reviewer, but with consistent rule application and a paper trail.
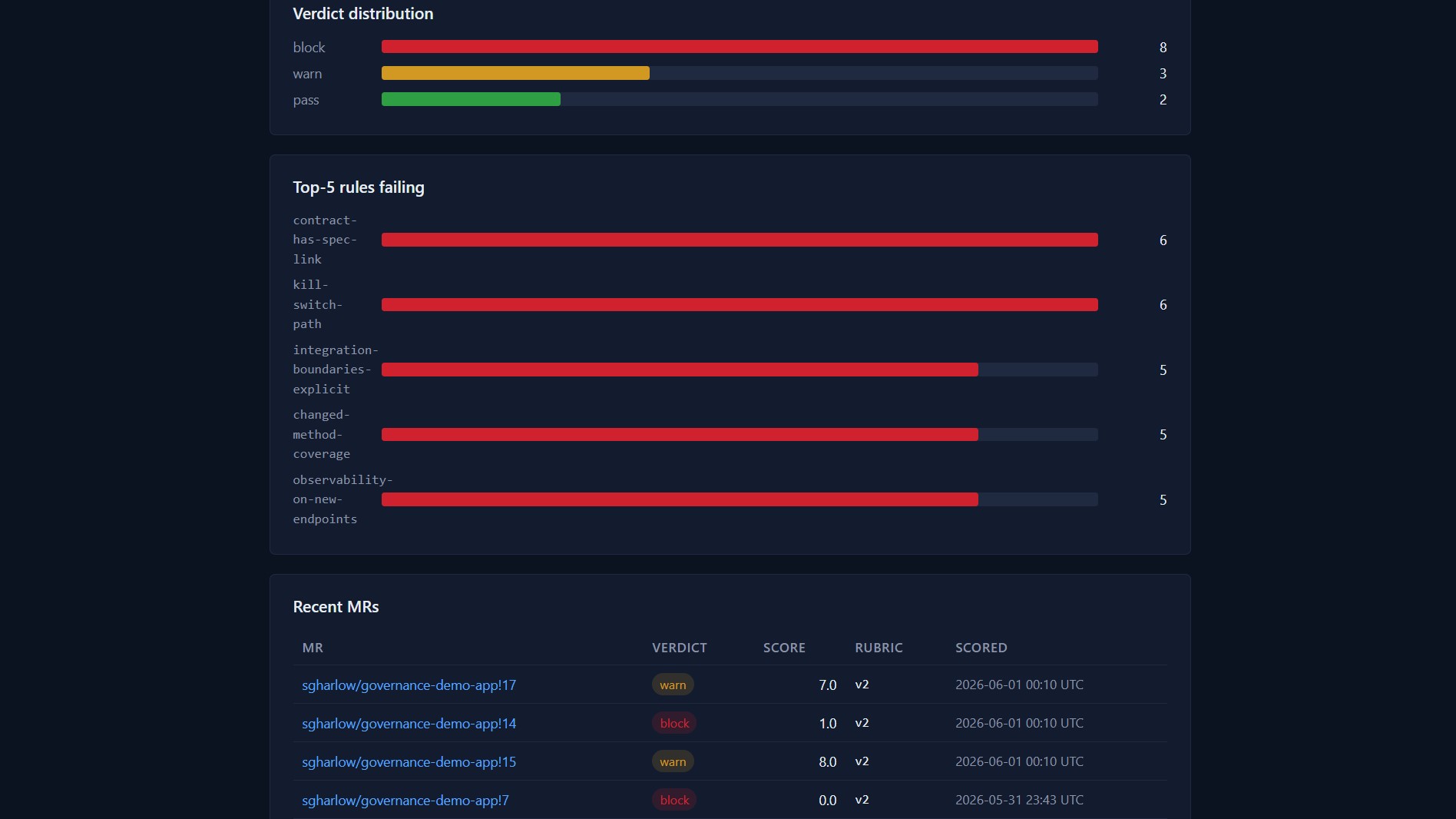
• The engineering leader opens /dashboard for a portfolio view: verdict distribution last 30 days, top-five failing rules, recent-MR drill-down.
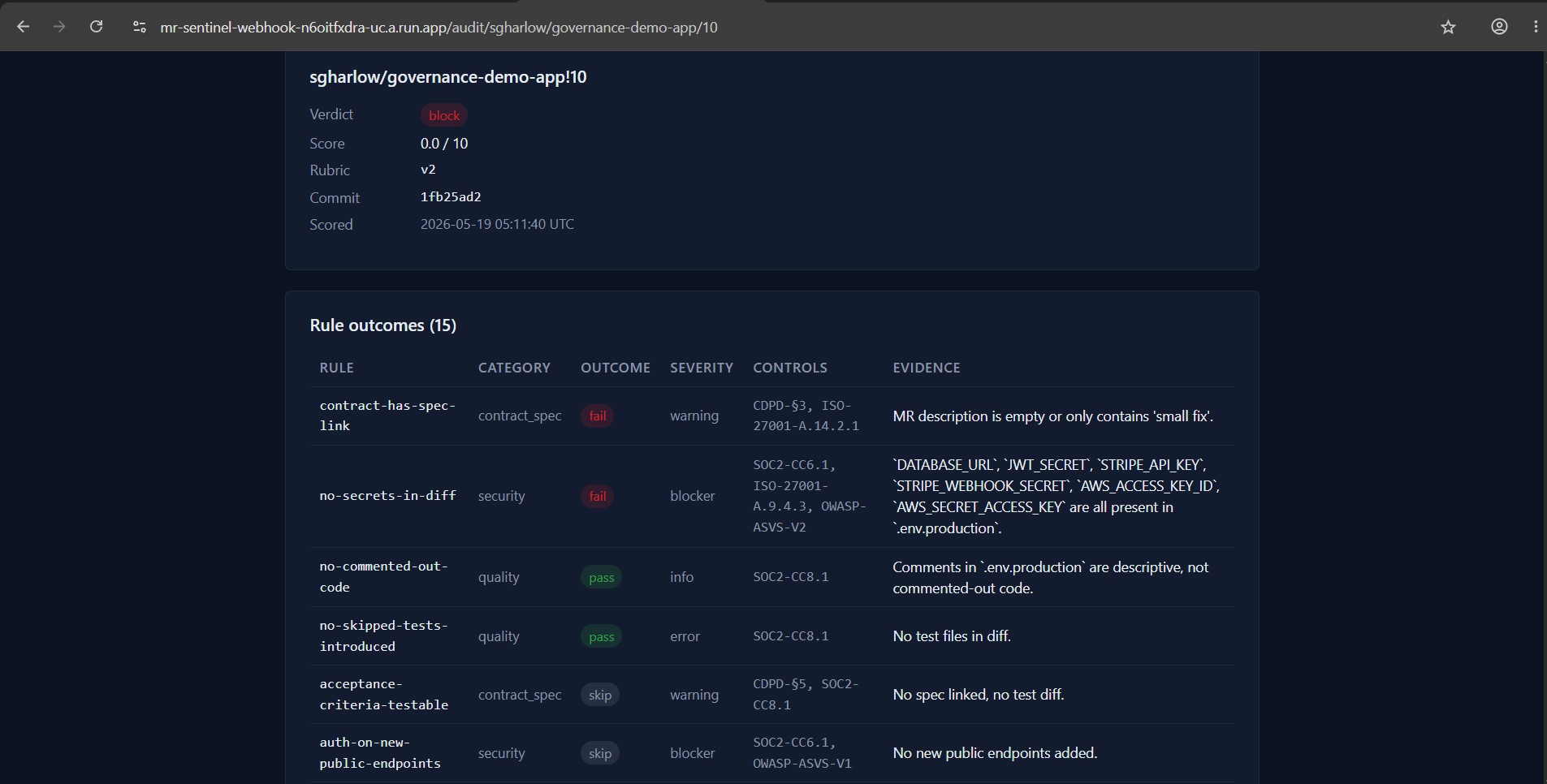
• The compliance auditor opens /audit/{project}/{mr_iid} — every rule outcome, every control mapping, the audit_log timeline, the exact prompt the agent used.
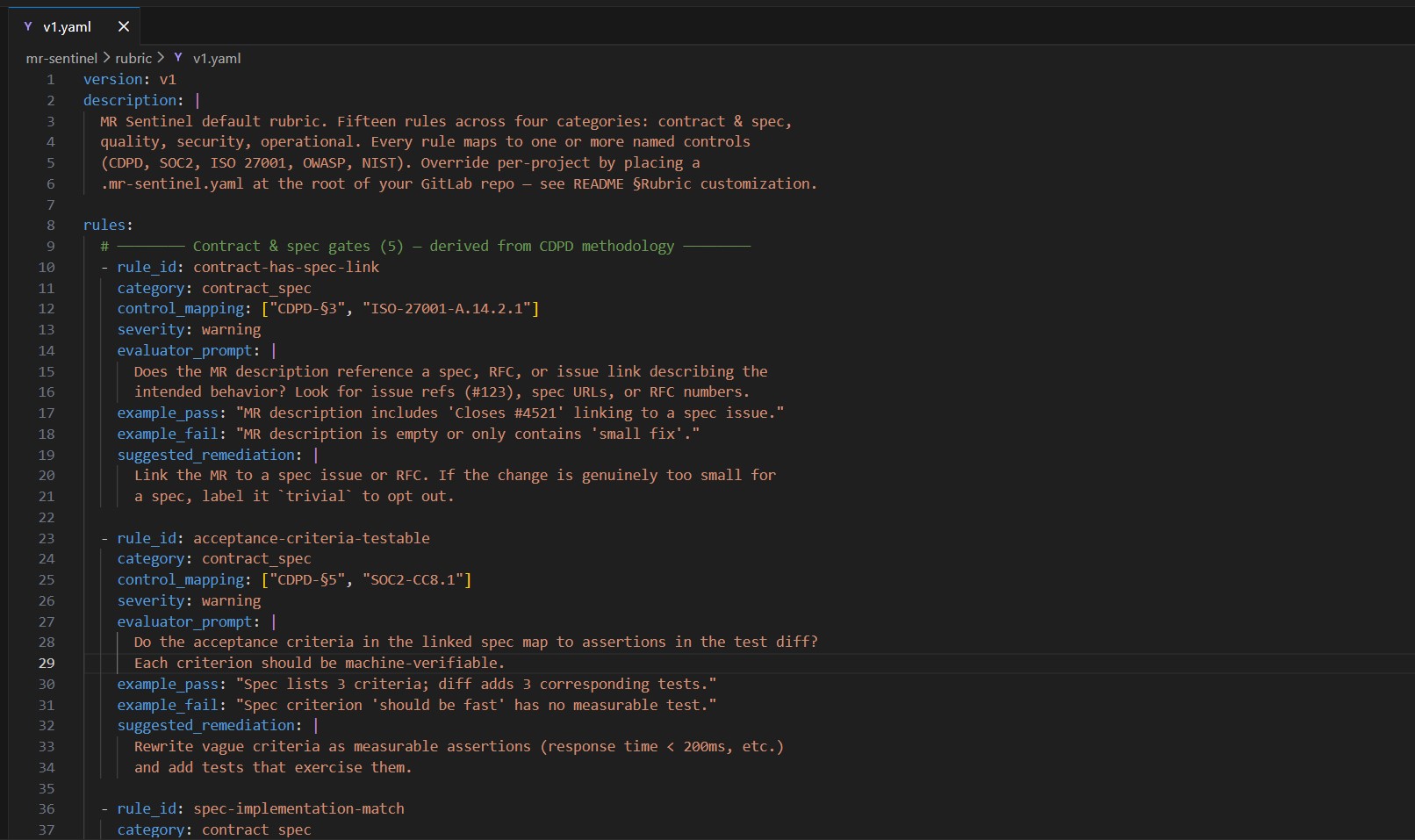
The rubric is the product's center of gravity. Fifteen rules across four categories: contract & spec gates (from the author's published CDPD methodology), quality, security, and operational gates. Every rule has a name, category, severity, control_mapping array, evaluator prompt, example_pass, example_fail, and suggested_remediation. Consumers override per project by dropping .mr-sentinel.yaml at their GitLab repo root; invalid overrides fail closed (fall back to bundled, audit the failure).
How we built it
Google Cloud, end to end. Cloud Run hosts the webhook and the leadership UI on one service. Vertex AI Gemini 2.5 Flash is the reasoning engine, called directly via the SDK with the rubric rendered into the system prompt. Cloud SQL Postgres 15 holds the scoring + rule_outcomes + audit_log tables. Secret Manager holds the webhook secret, GitLab PAT, and DB credentials. Artifact Registry holds the images; Cloud Build builds on every deploy.
The agent loop is plain Python — FastAPI with a background task. We chose the direct Vertex SDK over Agent Builder and the GitLab REST API over the GitLab MCP server. The rationale: for fifteen rules and eight deterministic tool calls, the orchestration is the agent. Plan → tool call → reflect → act is visible in Cloud Logging; the full evaluation is replayable from audit_log rows.
CI is GitHub Actions on the source repo: pytest plus rubric-schema validation. The webhook handler reads X-Gitlab-Token, constant-time compares against the secret, returns 202 Accepted, and dispatches a FastAPI BackgroundTask so the webhook latency budget is decoupled from the Gemini call.
The demo repo at gitlab.com/sgharlow/governance-demo-app ("Medbill" — fictional outpatient-billing SaaS) ships with archetypal MRs designed to trip each rule cluster: an auth-missing endpoint, a committed .env.production, an alembic migration with no rollback, a refactor with no spec link, a dependency downgrade with known CVEs. Every archetype produces a verifiable agent comment, label, and (on block) a remediation issue.
Challenges we ran into
Three real ones:
Spec drift. The spec promised Agent Builder, GitLab MCP, and Vertex AI Data Store. Three milestones in we'd built none — direct Vertex SDK, GitLab REST, inlined rubric were each pragmatic. Fix: reconciled spec to reality, framed the simplifications as deliberate.
Dedup vs override versions. Dedup was hardcoded to "v1," so once a consumer shipped a
.mr-sentinel.yamlwith a different version, every webhook re-fired a full Gemini call. Fix: resolve override first, dedup against active version.GitHub push protection caught the seed script's example AWS/Stripe patterns. We fragmented the pattern-shaped strings in source so the regex can't match; at runtime the fragments concatenate into the literal patterns Gemini flags in the diff.
Accomplishments we are proud of
The control-mapping framing turns this from "AI code reviewer" into "compliance-grade governance." Every comment ties back to a named control auditors recognize. The audit log is replayable end-to-end — same prompt, same diff, same response, persisted forever. The whole loop runs in about twenty seconds median (p95 under thirty) on Cloud Run scale-to-zero. The rubric ships as MIT-licensed reusable IP — any engineering organization can fork, customize the YAML, and run their own instance. 52 tests in CI, all green, no flakes.
What we learned
Two lessons. First: ship the spec to match the code, not the other way around. We caught ourselves writing a 15-section spec with rich architectural promises before we'd actually built a webhook handler. The discipline of reconciling spec to reality every milestone close kept the demo video honest. Second: the rubric is the product. Most "AI code reviewer" demos lead with the model. We lead with the methodology — the rubric is what makes this defensible as a compliance posture, not just a developer tool.
What's next for MR Sentinel
Post-hackathon: open the rubric to per-project rule additions (currently full-replacement only); wire pytest-cov gates; backdate the demo repo's commit history to a believable 60-day arc; explore Agent Builder as the orchestration layer when the rubric grows past fifty rules and per-project planning becomes non-trivial. The MIT license means engineering organizations can adopt the rubric framing today — fork, customize, run their own instance. Pull requests welcome after June 11.
Built With
- artifact-registry
- asyncpg
- cloud-build
- cloud-run
- cloud-sql
- docker
- fastapi
- gemini
- github-actions
- gitlab
- google-cloud
- jsonschema
- mit-license
- postgresql
- python
- secret-manager
- sqlalchemy
- vertex-ai
- yaml
Log in or sign up for Devpost to join the conversation.