-

Landing Page
-
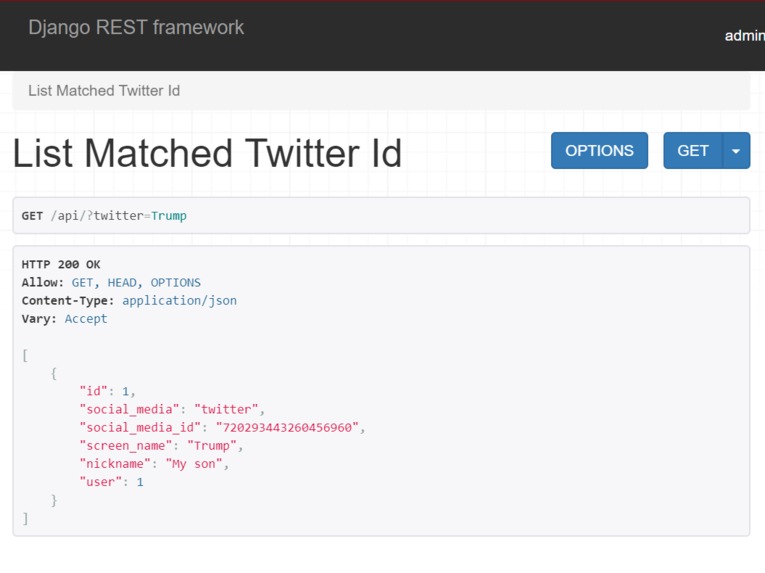
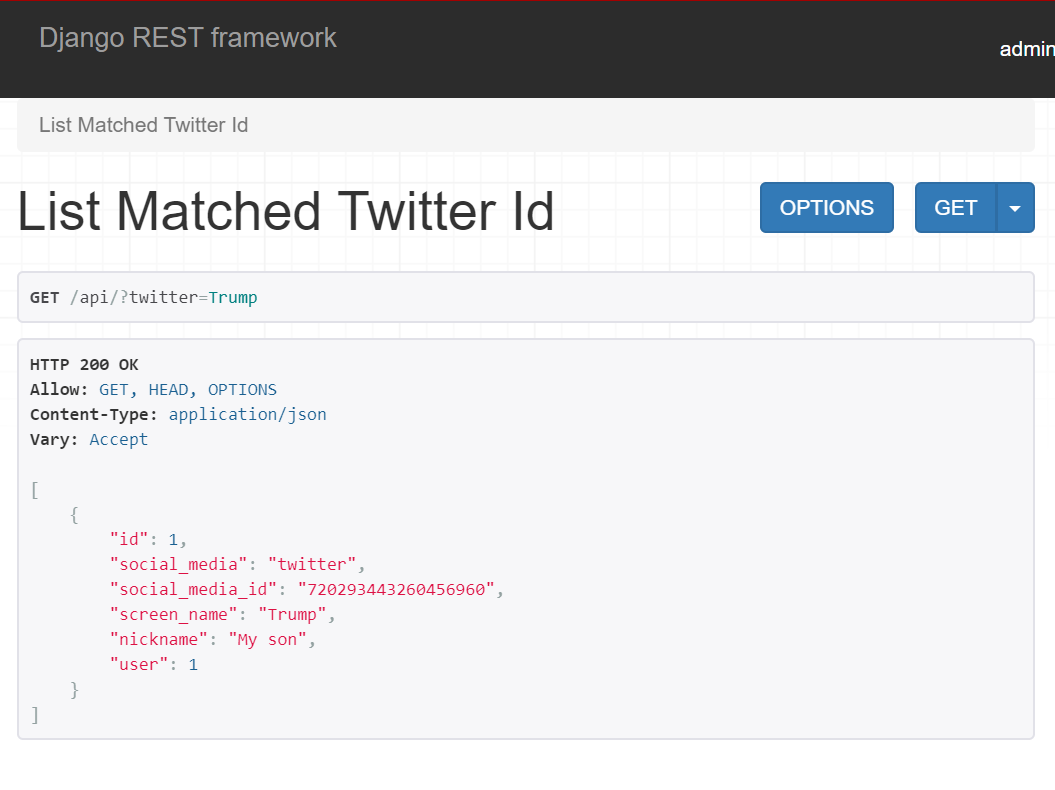
REST-API
-
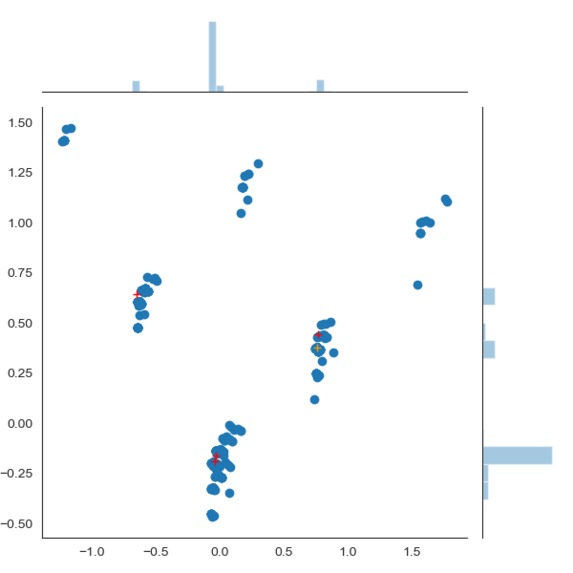
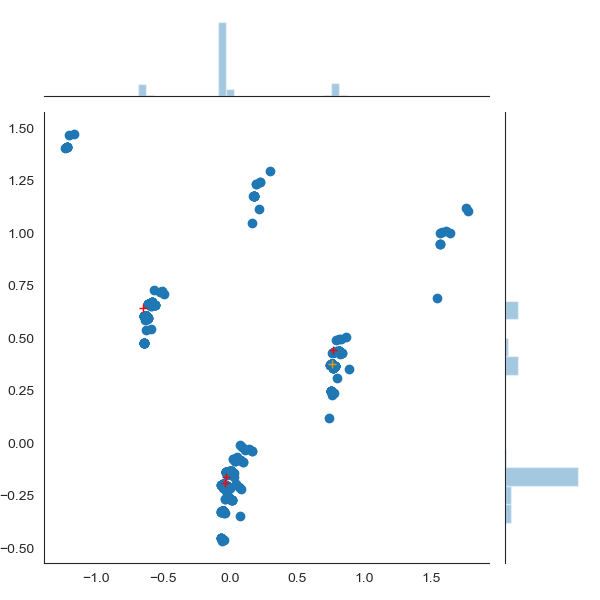
PCA-2D Projection Visualization with KMeans Clustering

Inspiration
People use twitter and provide a large amount of data, so when an anomalous tweet is made we can compare new tweets against their previous tweets.
What it does
Pulls training corpus from users twitter feed using twitter API. Sees if new tweets are anomalous compared to previous baseline using Scikit-Learn KMeans Clustering and PCA.
How I built it
Django-REST + Scikit-Learn
Challenges I ran into
Integrating Front/Back End. Data sparsity.
Accomplishments that I'm proud of
UI looks nice. KMeans Clustering kind of clusters in accordance with PCA projection.
What I learned
Django. Scikit-Learn PCA. Seaborn visualization.
What's next for Mpathy
Integrate all components. Deploy it using GCP.


Log in or sign up for Devpost to join the conversation.