Inspiration
In today’s day and age algorithms are driving everyone's lives. Entertainment is recommended by large models optimising for watch time and profit with no regard for the human experience. We want to change that and put choice back in the hands of real people.
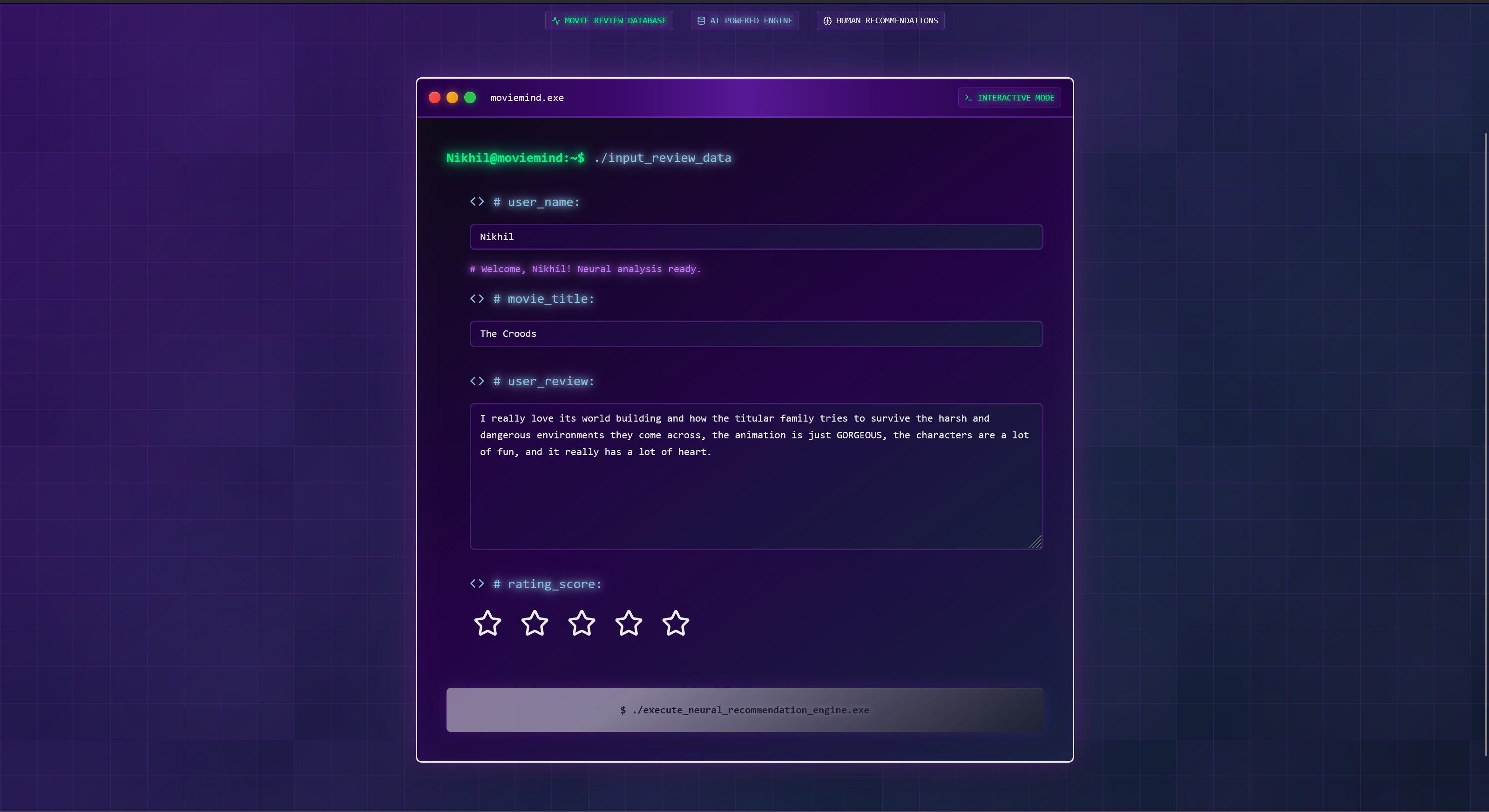
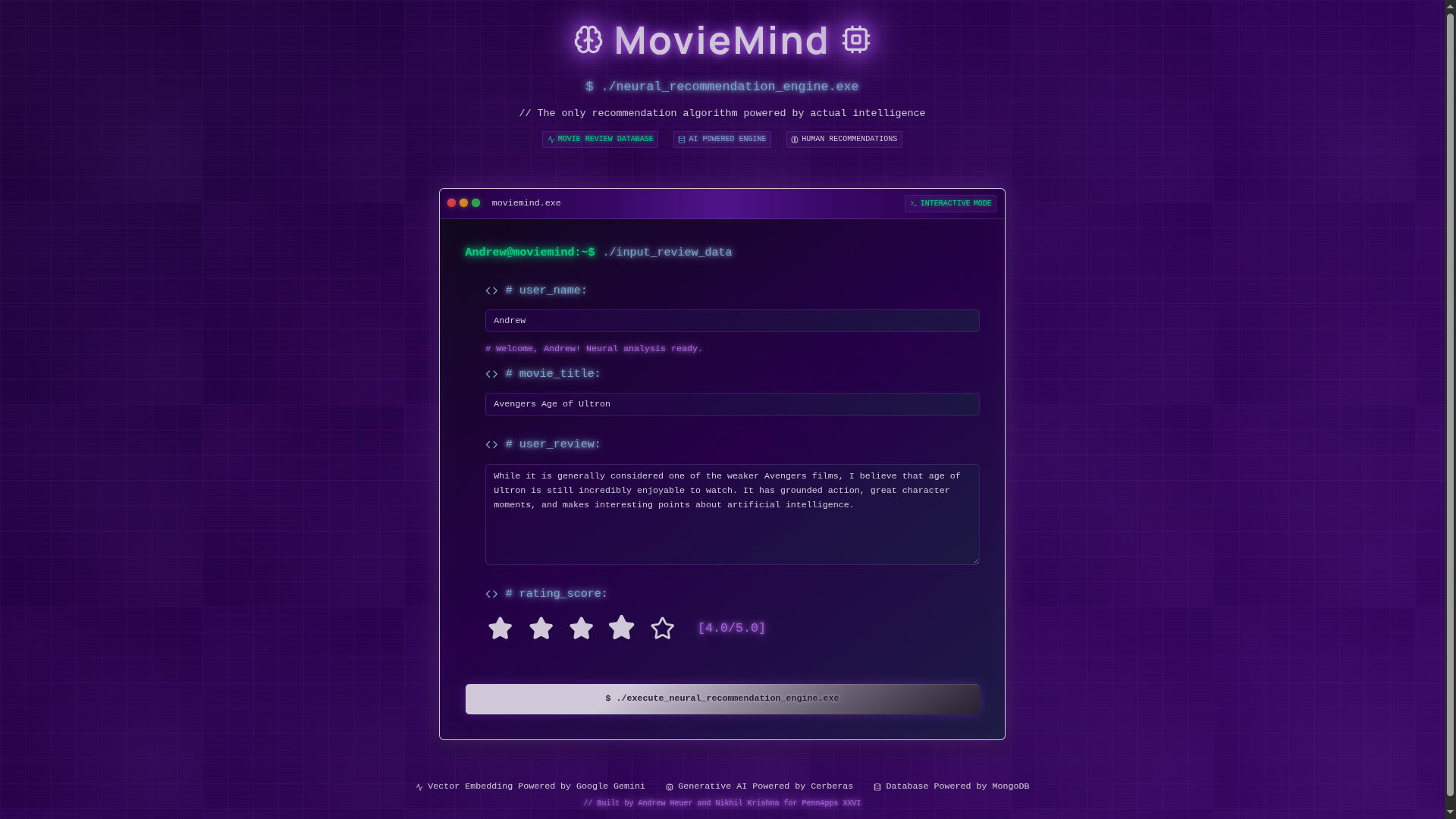
What it does
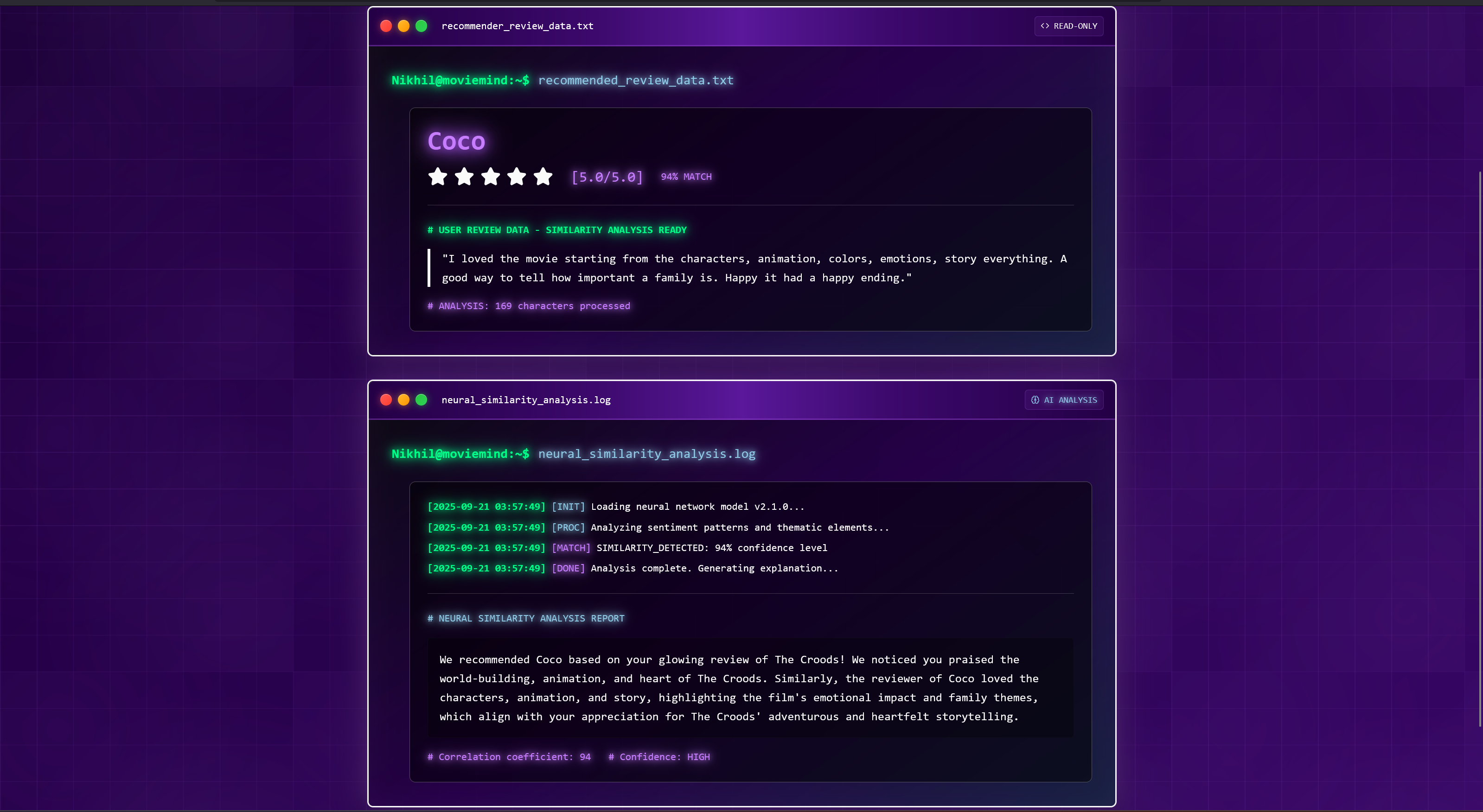
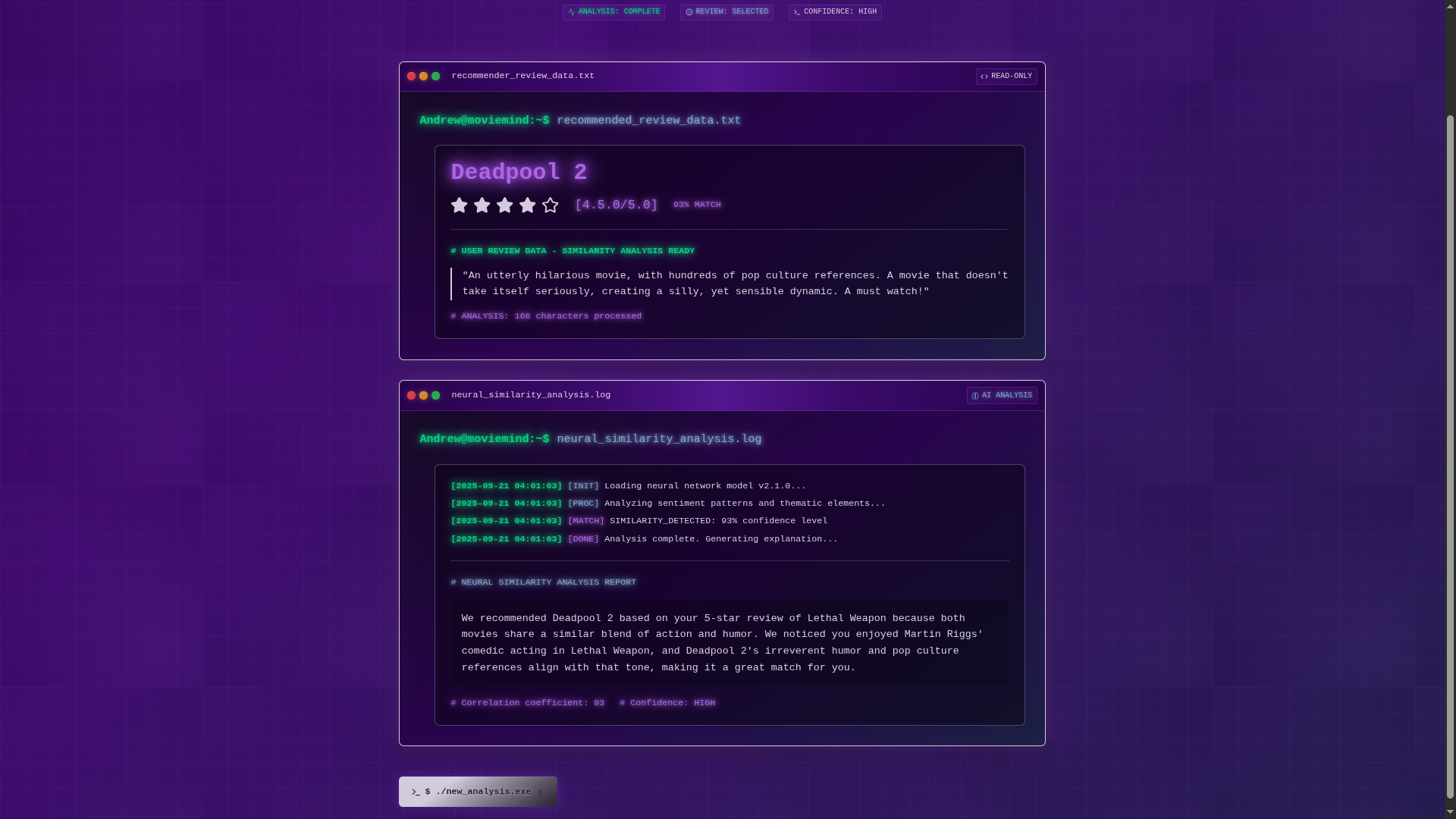
We take in user reviews of movies they like and use the reasons they like them to find movies other people like for the same reasons. We used vector embeddings of reviews to find the most semanticly similar reviews to the user’s input, then find the most positive reviews of that group to determine our recommendation. We then have an LLM explain our rationale to give users insight into the reasons for the suggestion.
How we built it
We use MongoDB for our vector database and semantic search. To avoid the cold start problem, we pre-populated our database with reviews of popular films from TheMovieDB.org. We use the gemini-embedding-001 model from the Google Gemini API to generate the vector embeddings of our reviews. To provide the user context at extremely low latency, we use Cerebras for our generative text functionality. We build our webpage with Next.js and are hosting it on Vercel.
Challenges we ran into
We started the hackathon pursuing a different idea but we had to scrap it because data that we needed was completely unavailable due to big pharma. We then pivoted to a completely different track and tech stack to build MovieMind. There were a number of technical challenges we had to solve for this concept including collecting the necessary data and finding the most optimal embedding model. One recurring issue was that a few very general reviews would get matched with a disproportionate amount of inputs because of a lack of reviews with more specifically in common with those inputs. We realized that the best way to address this problem was to scale up our dataset which resulted in a series of interesting challenges like using Google’s batch API, and having to space out our requests to avoid rate limiting.
Accomplishments that we're proud of
We are very proud of our antifragility and how our team was able to pivot part of the way through the hackathon and deliver a very high quality product. We also take pride in how we were able to bring together so many disparate services and get them to cleanly integrate as part of a larger product.
What we learned
We learned a number of new technical skills involving Artificial Intelligence, databases, and vector embedding. We also learned how many challenges in machine learning projects come from acquiring the data you need and a number of ways to approach those challenges. Overall, this has been a great experience and we look forward to applying the knowledge we have gained to other areas of our lives.
What's next for MovieMind
The service could be expanded significantly by making a user account system, keeping track of a database of movies, and scaling up all of our infrastructure. There are also improvements to be made with our semantic search and embeddings to improve our ability to find reviews with similar content regardless of differing writing styles.



Log in or sign up for Devpost to join the conversation.