-
-
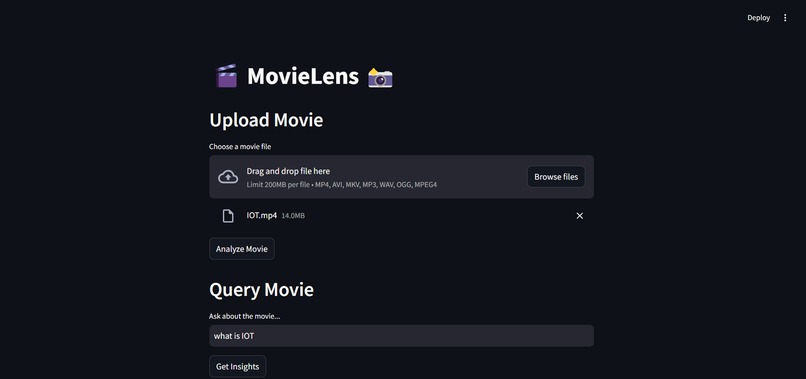
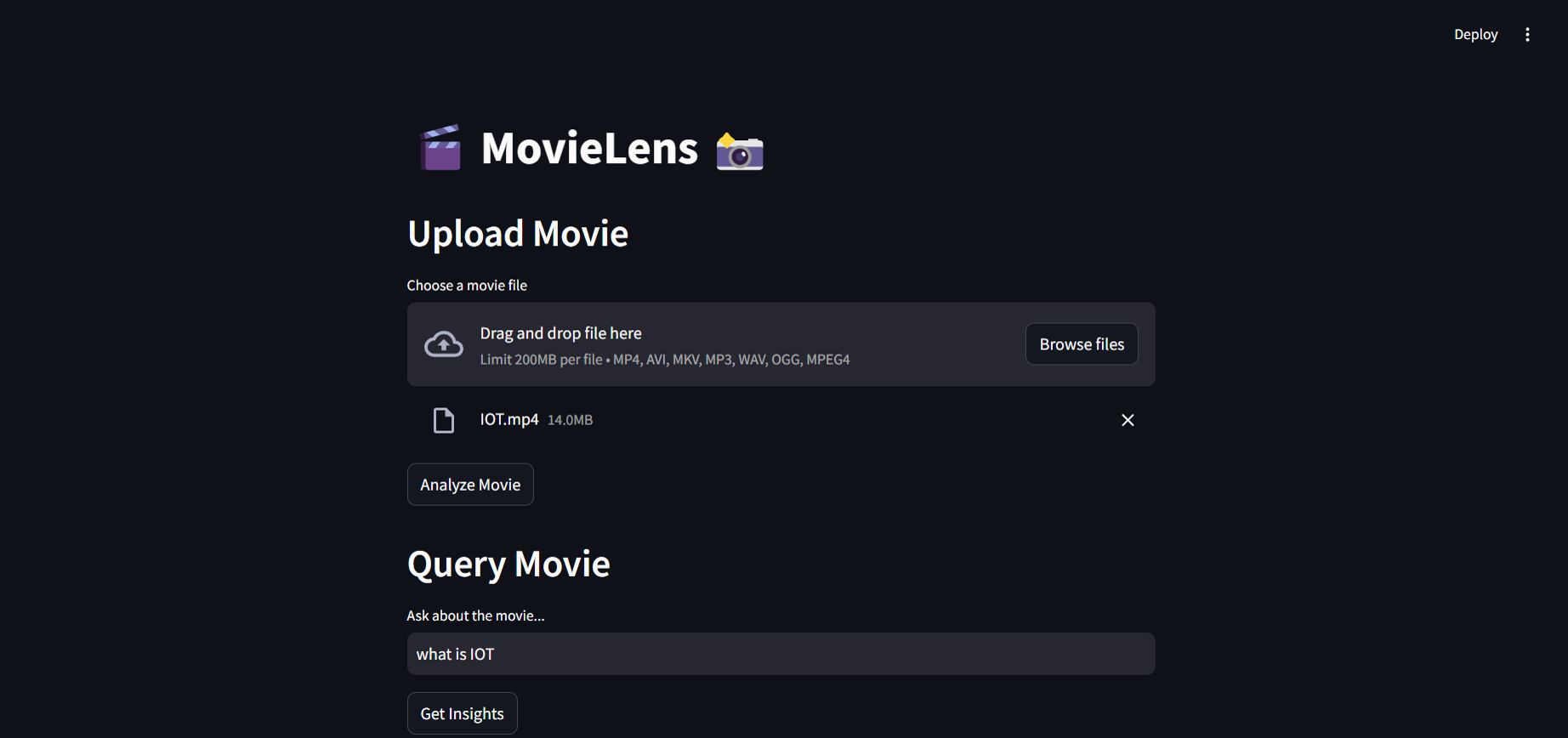
Home Page
-
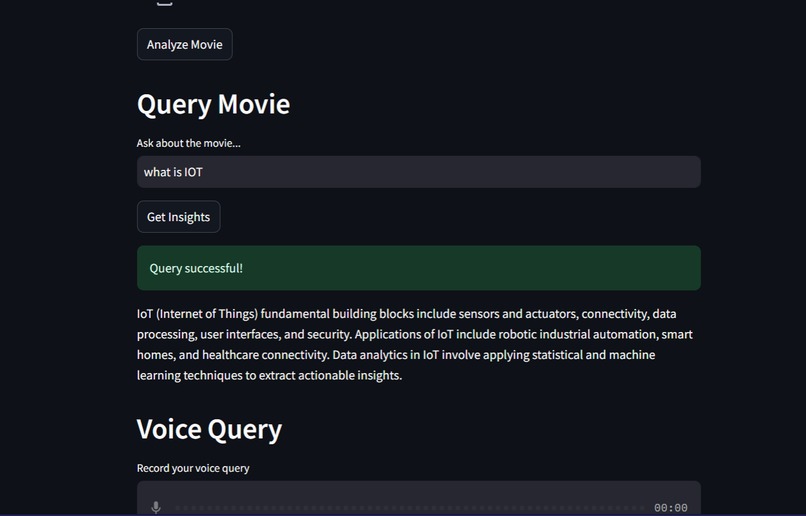
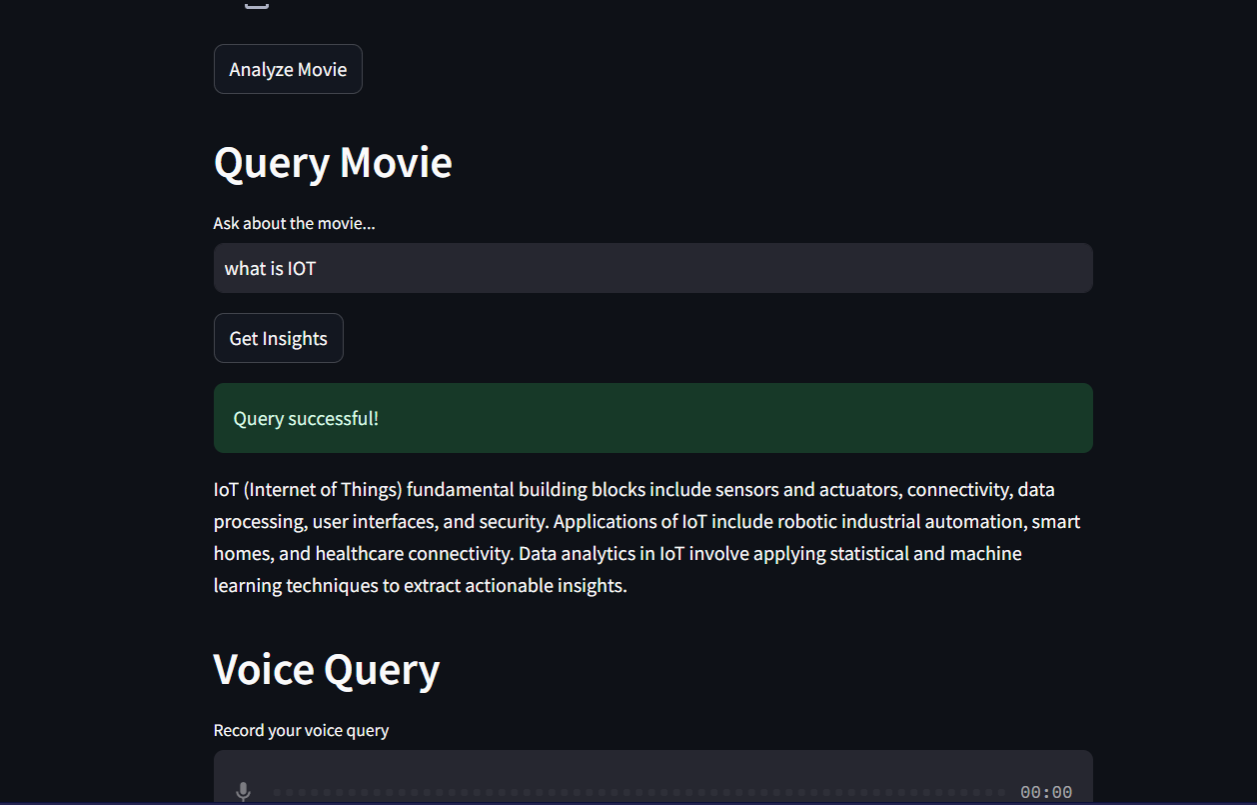
Query
Inspiration
The inspiration for MovieLens came from the growing need to make movie content more accessible and analyzable. With the explosion of streaming services and digital content, I recognized the need for a tool that could not only process movie content but also provide intelligent insights about it. I wanted to create something that could bridge the gap between passive movie watching and active content analysis including multilingual capabilities.
What it does
- Processes uploaded movie files and extracts audio content
- Transcribes dialogue and conversations using AssemblyAI's advanced speech recognition
- Automatically identifies and extracts key points and themes from the content
- Provides a natural language interface for users to ask questions about the movie
- Leverages multiple AI models (SambaNova, Google Gemini) to generate insightful responses
- Stores and retrieves information efficiently using ChromaDB's vector database
How i built it
- Designed a FastAPI backend to handle file uploads and processing
- Integrated AssemblyAI for high-quality audio transcription
- Implemented vector storage using ChromaDB for efficient semantic search
- Utilized multiple AI models:
- SambaNova's Llama model for generating responses
- Cohere for generating embeddings
- Created an intuitive user interface for seamless interaction with streamlit
Challenges i ran into
- Handling large movie files efficiently without overwhelming system resources
- Coordinating multiple AI services while maintaining reasonable response times
- Implementing proper error handling for various API failures
- Optimizing the vector database for quick and accurate retrievals
- Balancing between response quality and processing speed
- handling multilingual text processing
Accomplishments that i am proud of
- Successfully integrating multiple cutting-edge AI technologies into a cohesive system
- Creating a user-friendly interface for complex AI interactions
- Achieving high-quality transcription and analysis results
- Implementing efficient vector storage and retrieval mechanisms
- Building a scalable architecture that can handle various movie formats
- The application is build with multilingual text in mind to make the better reach and accessibly
What i learned
- Working with state-of-the-art AI models and APIs like assembly ai , SambaNova's LLM
- Managing and processing large media files
- Implementing vector databases for semantic search
- Handling asynchronous operations in FastAPI
- Balancing system resources and performance
- Coordinating multiple AI services in a single application
What's next for MovieLens
- Add feature to give users timestamp of the searched scene
- Enhanced user interface frontend with real-time processing updates
- Batch processing for large movie files
- More robust error handling
- Caching mechanisms for faster responses
Built With
- assemblyai
- chromadb
- cohere
- fastapi
- sambanova
- streamlit

Log in or sign up for Devpost to join the conversation.