Inspiration
We've all been there: a half-remembered scene from a childhood movie stuck in your head, or a fascinating clip on social media without a title. Existing search tools and recommendation algorithms are terrible at this; they suggest similar movies but rarely the exact one based on plot details. Our inspiration came from the frustration of wanting to find a specific film without knowing its name, leading us to build a precise solution for this universal problem.
What it does
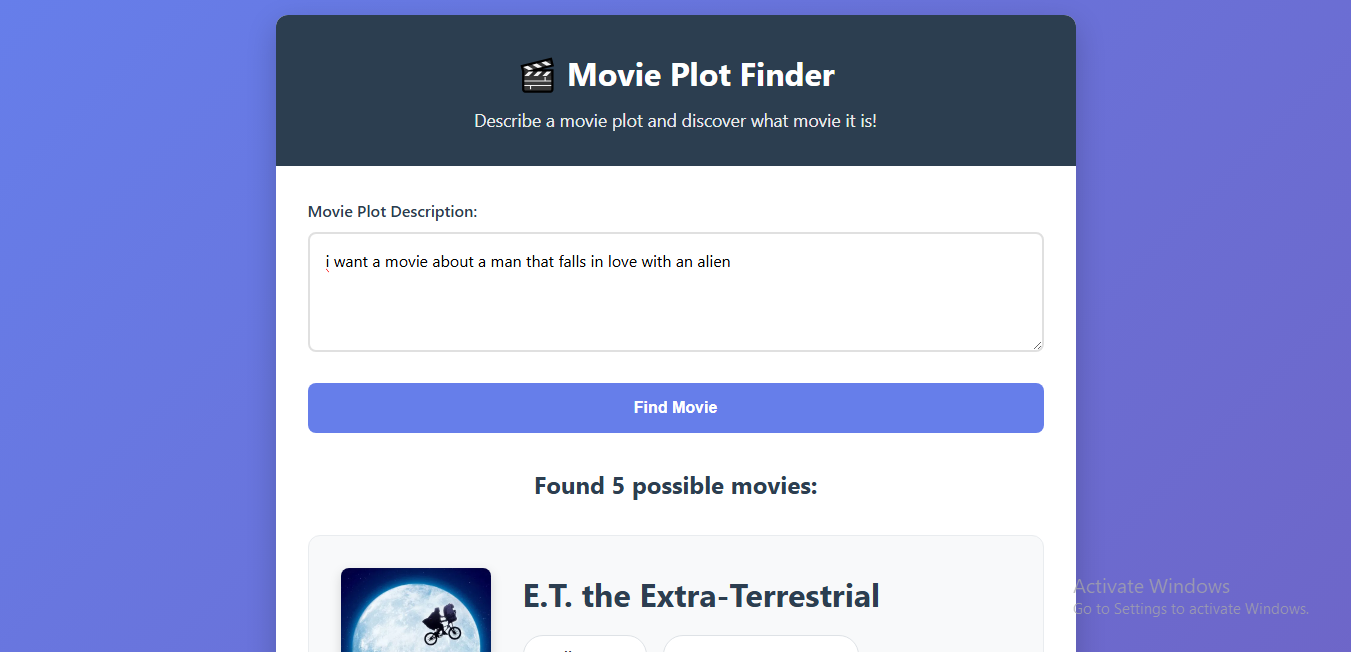
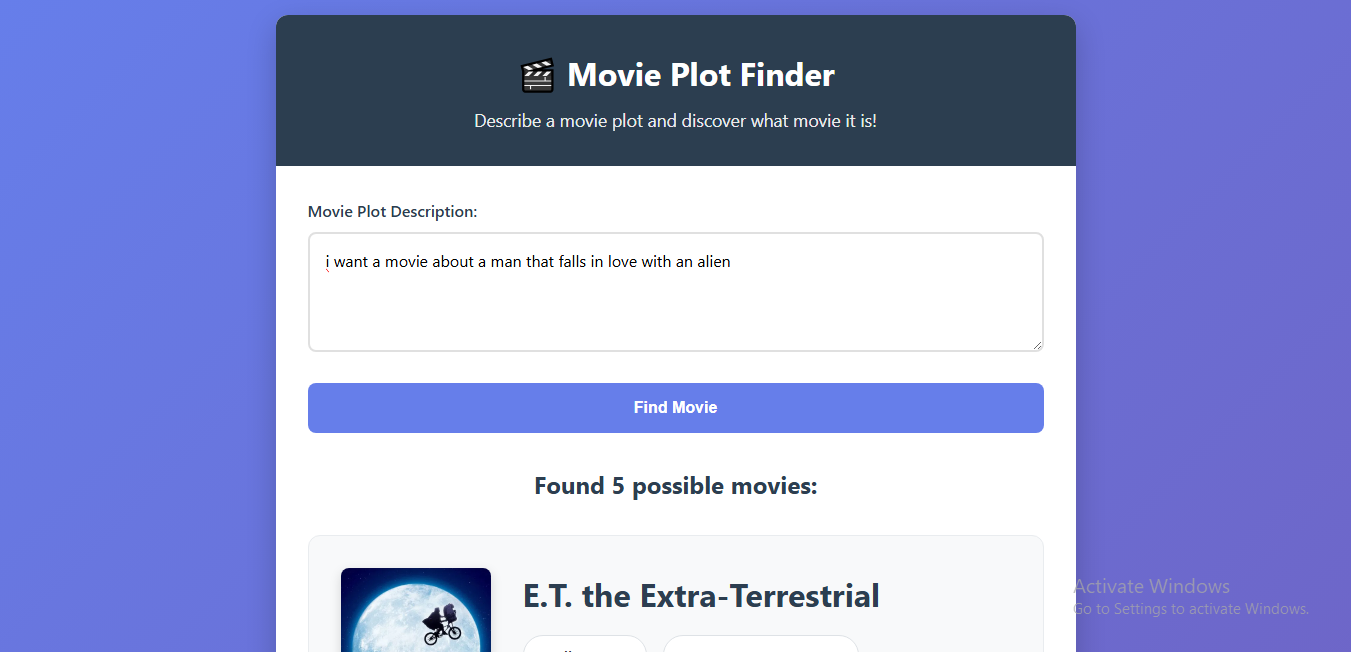
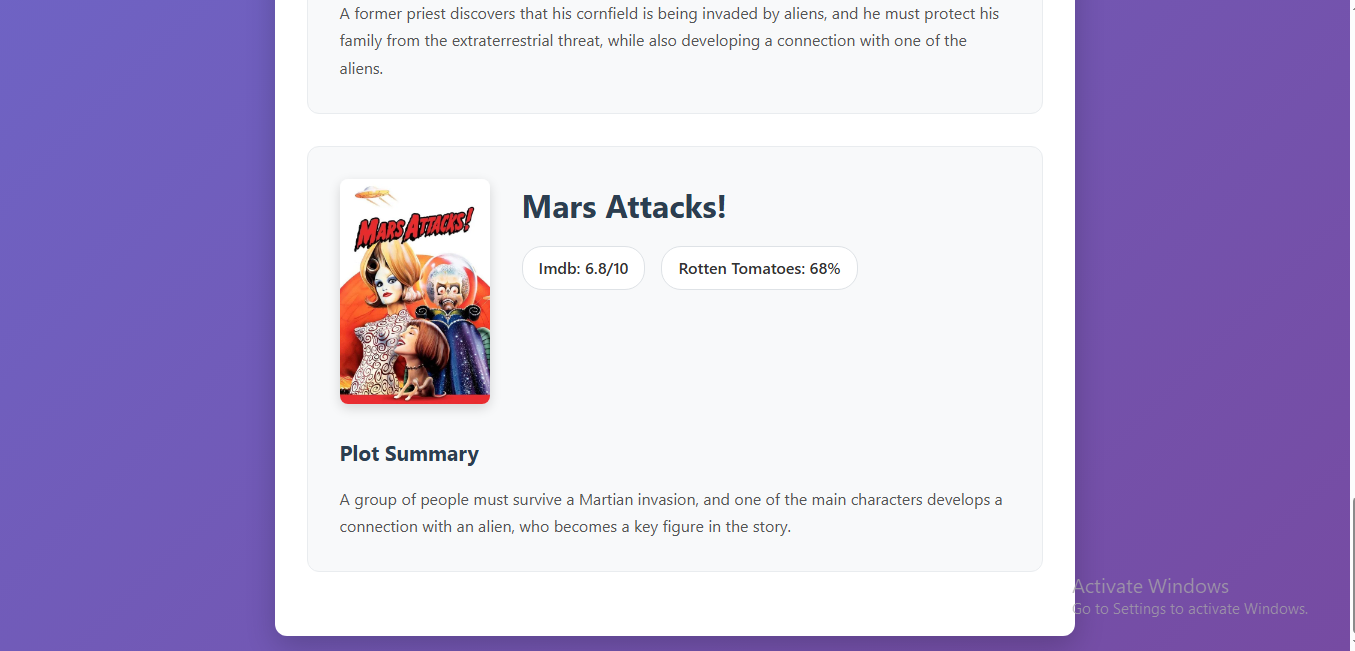
MovieFinder is a web-based tool that allows users to input a natural language description of a movie's plot, scene, or even a vague memory of a character. Our AI then analyzes the description and returns the most likely movie title, along with a confidence score and key details. It's like a search engine for your movie memories.
How we built it
Frontend: Built a simple, intuitive user interface using HTML and CSS to allow users to type their query and view results.
AI Core: Leveraged GROQ LLAMA MODEL for its superior natural language understanding capabilities. We engineered specific prompts and fine-tuned the system's parameters to prioritize factual movie identification over creative generation.
Data: Augmented the AI's knowledge with a curated dataset of movie plots to improve accuracy and minimize false positives.
Challenges we ran into
AI Output Formatting: The biggest challenge was configuring the AI to consistently produce clean, structured data (just the movie title and year) instead of conversational sentences or explanations. This required extensive prompt engineering and output parsing.
Balancing Specificity and Recall: Tuning the system to find very obscure movies without overfitting and getting false positives for popular ones was a delicate balancing act.
Integration Hurdles: Smoothly connecting the frontend, backend, and the external AI API within the hackathon's time constraints presented a significant integration challenge
Accomplishments that we're proud of
AI Output Formatting: The biggest challenge was configuring the AI to consistently produce clean, structured data (just the movie title and year) instead of conversational sentences or explanations. This required extensive prompt engineering and output parsing.
Balancing Specificity and Recall: Tuning the system to find very obscure movies without overfitting and getting false positives for popular ones was a delicate balancing act.
Integration Hurdles: Smoothly connecting the frontend, backend, and the external AI API within the hackathon's time constraints presented a significant integration challenge
What we learned
Prompt Engineering is Key: We gained deep practical experience in crafting effective prompts for Large Language Models (LLMs) to steer their behavior for specific tasks like factual lookup.
The Importance of the User: Building something for a pain point we personally understood was the best motivation and guide for development.
API Integration & Error Handling: We learned how to robustly handle API limits, network errors, and unexpected responses from third-party services to create a stable user experience.
What's next for MovieFinder
Enhanced Accuracy: Incorporate a dedicated movie database API (like TMDB) to cross-reference results and drastically improve accuracy and information depth.
Image & Video Input: Allow users to upload a screenshot or a short video clip from a movie to find its title.
Community & Memory Features: Build a community page where users can share their "lost and found" movie stories and save their search history.
Mobile App: Develop a native mobile app for iOS and Android to make finding movies on the go even easier.
Built With
- css
- groq
- html
- javascript
- kiro
- tmbd

Log in or sign up for Devpost to join the conversation.