-
-
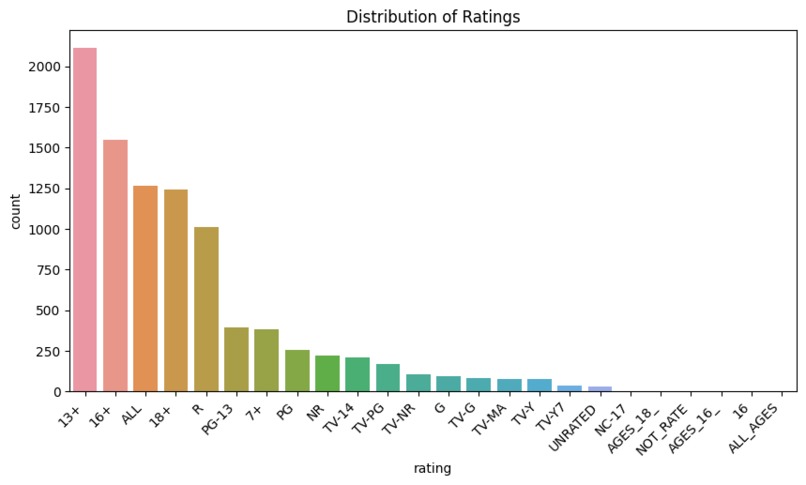
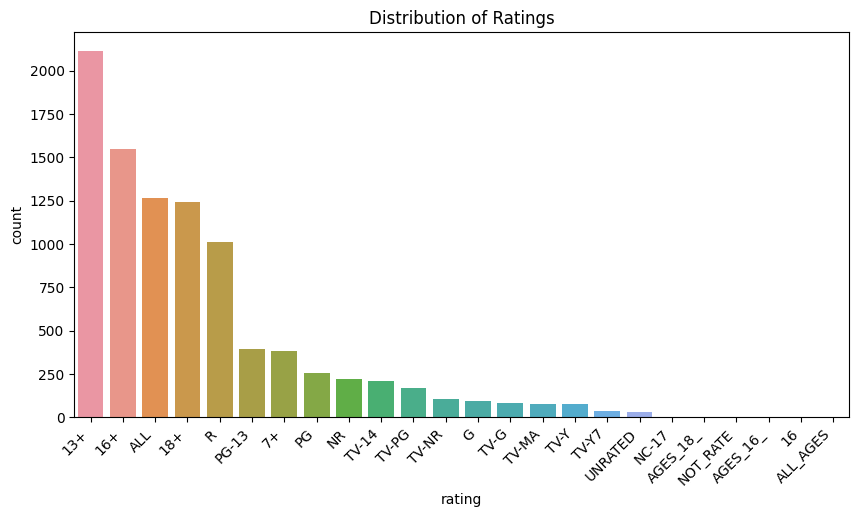
Rating distribution
-
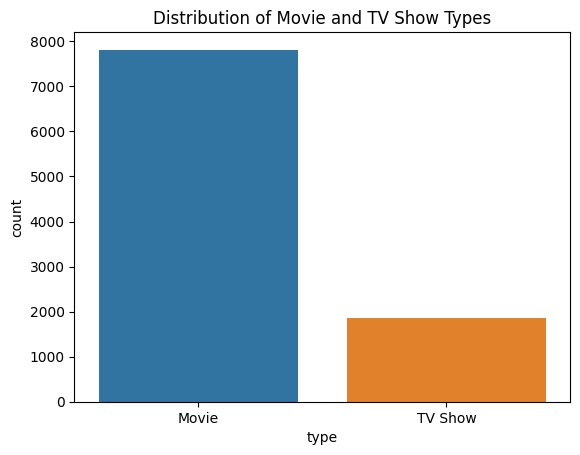
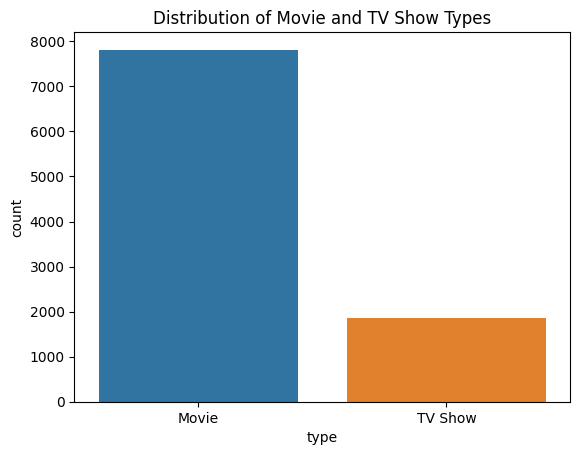
Distribution of 'type' (Movie or TV Show)
-
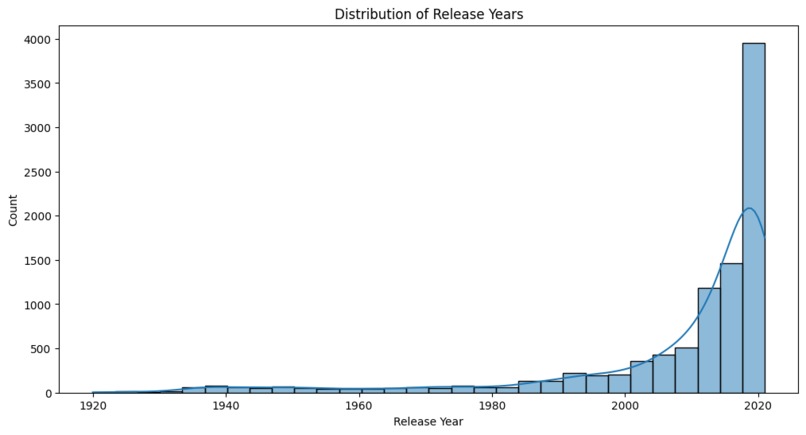
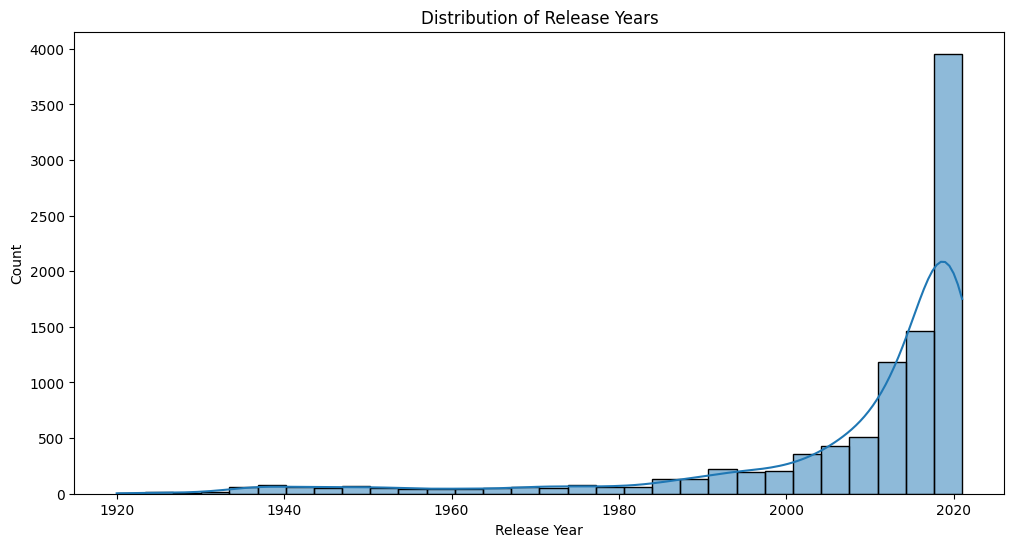
Release year distribution
-
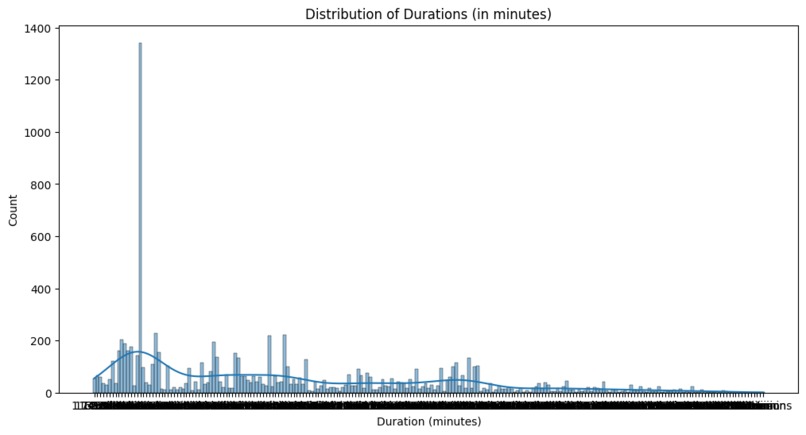
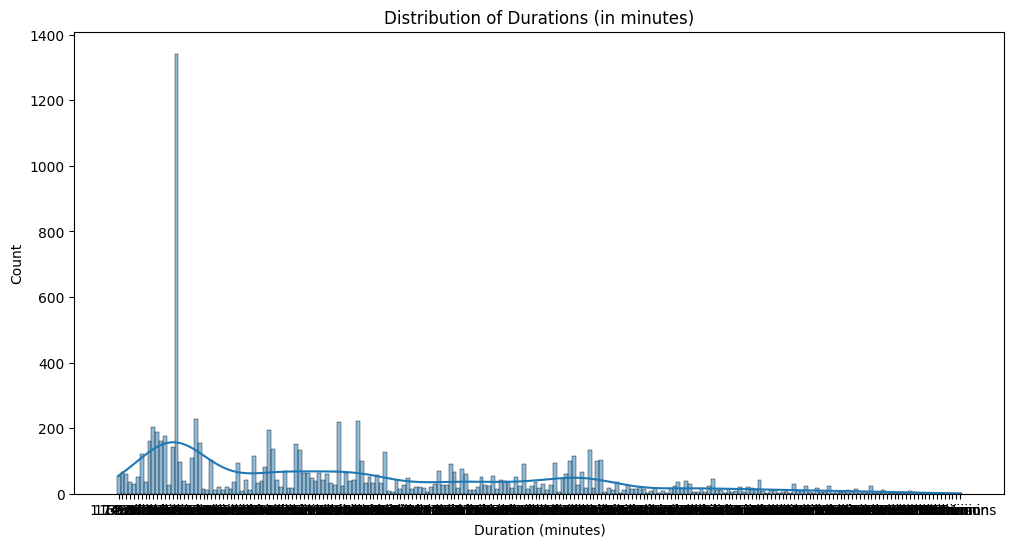
Duration analysis
-
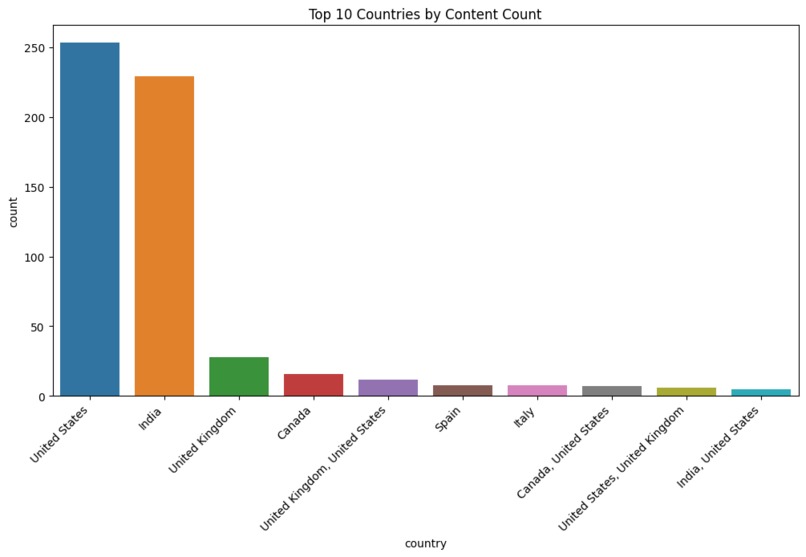
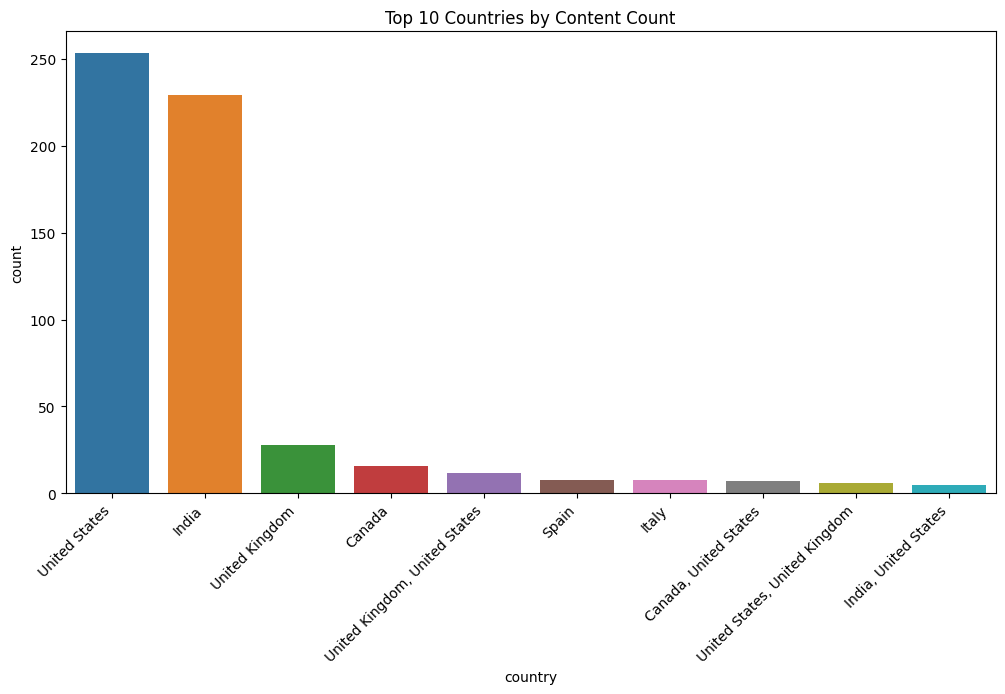
Distribution of content by country
Movie Recommender Project Story
Inspiration
The inspiration for our Movie Recommender project came from our shared passion for movies and our curiosity about how recommendation systems work. We wanted to create a movie recommendation system that could offer personalized movie suggestions based on user preferences, similar to what popular streaming platforms provide.
What It Does
Our Movie Recommender is designed to analyze a dataset of movie and TV show titles, and based on user input, it recommends movies that match the user's criteria. Users can specify preferences for content age, duration, rating, and type (Movie or TV Show). The system filters the dataset to provide a list of recommended movies that align with these preferences.
How We Built It
The project was developed in Python and utilized several libraries and frameworks:
- Pandas: We used Pandas for data manipulation and analysis, loading the dataset, and data preprocessing.
- Matplotlib and Seaborn: These libraries were employed for data visualization to gain insights into the dataset.
- scikit-learn: We used scikit-learn to perform TF-IDF vectorization and calculate cosine similarity for building the recommendation system.
- TensorFlow and Keras: For the recommendation model, we implemented a basic neural network using TensorFlow and Keras.
The project followed a structured workflow:
- Data was acquired from a CSV file containing information about Amazon Prime titles.
- Data exploration helped us gain a deep understanding of the dataset and its attributes.
- We performed feature engineering, creating the 'content_age' feature and transforming the 'duration' column for accurate analysis.
- A basic recommendation system was implemented based on user preferences.
- Text data in item descriptions was preprocessed and converted into TF-IDF vectors.
- The recommendation model, based on cosine similarity, was built using TensorFlow and Keras.
Challenges We Ran Into
Our project presented several challenges, including:
- Data Quality: Ensuring data quality, handling missing values, and cleaning the dataset was time-consuming.
- Machine Learning Complexity: Building recommendation systems requires a deep understanding of machine learning concepts, which required ongoing learning and experimentation.
- Model Performance: Tuning the recommendation model for optimal performance was complex, involving decisions on parameters and techniques.
- Data Variety: The dataset contained a wide variety of movie genres, ratings, and descriptions. Providing meaningful recommendations was challenging.
Accomplishments That We're Proud Of
We are proud of the following accomplishments:
- Successfully creating a functional movie recommendation system.
- Gaining valuable experience in data analysis, data preprocessing, and machine learning.
- Developing a user-friendly system that can offer personalized movie recommendations.
What We Learned
Throughout the project, we learned:
- The importance of data exploration and visualization in understanding datasets.
- Techniques for data preprocessing, including feature engineering and handling missing values.
- The fundamentals of recommendation systems, including TF-IDF and cosine similarity.
- How to build a basic recommendation model using deep learning.
What's Next for Movie Recommender
In the future, we plan to:
- Enhance the recommendation model by exploring more advanced algorithms.
- Incorporate user feedback and ratings to improve recommendations.
- Extend the system to include user profiles for better personalization.
- Explore deployment options, such as building a web-based interface for users to interact with the recommendation system.
Our Movie Recommender project is just the beginning of our exploration into recommendation systems and data analysis in the context of the entertainment industry.
Built With
- keras
- matplotlib
- pandas
- python
- scikit-learn
- seaborn
- tensorflow

Log in or sign up for Devpost to join the conversation.