-
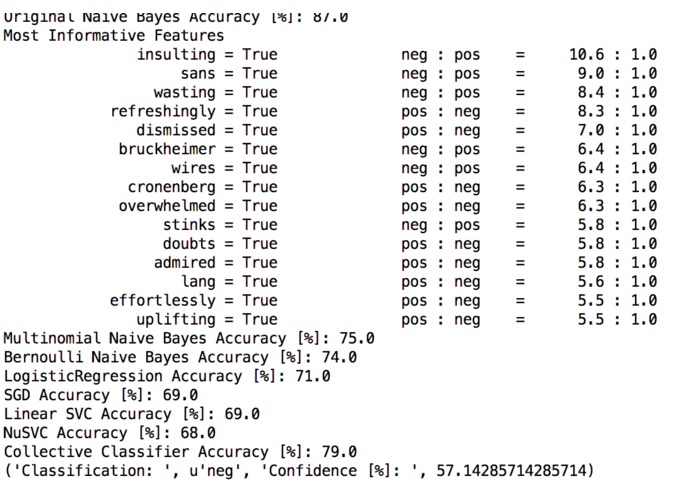
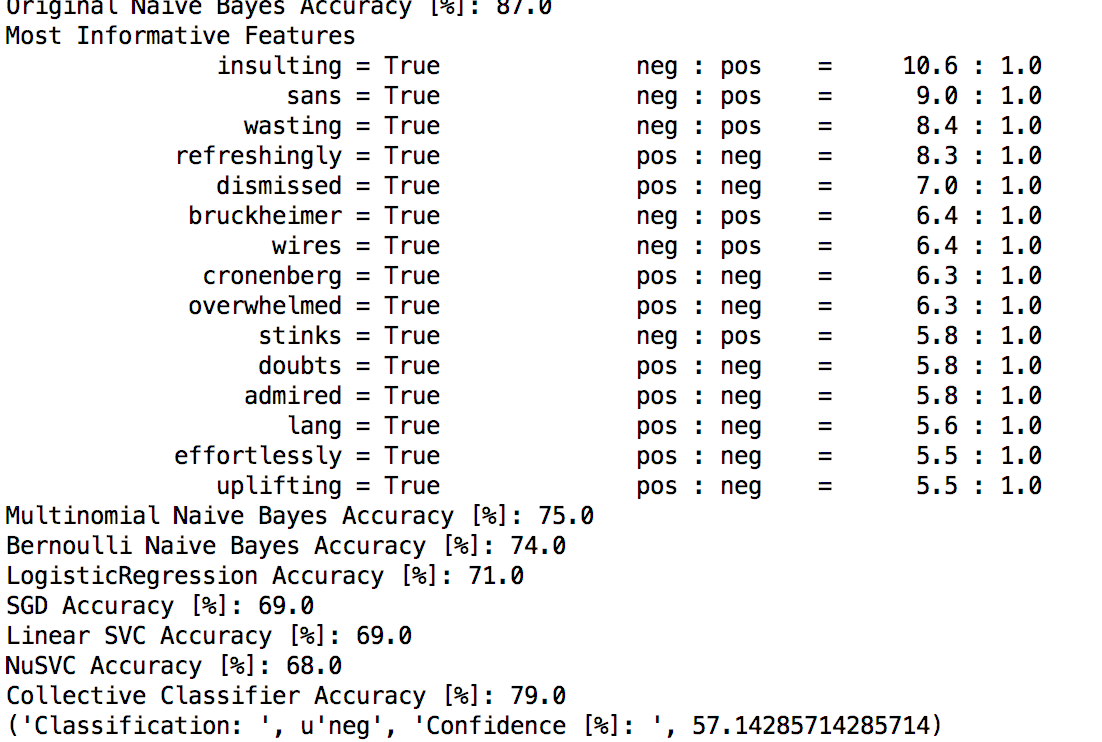
Example Output
Inspiration
Coming as a first-timer to hackathon, I was bubbling with a ton of crazy ideas. I had concepts down in my mind for computerized wallets, beautiful virtual reality games and sound-changing technology that hadn't been developed before. The only issue was that I am a noob. I overestimated what I could possibly do, and that led to the reality check of me finding out I couldn't develop almost all of the things I wanted too. However, my artificial intelligence seminar flashed in my head and I thought it would be neat to try out something involving machine learning.
What it does
This is a Python implementation of the Naive Bayes classifier. The purpose of the classifier is that it will look at a block of text and analyze from what it knows about positive and negative words whether or not the block of text holds a positive or a negative message. It measures its own confidence level in how sure it is in its validity.
How I built it
The University of Pennsylvania developed a very well-known *Natural Language Processing toolkit for Python in 2001. It is known as http://www.nltk.org and it is widely used to develop bare functions involved with NLP. I worked around with some of the methods supplied by this library as well as creating my own to develop this. Originally it was a lot of trial-and-error; however, lots of reading later, things became simple.
Challenges I ran into
It's not simply simple to develop something like this. Some believe you can just count the number of positive words and compare it directly to the number of negative words. This does not hold true however. Consider the phrase, "he brilliantly succeeded at failing". The sentence is definitely negative; however, just simply counting specific words to determine if it was positive or negative would make the machine believe the sentence was positive.
Accomplishments that we're proud of
I was absolutely proud of the brilliance behind my Collective Classifier simply because it took every single algorithm in the project [regardless of accuracy], took the best parts of all the algorithms, and merged everything into one classifier that gives the best result possible. All simply within a few lines of code:
class Collective_Classifier(ClassifierI):
def __init__(self, *CLASSIFIERS):
self._CLASSIFIERS = CLASSIFIERS
def classify(self, FEATURES):
CUM_TOTAL_AMOUNT = []
for c in self._CLASSIFIERS:
t = c.classify(FEATURES)
CUM_TOTAL_AMOUNT.append(t)
return mode(CUM_TOTAL_AMOUNT)
def CONFIDENCE(self, FEATURES):
CUM_TOTAL_AMOUNT = []
for c in self._CLASSIFIERS:
t = c.classify(FEATURES)
CUM_TOTAL_AMOUNT.append(t)
CUM_TOTAL = CUM_TOTAL_AMOUNT.count(mode(CUM_TOTAL_AMOUNT))
CONF = CUM_TOTAL / len(CUM_TOTAL_AMOUNT) * 100
return CONF
What I learned
I learned that NLP is definitely an incredibly bigger challenge to implement than I could have imagined. What I was able to do hardly even covers the basic necessities to properly read and analyze text written by a seven year old. However, I also learned how to properly implement classes and functions in a proper way and I also learned a lot of Python within the day.
What's next for Movie Review Reviewer
Having Movie Reviewers Review how the Movie Review Reviewer Reviews Movie Reviews.
Just kidding.
Honestly, instead of making it more specific for movies, I just want to make something that can be more broadly applied to many different segments of text.
Built With
- movie-reviews
- natural-language-processing
- nltk
- numpy
- pip
- python
- scipy
- sklearn
Log in or sign up for Devpost to join the conversation.