-
-
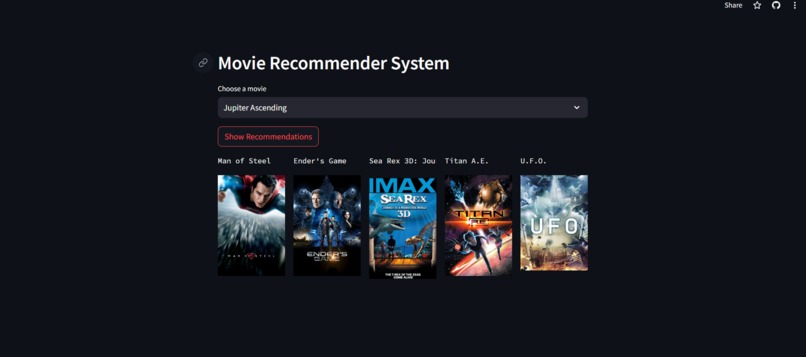
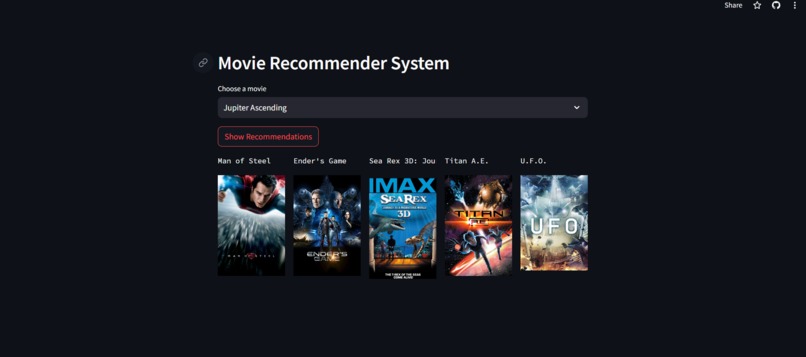
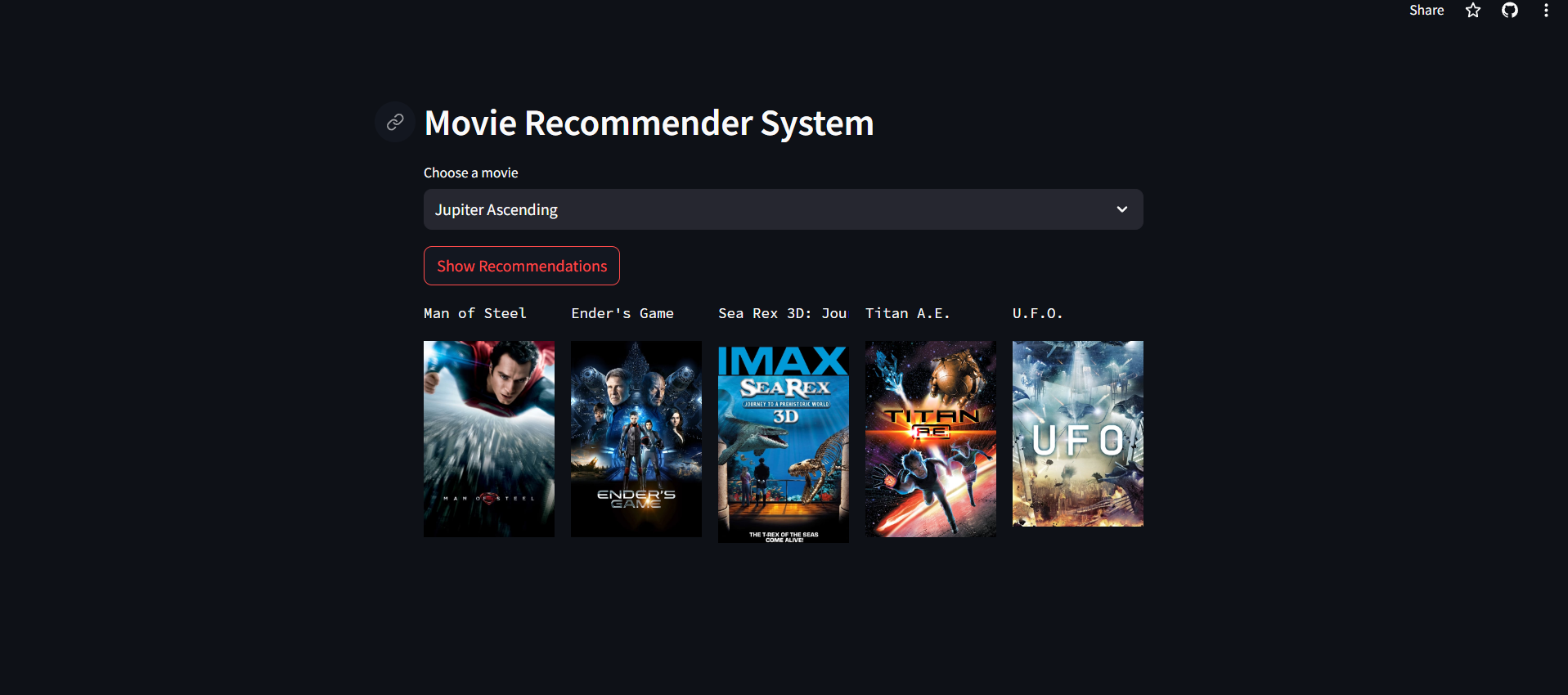
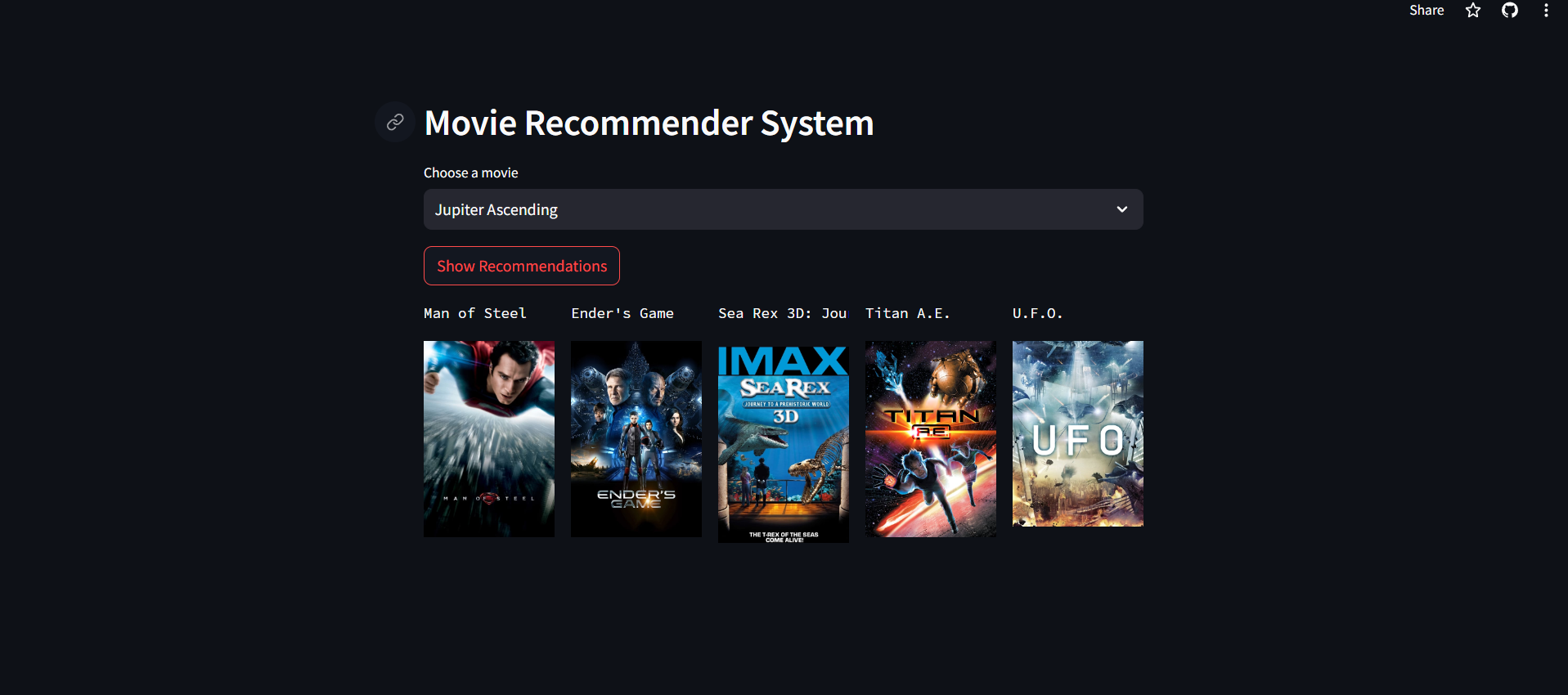
Project Screen Shot
Inspiration
My inspiration came from the desire to combine my passion for movies with my newfound interest in machine learning. I wanted to delve deeper into the world of recommendation systems, understanding how they work and how I could build one myself. Throughout this project, I learned about natural language processing (NLP), cosine similarity, and how to use them to analyze textual data and make recommendations.
What it does
The project provides movie recommendations based on the user's selected movie.
How we built it
I started by acquiring the TMDB 5000 Movie Dataset from Kaggle, which provided me with a rich source of movie information, including titles, overviews, actors, and directors. With my basic Python knowledge, I wrote scripts to preprocess the data, extracting relevant information and creating a unified representation of each movie using word embeddings.
Next, I employed cosine similarity to compute the similarity scores between movies based on their textual features. This involved constructing a cosine similarity matrix, where each entry represented the similarity between two movies. By comparing the cosine similarity scores, I could identify movies that were most similar to each other.
For the frontend, I turned to Streamlit, a user-friendly framework for building interactive web applications with Python. Using Streamlit, I designed a sleek and intuitive interface where users could input their preferences and receive personalized movie recommendations.
Challenges we ran into
One significant challenge I encountered was in using Streamlit and figuring out a way to preprocess the textual data effectively. Specifically, I had to devise a method to handle words with similar meanings so that variations like "dance", "danced", and "dancing" were treated as the same entity. This involved implementing techniques like stemming or lemmatization to consolidate words to their root form, ensuring consistency in the data representation and improving the accuracy of the recommendations.
Accomplishments that we're proud of
Finding out ways to handle words with similar meanings so that variations like "dance", "danced", and "dancing" were treated as the same entity. Dealing with streamlit for frontend purposes. Brainstorming on what possible textual data can be used from the dataset.
What we learned
Creating this movie recommender system was an enriching experience that allowed me to apply my newfound knowledge of machine learning in a practical and meaningful way. Through this project, I gained valuable insights into recommendation systems, NLP techniques, and the importance of user experience design. As I continue to explore the world of machine learning, I look forward to tackling more complex challenges and honing my skills further.
What's next for Movie Recommender
Incorporating more features to improve the accuracy of the model.

Log in or sign up for Devpost to join the conversation.