-
-
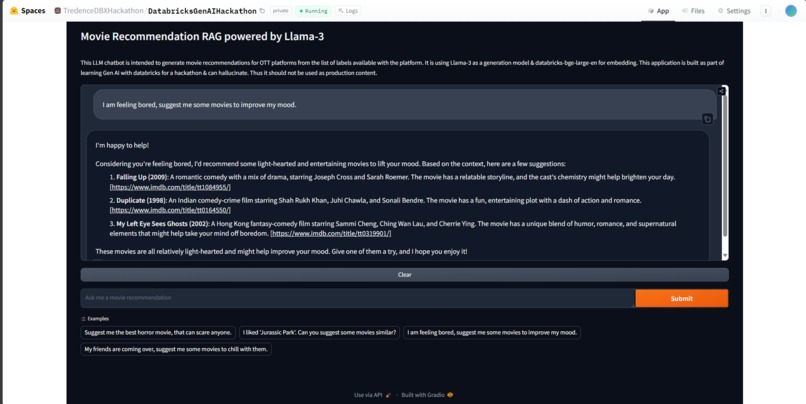
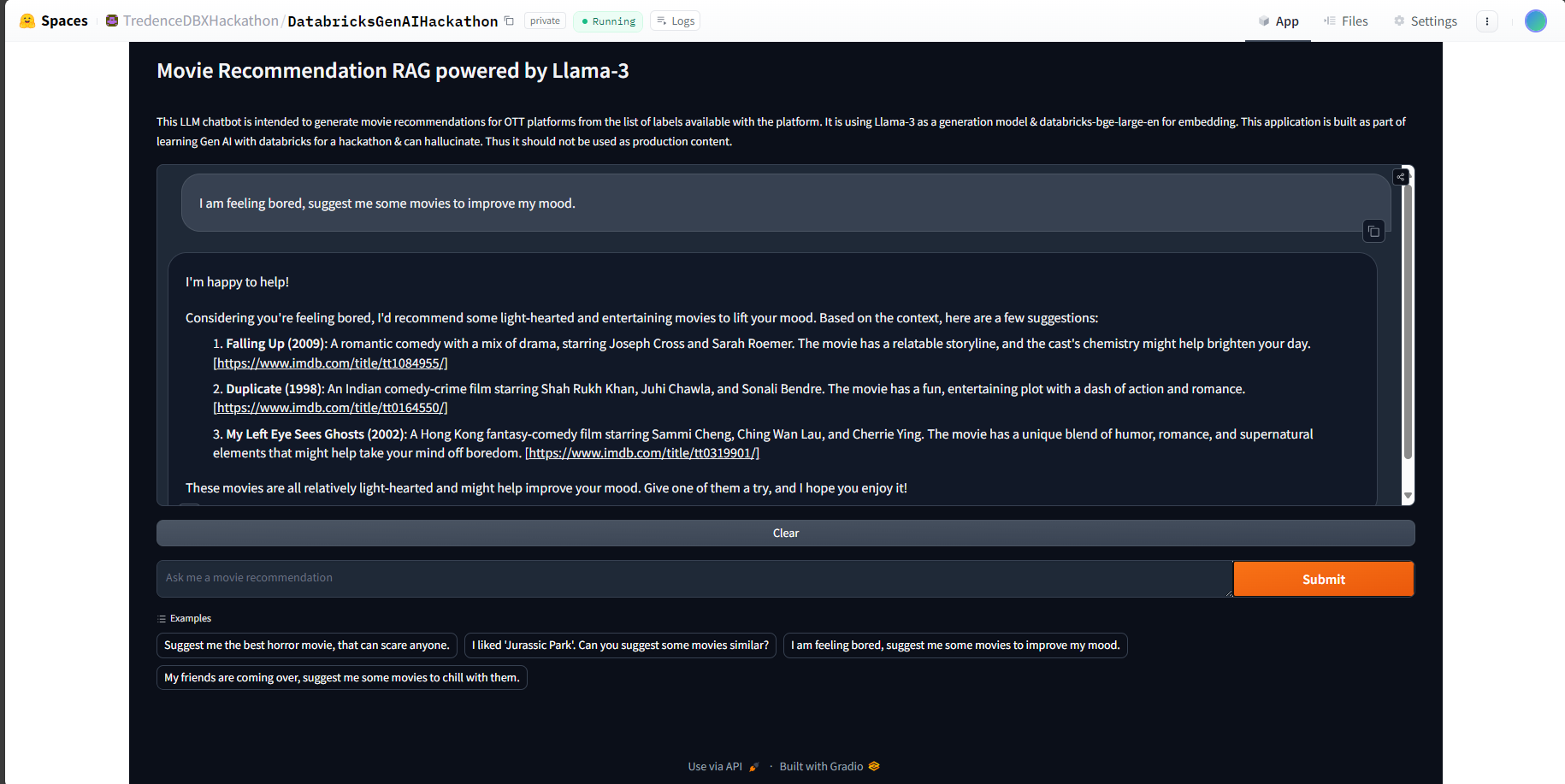
Sample run on Hugging Face Spaces
Inspiration
Introducing the Future of Movie Recommendations: The Movie Recommendation Assistant
In the era of OTT platforms like Netflix and Amazon, streaming movies has never been easier. However, with an ever-expanding library of films, finding the perfect movie to watch can feel like finding a needle in a haystack. Current recommendation systems, based on user click-stream data, watch history, regional top charts, and preferences, often leave us with suggestions heavily influenced by our recent streams or popular trends.
What if you want a movie that fits a specific occasion, or matches your current mood? What if you want to explore beyond your usual genres and step out of your comfort zone?
Enter the Movie Recommendation Assistant. This solution aims to bridge the gap between you and your perfect movie. It goes beyond traditional recommendation systems by considering not just your viewing history, but also your current desires and preferences.
No more endless scrolling through recommendations. No more settling for movies that don't quite hit the mark. With this Assistant, you can make the most of your precious time, diving straight into movies you'll love and experience the future of movie streaming, tailored specifically for you.
What it does
The movie label information available with the platform is mapped with IMDB information to generate a final movie information corpus, which is then embedded to a vector store. Then the retrieved records as per user query will be passed as context to a generator model which will provide recommendations based on this context by picking best matches to the user query.
How I built it
I built this based on Retrieval-Augumented Generation architecture using Databricks Gen AI capabilities like Unity Catalog, Model Serving, Vector Search
- Used off the shelf models, databricks-bge-large-en as the embedding model & databricks-meta-llama-3-70b-instruct as the generation model
Challenges I ran into
- Initially tried to work with ChromaDB & small size models but the time for development is very high & the GPU requirements are also high. Replacing them with off the shelf models from databricks saved time & hopefully cost.
- Setting up service principal based authentication for the served models is slightly challenging.
Accomplishments that we're proud of
- Proud of implementing my first RAG solution using Databricks & successfully serving it in real-time.
- Able to explore some small scale LLMs & the foundational models to see the differences in the kinds of responses they are capable of providing.
- Getting a hang of Prompt Engineering to instruct the LLMs to get intended responses.
What I learned
- Learnt about the Gen AI basics like Summarization, Extraction, RAG, Sentiment Analysis etc.
- Explored the capabilities of small scale LLMs & foundational models.
- Got introduced to LangChain & learnt multi stage reasoning with LLM chains
- Learnt how prompt engineering plays an important role in guiding the LLM responses.
- Learnt about registering & serving LLM models in Databricks in real-time deployment scenarios.
What's next for Movie Recommendation System
- Implement a feedback loop to do reinforcement learning through human feedback for providing personalized recommendations with respect to each user.
- Implement the LLM evaluation for Hallucination, Toxicity, Relevance etc.
- Chunk the documents & implement context & content based filtering for improving the recommendations of the generation model.
- Secure personal user information from leaking by the LLM
- Improve the UI
- Create workflows to orchestrate the flow
- Implement Data Governance to secure the user data
- Bundle the code through Databricks Asset Bundles
Built With
- databricks
- gradio
- huggingface
- langchain
- model-serving
- pyspark
- retrieval-augumented-generation
- unity-catalog
- vectorsearch

Log in or sign up for Devpost to join the conversation.