-
-
Movie match
Inspiration
We believe that curating the user experience is crucial to the success of an online streaming service, and we wanted to comprehend more about the inner workings of movie recommender systems.
What it does
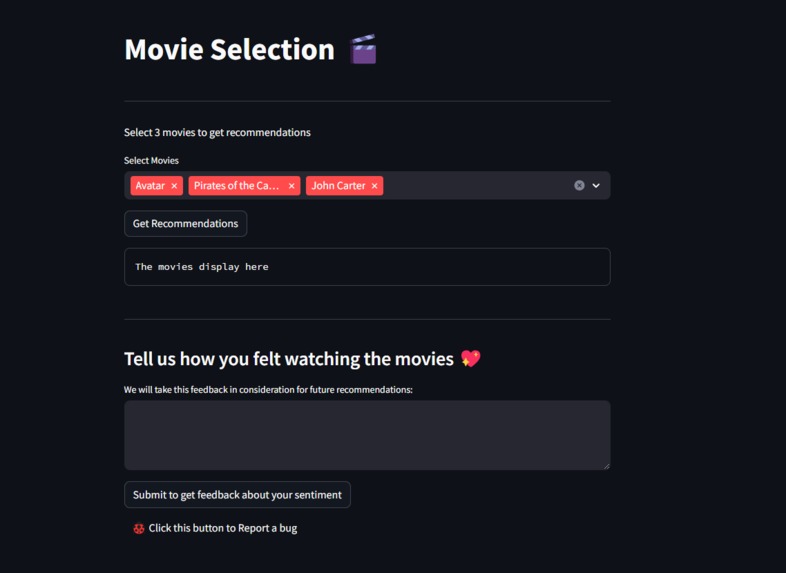
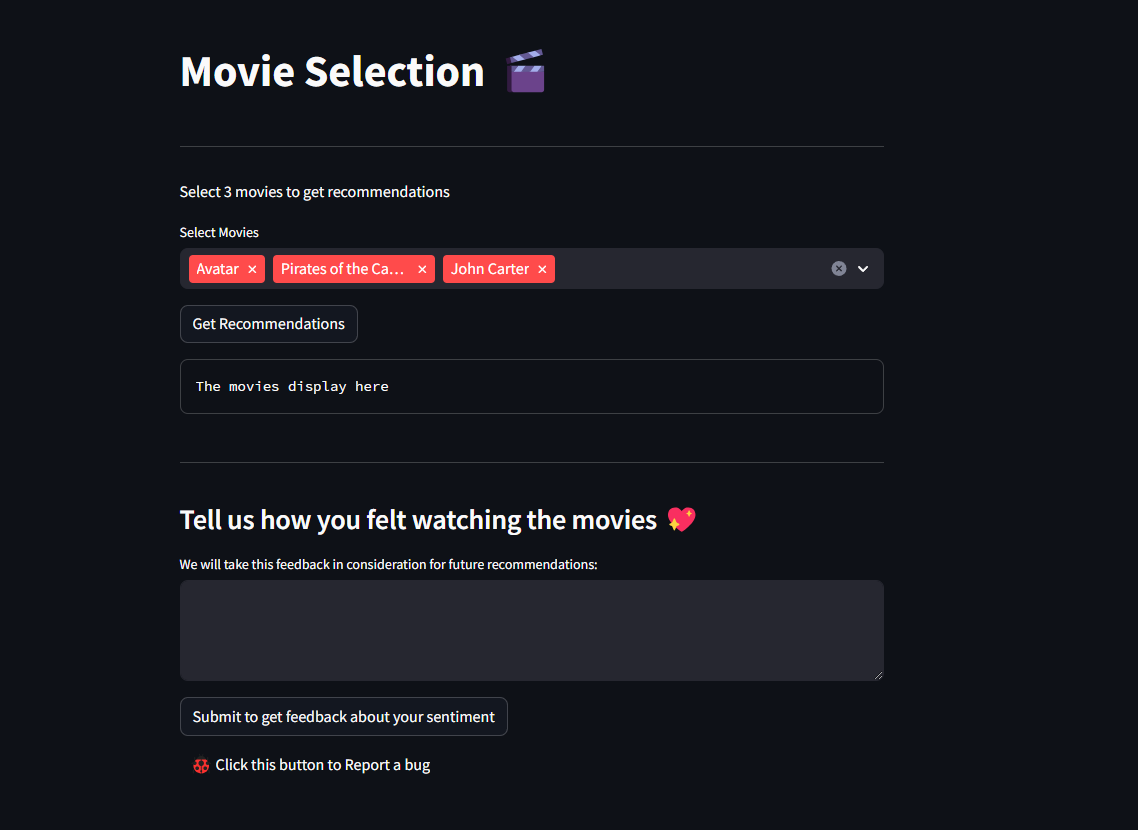
We decided to explore the recommendation of movies with a K cluster ML system by taking the tags of movies such as ratings, directors, and actors and determining the audiences that coincide with the systems. This is done with a database from tmbd that contains data from around 5,000 movies.
Due to the time and experience of the team (which is composed of only two of us) we could develop the skills to comprehend how K clustering works, but at the time of application we had to use the code from https://medium.com/swlh/movie-recommendation-and-rating-prediction-using-k-nearest-neighbors-704ca8ccaff3 but with a twist.
The code proposed gave the recommendations based on a movie title, for our iteration we created a system that considers the user's profile and recommends a curated selection of movies. This is done by asking for 3 movies, iterating over the cosine differences of them and finding which ones are more similar, that are used to find the 2 K closest neighbors per movie to recommend.
We also wanted to apply some of the knowledge we had gathered with GPT and apply a sentiment analysis GPT. This is focused as an active system where customers can write reviews about the system, once they write a review the LLM processes it and determines the state of mind of the client at that time, what movie they watched, and the quality of the recommendation. This works as a feedback system that could be integrated with the K clustering system in future iterations to allow to fine tune the dataset into giving more satisfaction to the users. The data analyzed by GPT is then uploaded to a google sheets data frame for later analysis.
How we built it
We used streamlit to host and run the code
A pickle with the dataset processed is loaded, which is used by the cosine and k clustering functions as the user interacts with the website. The k clustering code and data cleaning was from the code already referenced, we developed the streamlit app and GPT connection. GPT determines how the user feels and passes the arguments to a google sheets as a custormer management system to demonstrate how it could be used in a business setting.
Challenges we ran into
Our main challenge was time, specially as we had just entered a new semester in college, limiting our ability to develop and learn a lot about ML models that could have been implemented. Another problem was uploading the pickle file, that had to be cut down as it exceeded 100mb and we could not figure out how to upload it to Git using LFS.
Accomplishments that we're proud of
Our main accomplishment is that we grasped the concept of K clustering for unsupervised learning, that is great as we had had experience with supervised learning, but this is our first project working with an unlabeled dataset.
What we learned
How K clustering works and how can it be implemented with an example of the code we used
What's next for Movie Matcher
We are looking to continue developing our skills in ML so as for the next hack we can code it all by ourselves, but this first iteration was great to apply the concepts we learned and see how they work in a real life example.
Built With
- google-cloud
- openai
- python
- sheets
- streamlit


Log in or sign up for Devpost to join the conversation.