-
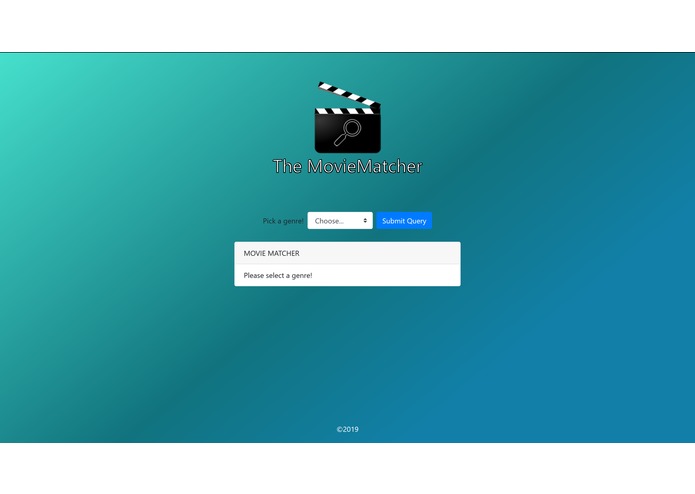
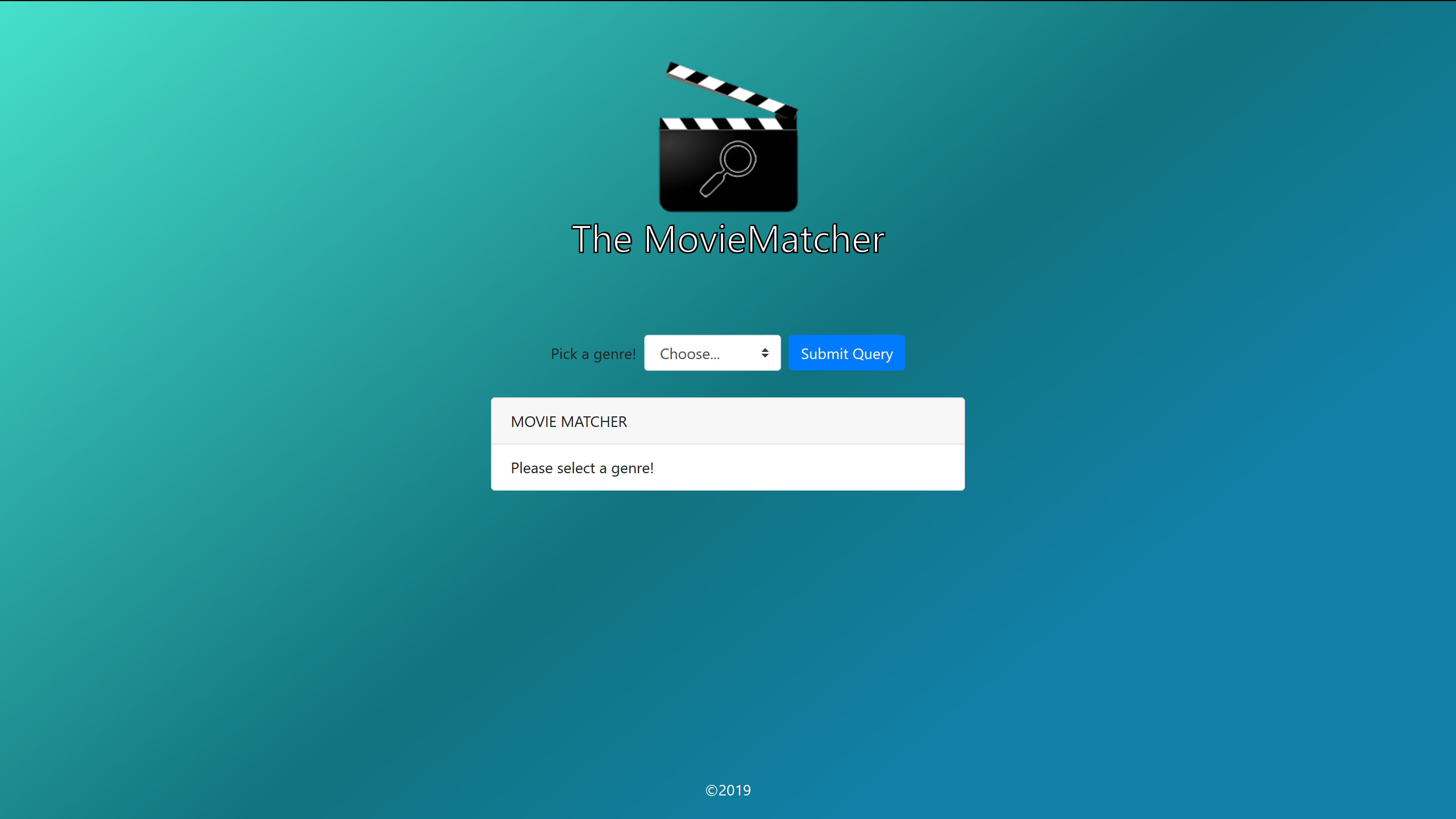
Home Page
-
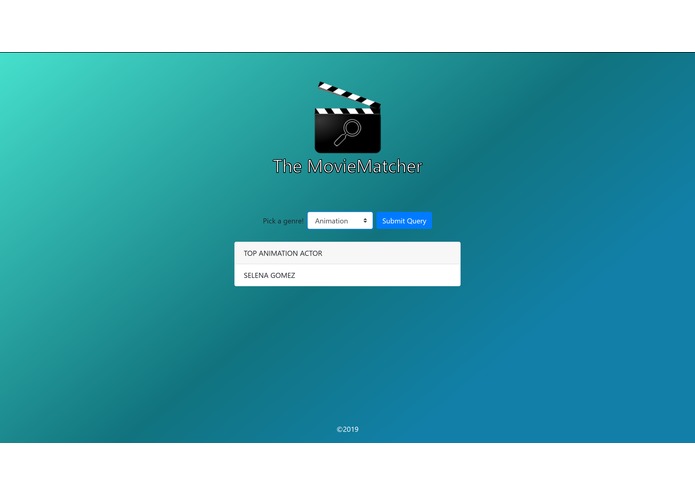
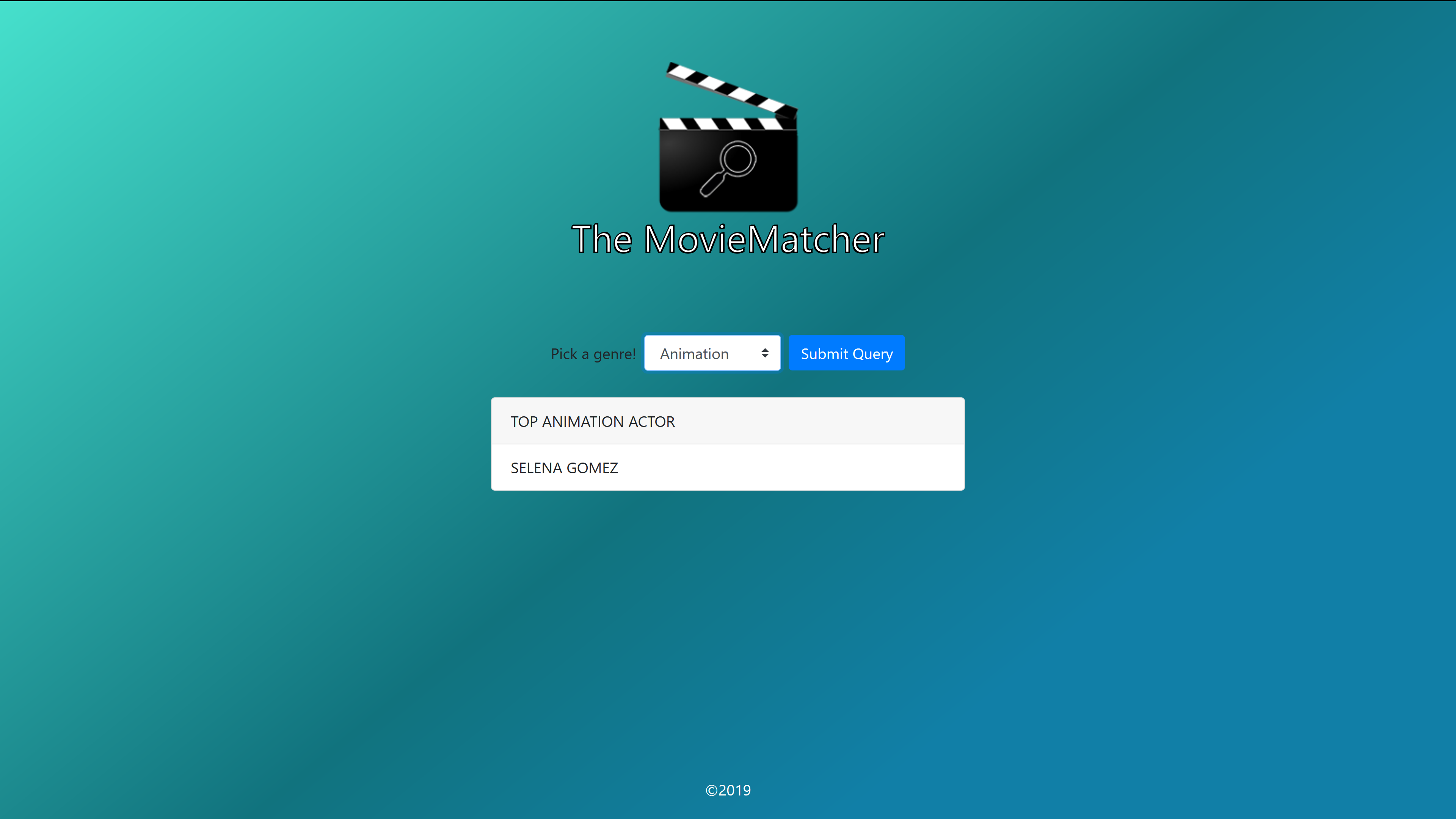
Query
-
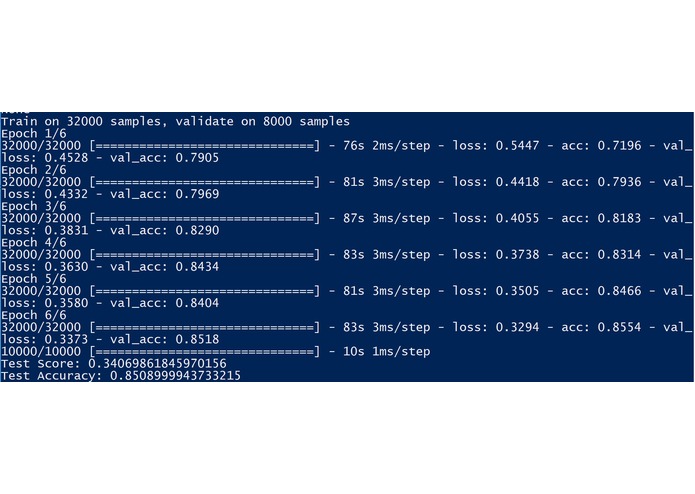
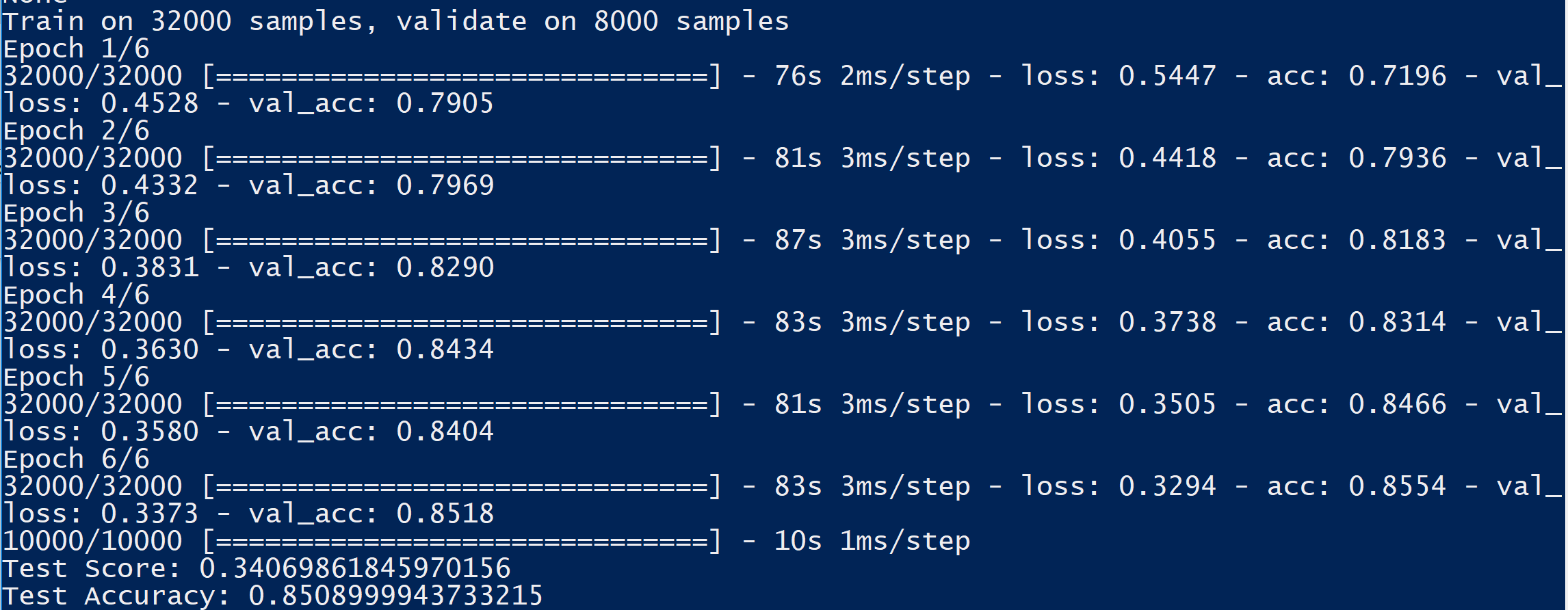
Deep Learning model
-
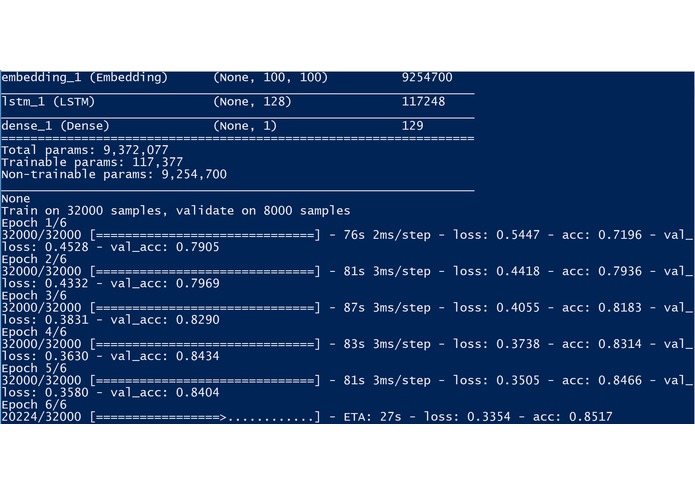
Deep Learning model
-
Prediction Model

movie-matcher
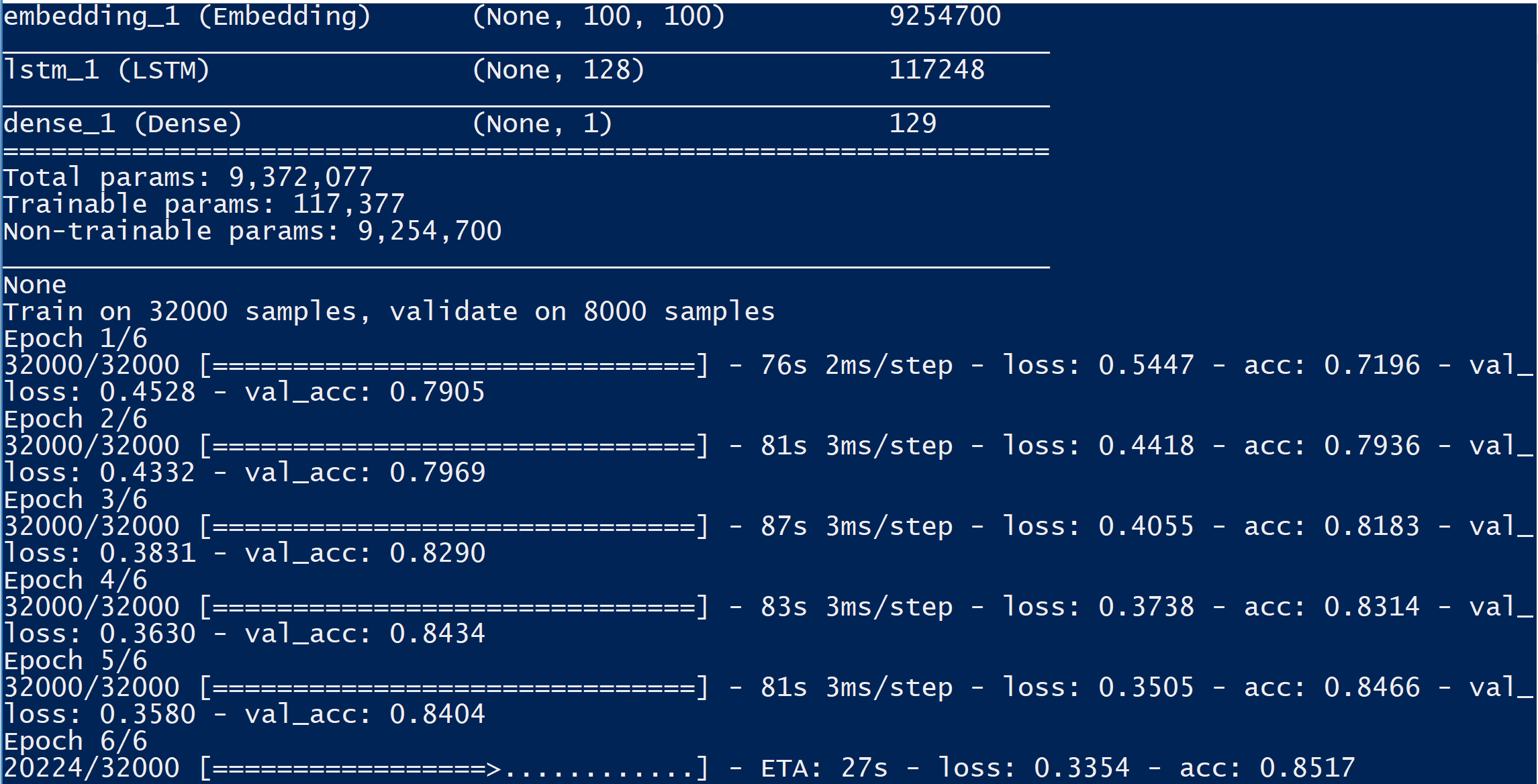
Entry for MetroStar's Movie Matcher track for GMU's PatriotHack 2019 Hackathon. It uses the LSTM architecture for Sentiment Analysis and Kaggle's Large Movie Review Dataset (https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews) to determine whether reviews are positive or negative, calculates a "genre score", which is the positive reviews subtracted by the negative reviews for each actor featured in a movie.
How to set up
Movie Matcher relies on scikit-learn, numpy, nltk, keras, glob, requests, sqlite3, re, pandas, and json libraries and utilizes Python 3.7. The web appliction is a simple database query in order to visualize the data; however, it will require the scripts to be executed in order to update the database. You can do this by running process.py, which will train the model and save it to an h5 file, then the get_reviews.py, which will gather all reviews in the given dataset (in this case, we used MetroStar's dataset of movies) through the themoviedb API, and then run predict.py in order to run the Sentiment Analysis prediction on all available reviews, calculate genre scores, and store them to the SQLite3 databse.



Log in or sign up for Devpost to join the conversation.