-
-

mount AI Scholar icon
-
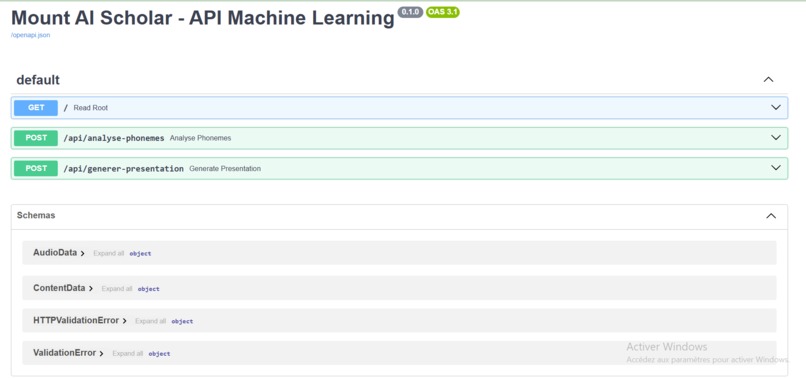
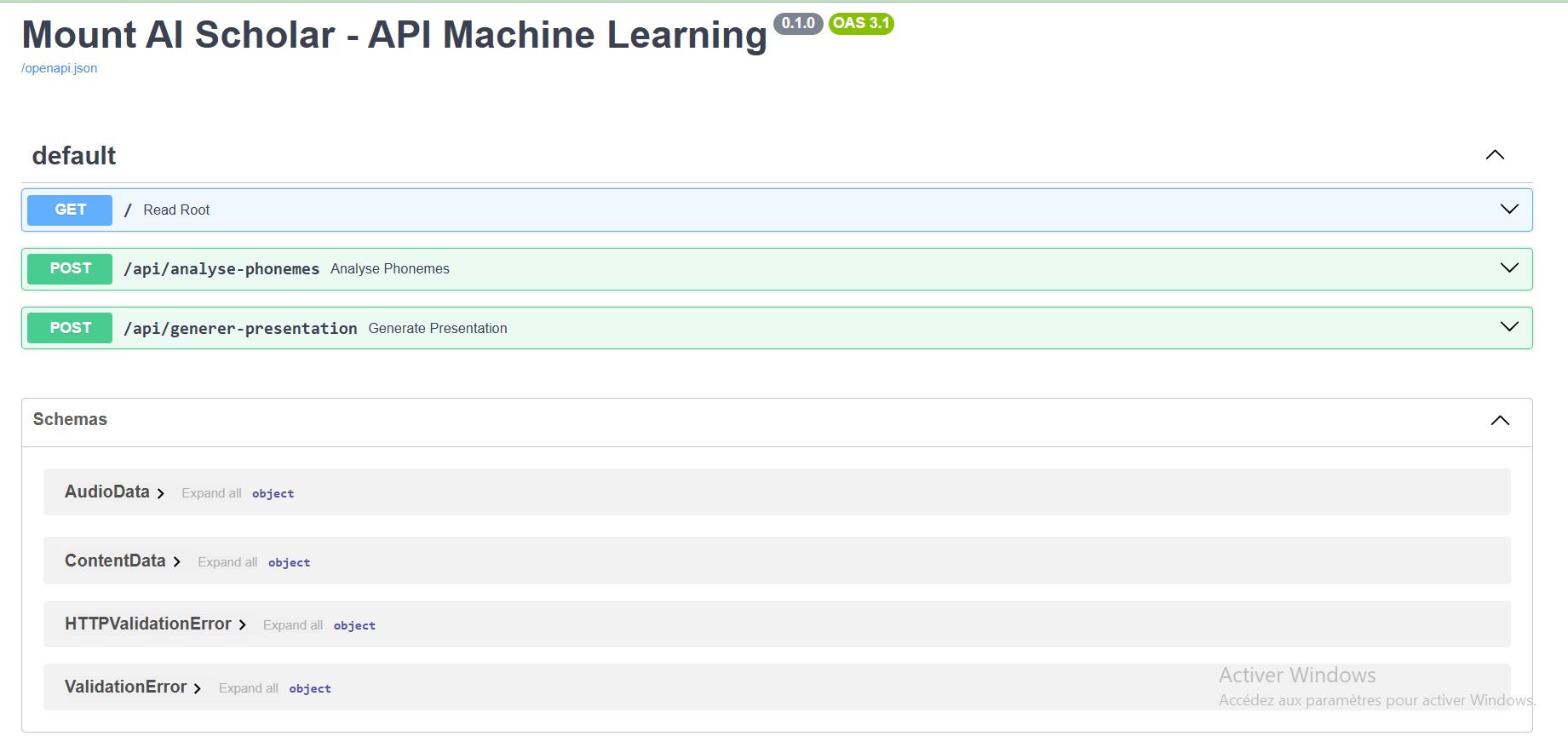
FASTAPI SERVER
-
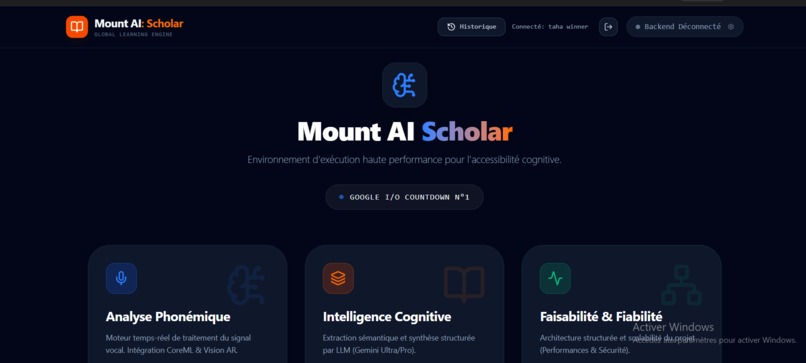
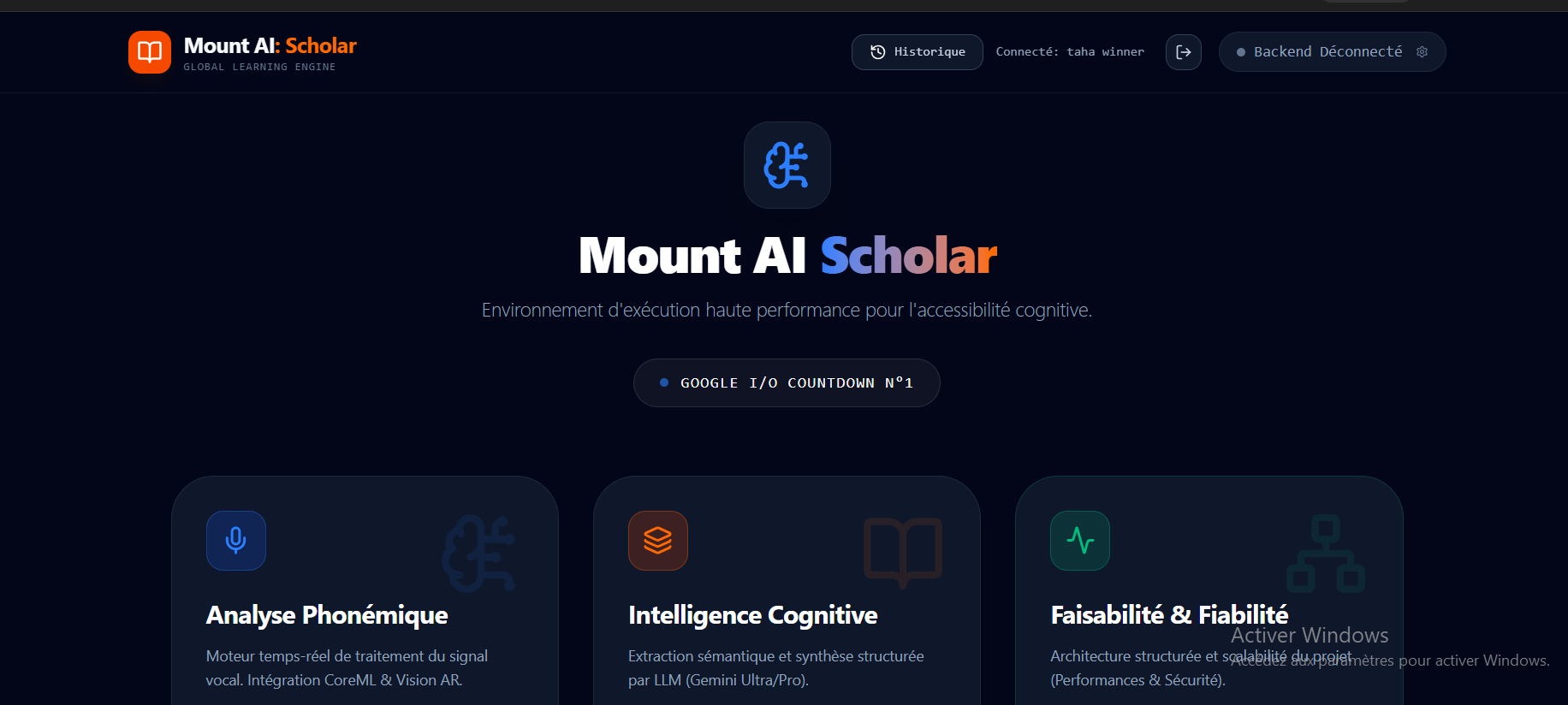
Dashboard

Inspiration
Education is the master key, but the lock is different for everyone. I was inspired by the silent struggles of students facing cognitive or sensory challenges—specifically dyslexia and hearing impairments. I realized that the rigid structure of traditional schooling could be completely reshaped using Artificial Intelligence. I wanted to build a platform that allows anyone to scale the "mountain of knowledge", using real-time visual techniques to break down the barrier between complex concepts and the learner.
What it does
Mount AI Scholar is an advanced, multi-modal educational platform. It features a real-time vocal analyzer, phoneme-grapheme mapping for dyslexia, sound-to-visual transformations for the hearing impaired, and a dynamic revision system spanning 8 languages. It takes raw educational input and outputs interactive summaries, fun quizzes, and accessible learning modules.
How I built it
I designed a modern, highly decoupled architecture to ensure both speed and scalability:
- Frontend (The Interface): Built with React and Tailwind CSS, creating a sleek, accessible, and ultra-responsive dashboard.
- Backend & Data: Powered by FastAPI for high-performance, asynchronous API routing, with Firebase handling secure user authentication and real-time database synchronization.
- AI & ML Pipeline (The Engine): I integrated custom Machine Learning pipelines in Python, heavily leveraging the Hugging Face ecosystem for state-of-the-art NLP, audio processing, and language translation.
- Search & Retrieval: I used the Elastic stack to instantly query, filter, and retrieve educational data and text embeddings at lightning speed.
Challenges I ran into
The biggest hurdle was orchestrating the real-time inference pipeline. Capturing live audio or text from a React frontend, routing it through a FastAPI server to query massive Hugging Face ML models, and returning visual outputs with near-zero latency required intense optimization. Furthermore, mapping audio to visual phonemes with high accuracy requires strict probabilistic models. I had to deeply understand the math behind speech-to-text algorithms, represented fundamentally by Bayes' Theorem:
$$ P(w | a) = \frac{P(a | w) P(w)}{P(a)} $$
(Optimizing the probability of a word/phoneme sequence $w$ given the acoustic feature sequence $a$).
What I learned
I learned how to bridge the gap between experimental AI/ML and production-ready Web Engineering. Building an asynchronous API with FastAPI to serve heavy Hugging Face models taught me a lot about network bottlenecks and concurrency. I also solidified my skills in state management with React and cloud architecture with Firebase.
What's next for Mount AI Scholar
This Web/Python foundation is just Phase 1. My ultimate "Master Plan" is targeted at the Apple WWDC Swift Student Challenge 2027. I plan to optimize and port this entire ML pipeline into CoreML. From there, I will rebuild the user interface using SwiftUI and ARKit, creating a fully immersive spatial computing environment where students can literally see, touch, and interact with floating phonemes in their own living room.


Log in or sign up for Devpost to join the conversation.