-
-

MotZip
-
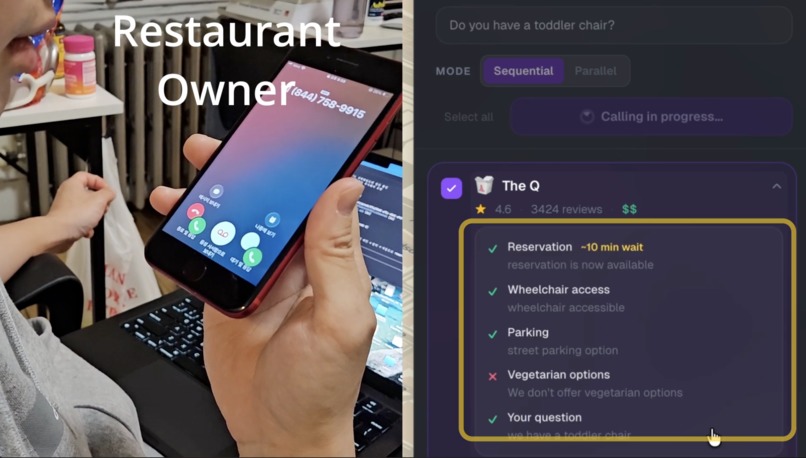
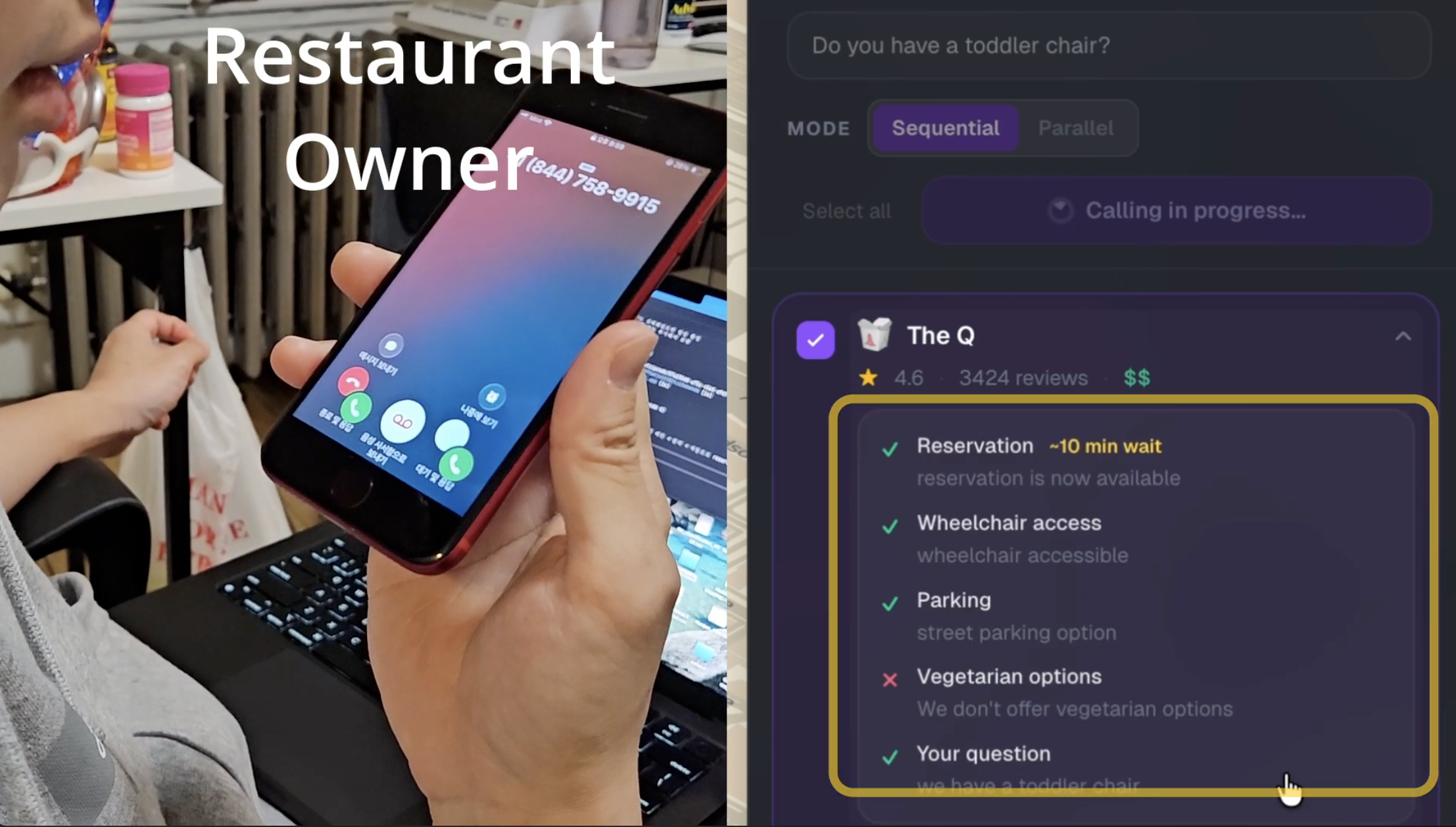
Using Twilio AI agent make phone call to restaurant for you
-
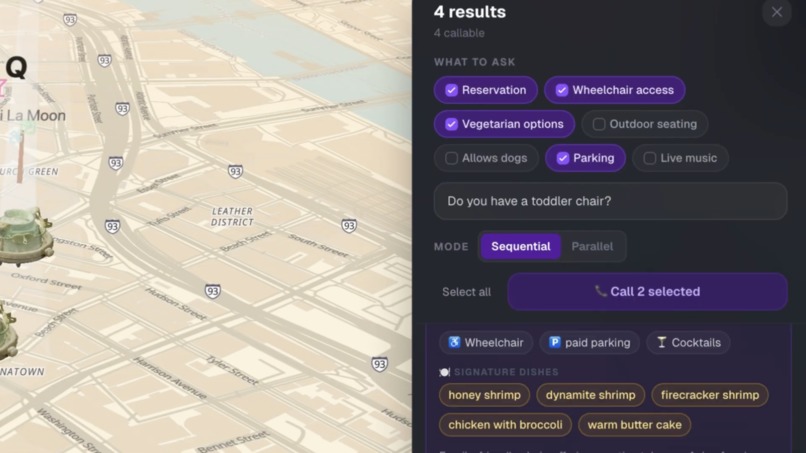
Write the question, AI will take charge of the phone call
-
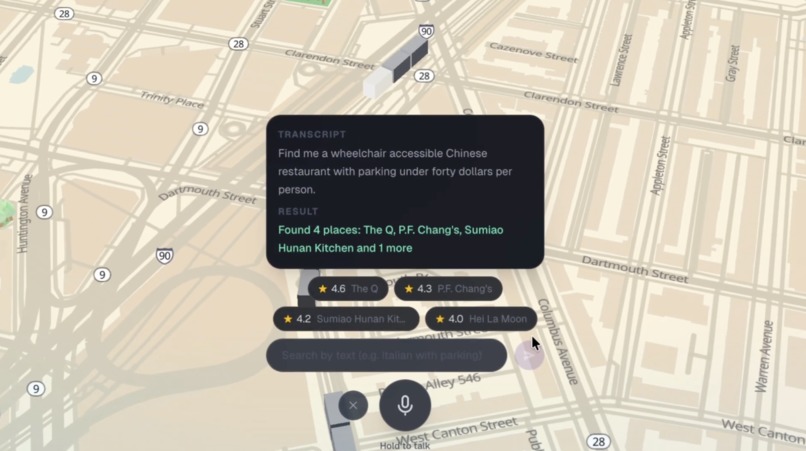
Voice mode for finding the restaurant that you need.

Inspiration
Star ratings, reviews, photos — almost everything about a restaurant is online. Except the one thing you actually need to decide tonight: real-time, personal answers. Wait time right now. Whether your kid's stroller fits. Whether the bathroom is wheelchair accessible. Whether they have a vegetarian dish. That information doesn't live on Yelp; it lives in the head of one person at the restaurant.
So you call. One restaurant. Then the next. In a language that may not be your first.
For most of us this is friction. For some people it's a wall. People learning English avoid calls because of the language barrier. Deaf and hard-of-hearing people often can't make a phone call at all. Wheelchair users have to verify every doorway and bathroom before deciding where to eat. The phone call has been the gatekeeper to dining out — and we wanted to remove that gate.
What it does
MotZip does two things no other app does.
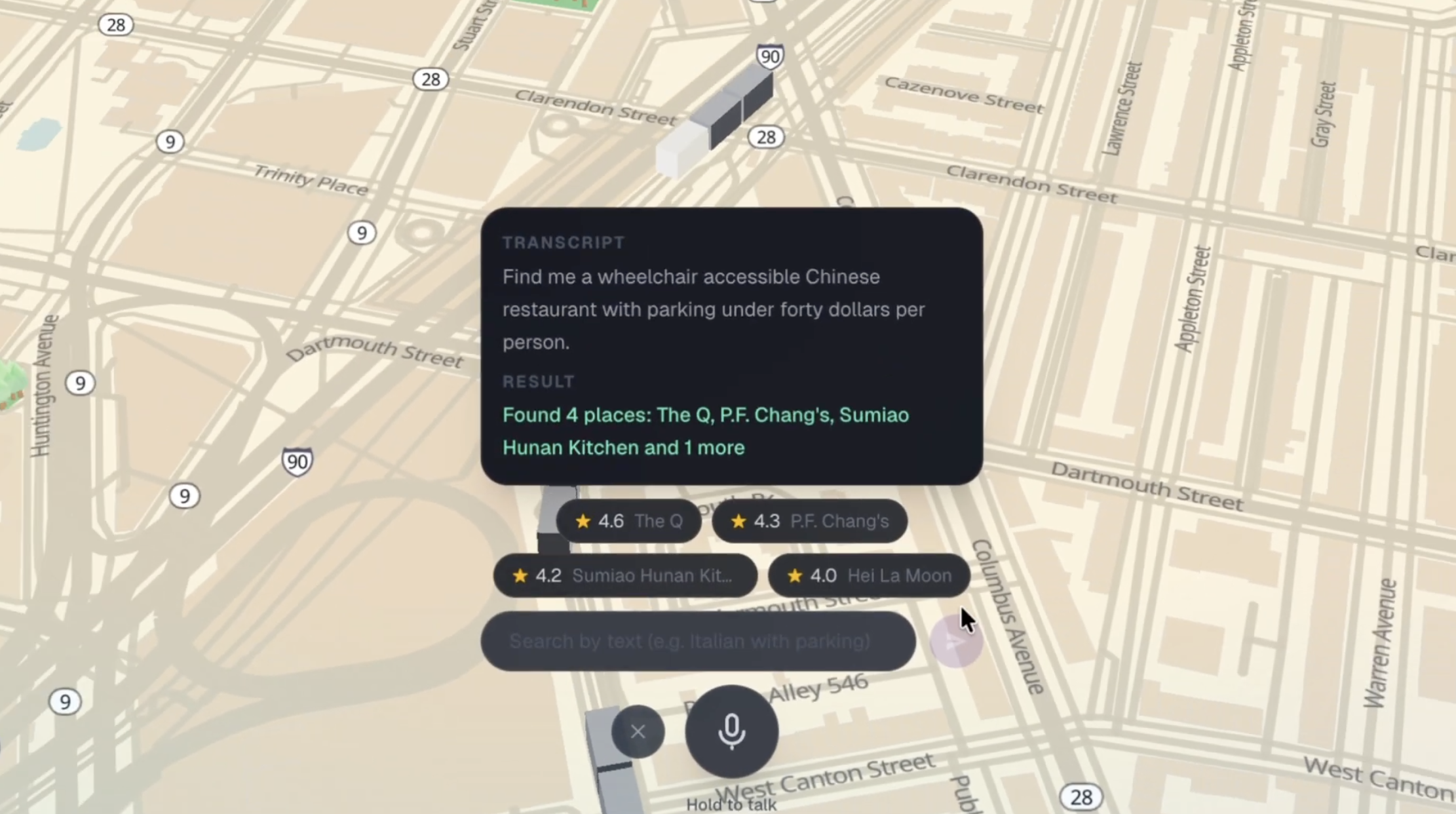
1. Find candidates by saying what you actually want. Press the mic and speak in plain English or Korean: "quiet romantic spot for date night, korean food, under $40, with cocktails". Gemini extracts structured filters (cuisine, price, vibe, accessibility, parking, dogs, alcohol) and a 3D Boston map filters in real time — non-matching buildings sink into the ground and vanish, matching ones get a glowing spotlight. Cards slide in on the right. A friendly voice speaks back the count and top picks.
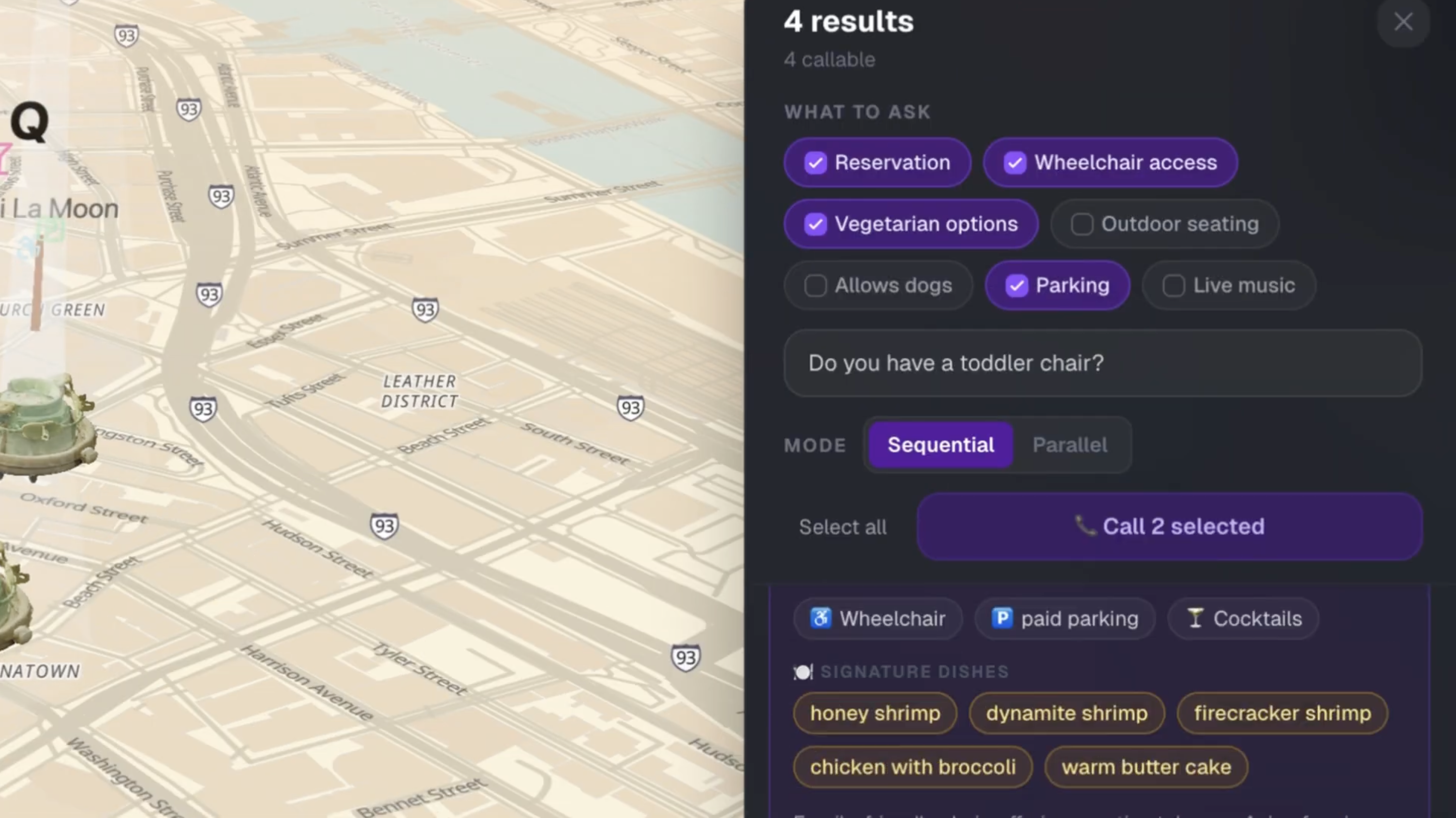
2. Call the candidates and ask your questions, automatically and in parallel. Pick the questions you actually care about (reservations, vegetarian options, wheelchair access, outdoor seating, parking, live music, dogs allowed) and add a custom question in any language. Click "Call N selected." Our AI agent dials each restaurant, asks one question at a time in a chained Twilio Gather flow, transcribes each answer with Google Cloud Speech, parses each one with Gemini, and streams the results back as a structured ✓/✗/? checklist per restaurant.
Plus: each card extracts the restaurant's signature dishes from its real Google reviews on demand, so you know what to order before you walk in.
How we built it
- Frontend — Next.js 16 (Turbopack) + React 19 + TypeScript + Tailwind 4. MapLibre GL for the 2D base, Three.js for 3D buildings with a custom GLSL spotlight shader, TRELLIS-generated GLB food icons loaded with DRACOLoader. Deployed on Vercel.
- Backend — FastAPI with a modular APIRouter architecture (places / voice_search / twilio_calls / llm / speech / catalog). Pydantic API contracts. Containerized and deployed on Google Cloud Run with the Vertex AI service account.
- LLM — Gemini 2.0 Flash via Vertex AI for natural-language filter extraction, signature dish extraction, and per-answer call parsing.
response_mime_type=application/jsonfor schema-enforced output. Local Ollama (Gemma 3 4B) wired in as automatic fallback for offline resilience. - Speech — Google Cloud Speech-to-Text + Text-to-Speech as primary (multilingual: en + ko). ElevenLabs Scribe + Turbo v2.5 as auto-fallback (warmer voices for local recording).
- Phone calls — Twilio Voice with chained
<Gather>per question. Status state-machine:initiated → asking N/M → parsing → completed. Each turn is parsed independently for higher per-question accuracy than asking everything at once. - Restaurant data — Google Places API (New)
searchNearby, split into 7 cuisine type-groups to bypass the hard 20-result cap (39 → 98 restaurants in the demo region).
Challenges we ran into
- The 20-result cap. Google Places
searchNearbyreturns at most 20 places per query. We initially had 39 restaurants total. Splitting into 7 cuisine type-groups and deduping byplace_idgot us to 98. - One LLM call vs. one-per-question. Asking five questions in a single
<Gather>and parsing the wall of speech afterwards was unreliable — the model dropped questions and invented answers. Rebuilding as a chained one-question-at-a-time flow with per-step LLM parsing was a major accuracy win. - WebM corruption.
MediaRecorder.start(200)with a timeslice produced incomplete WebM containers on short button presses. ElevenLabs rejected them as corrupted. Fix: single chunk per recording. - Cloud Run state across webhooks. Twilio webhooks for one call hit our backend 5–10 times over ~60 seconds. Cloud Run's scale-to-zero raised our worry about state loss. In practice, the first
POST /api/call-restaurantwarms the instance and all subsequent webhooks land on the same warm instance — and the polling frontend keeps it warm too. No state loss observed. - ElevenLabs blocked on Cloud Run. After deploying, voice search returned no results in production. Logs revealed ElevenLabs returning 401 "detected_unusual_activity" for our Cloud Run datacenter IP. We migrated STT/TTS to Google Cloud Speech (same project, same IAM, no abuse detector to trigger), kept ElevenLabs as a local-dev fallback for nicer voices.
- Schema drift on a 4B model. Local Ollama Gemma 3 dropped JSON fields and missed obvious synonyms ("korean bbq" matched nothing). Migrating to Gemini 2.0 Flash with
response_mime_type=application/jsoncollapsed parse errors to nearly zero and made niche queries actually return results. - Panel state leak. Clicking a different restaurant left the previous one's call status visible (button stayed "complete"). One-line fix:
<RestaurantPanel key={selected.id} ... />forces React to remount with fresh state per restaurant.
Accomplishments that we're proud of
- An AI phone agent that holds a structured multi-turn conversation and returns clean ✓/✗/? answers — not just a transcript dump.
- A 3D filter animation that encodes information: building height = popularity, sinking = filtered out, spotlight = match. Judges grasp the result spatially before the cards even render.
- A graceful degradation chain at every layer: Gemini → Ollama → keyword heuristics; Google Cloud Speech → ElevenLabs → no-audio mode; LLM JSON parse fail → field defaults. Nothing is a single point of failure.
- End-to-end voice → filter → 3D animation → batch phone calls → structured answers in well under 90 seconds for a 3-restaurant query.
- Bilingual from day one — English and Korean queries both work, including the call agent's TTS and the custom-question translation.
- Live and deployed — anyone with the URL can try it right now: motzip.vercel.app.
What we learned
- One LLM call per question beats one LLM call for the whole transcript. Per-question accuracy went up dramatically when we stopped asking the model to disentangle multiple answers from one blob of speech.
- Schema-enforced JSON output is a game-changer for production.
response_mime_type=application/jsonmade our codefence-stripping and keyword-fallback code almost never trigger. - Datacenter IPs trigger abuse detectors on third-party APIs. ElevenLabs let us in from
localhostbut blocked us from Cloud Run as "unusual activity." Lesson: pick speech/LLM providers that authenticate with proper service accounts when deploying — Google Cloud's same-project, same-IAM auth had us in production in minutes. - 3D visualizations carry information weight. Watching buildings physically vanish communicates "this is no longer a candidate" faster than greying out a list row.
- Always have an offline path for a live demo. The Ollama and ElevenLabs fallbacks weren't features we planned — they were lessons from the first time wifi flickered and the first time Cloud Run blocked our STT.
What's next for MotZip
- Reservation booking, not just info. Once the agent confirms a table, let it book.
- Two-way negotiation. "If there's a 30+ min wait, ask if they can suggest a sister restaurant nearby."
- Crowd-sourced live state. Cache call results and reuse them for nearby users for the next 15 minutes — no need to call the same restaurant 50 times per night.
- Beyond Boston. The 3D pipeline is city-agnostic; we just need different building tiles.
- A "remember what I always ask" preference layer. Vegan, stroller, wheelchair — set once, apply to every search forever.
- Restaurant-side dashboard. Eventually MotZip becomes the demand signal that proves the data is worth maintaining, and restaurants publish answers themselves — and we stop calling.
Built With
- elevenlabs
- fastapi
- gemini
- google-places
- python
- three.js
- twilio



Log in or sign up for Devpost to join the conversation.