-
-

MotiSpectra Landing Page
-
More Information
-
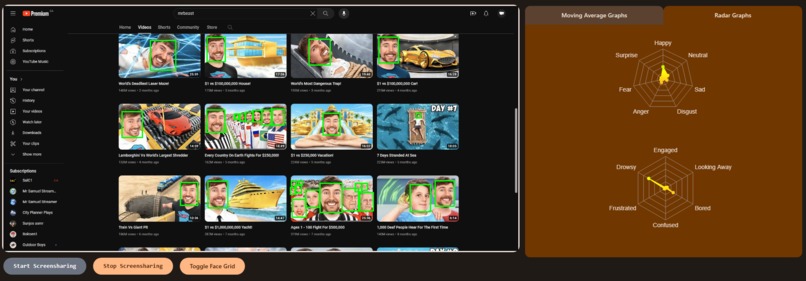
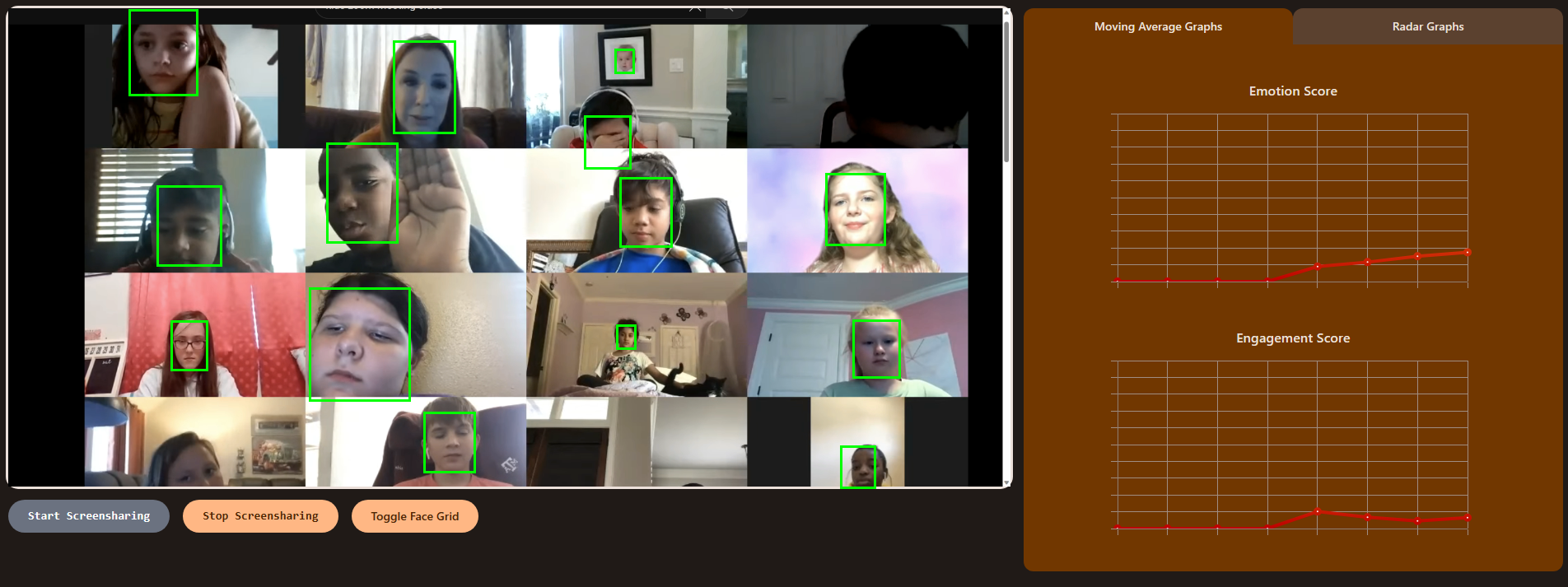
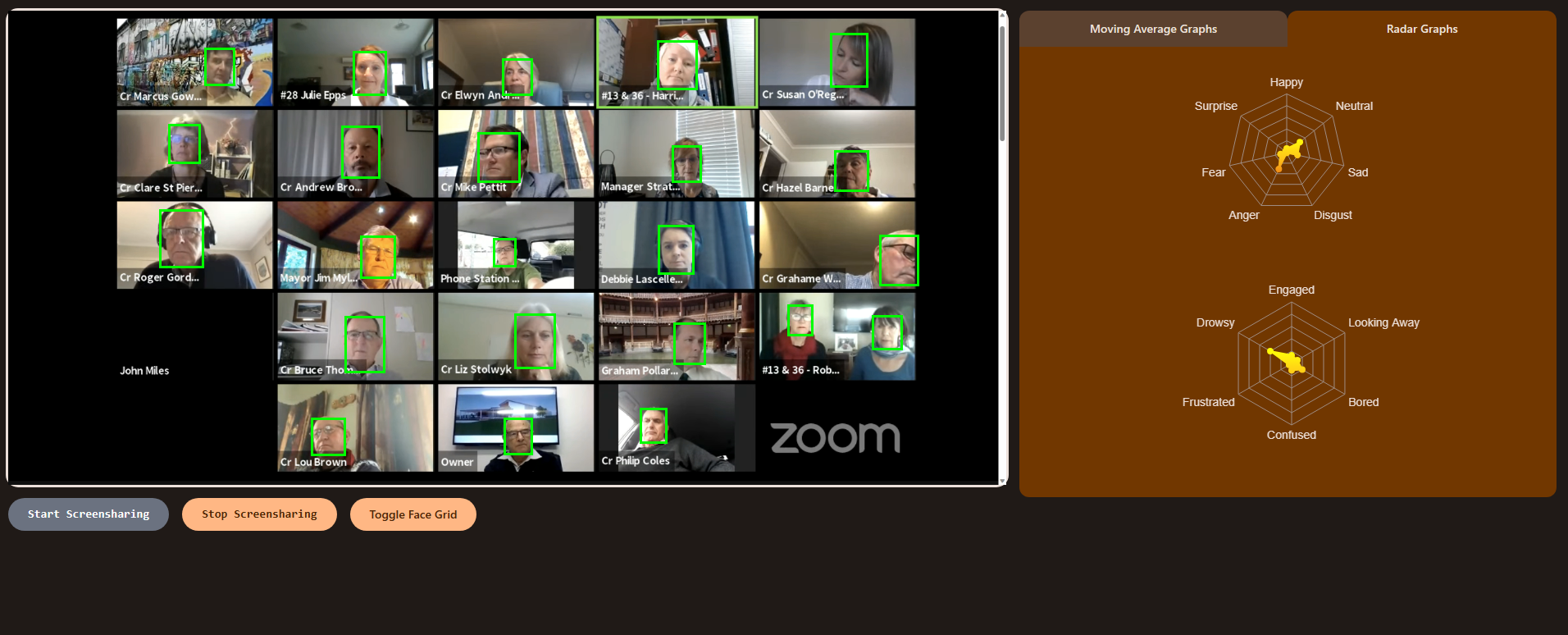
Share your screen to show your screen!
-
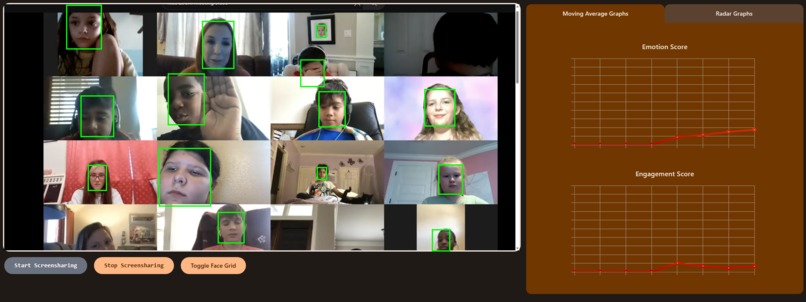
Moving Averages Graph
-
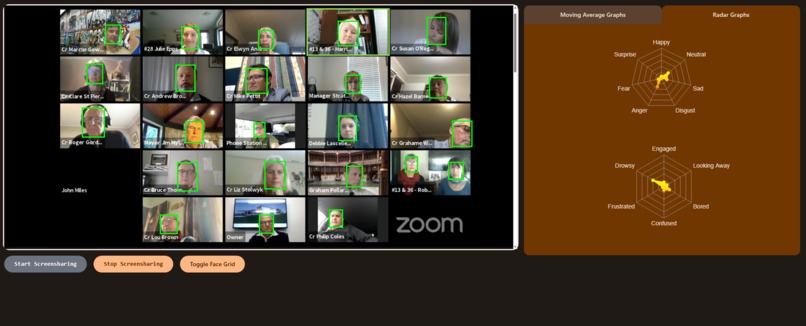
Radar Graph
-
Radar Graph showing positive emotions!

Inspiration
MotiSpectra is our answer to the awkwardness of online meetings, especially after COVID-19 turned everything virtual. We realized that emojis in chat just weren't cutting it, and there's so much more to a conversation than words. Inspired by the 7-38-55 Rule, which proclaims that only 7% of our communication comes verbally, we decided to create a tool that helps you read the room, or in this case, the screen. With MotiSpectra, you can finally figure out if your coworker is pumped or just zoning out, making those virtual meetings a tad less robotic and much more human. It's like bringing back the vibes of in-person chats (without leaving your comfy home office chair!)
What it does
- Seamlessly connects with a virtual call window (Zoom, Google Meet, Teams, etc.)
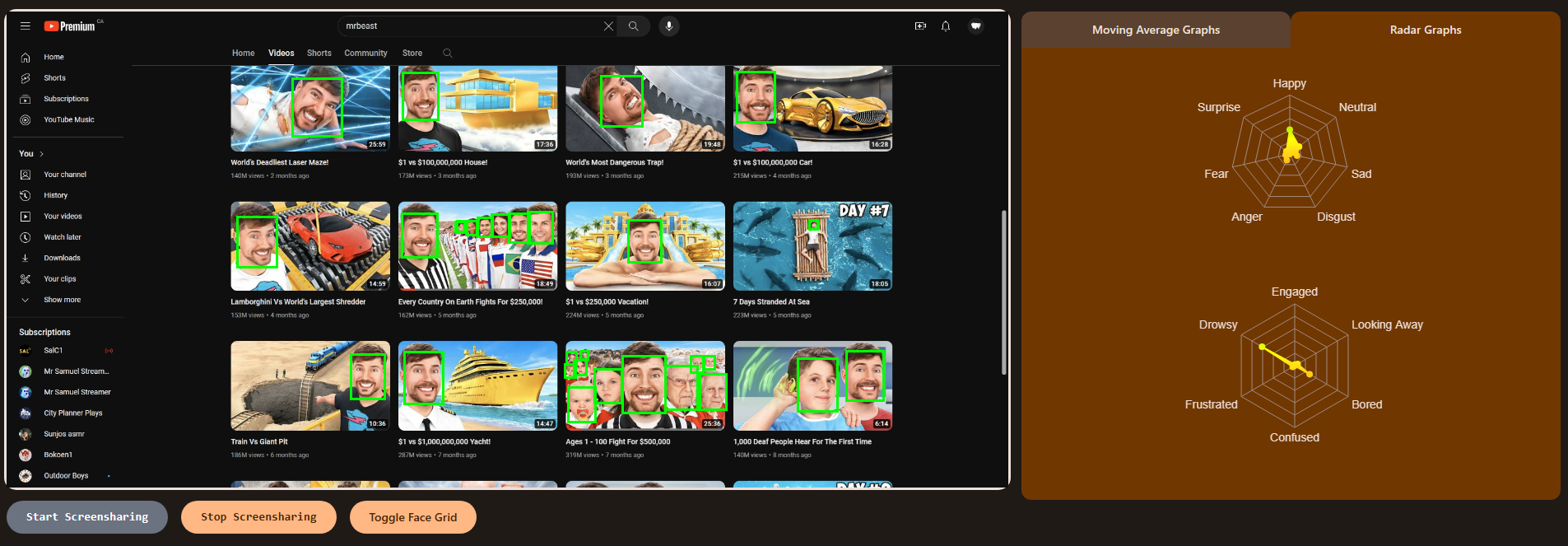
- Specially trained machine learning models analyze call participants' faces to determine both emotion and attentiveness
- Rolling average and radar graphs to smoothly display the emotion and attentiveness data of each participant
- Easily toggle meeting overlays to display face-detecting squares
How we built it
We built and trained two models from scratch using the FER-2013 dataset (for emotions), as well as our own modified dataset for attentiveness. Furthermore, we image-augmented the two datasets to allow the models to work better for faces in a video call. We also intensively fine-tuned the YuNet deep neural network model from the OpenCV library to better detect participants' faces with a high rate of success and accuracy. We used Python as the backend, and Flask as the frontend.
Challenges we ran into
- Training the models was a bit difficult, as our dataset at first did not have enough variety of images
- Detecting the small, low-quality faces of virtual meeting participants proved to be extremely difficult for pre-built face detection models (we ended up fine-tuning the YuNet face detection model to better detect the participants' faces)
Accomplishments that we're proud of
- First time we extensively explored the upper limits of computer vision and object detection models
- Training two machine learning models from scratch is 24 hours
- Each person in the group worked on different parts, allowing us to accomplish much more in a shorter time
What we learned
- How to effectively train machine learning models to detect human faces, and determine its emotions
- Using convolutional neural networks to train models, and augmentation tools to better prepare model datasets
What's next for MotiSpectra
- Improve latency times for the frontend display
- Train more advanced models to more accurately determine facial emotions in detail
- Implement a review feature at the end of a virtual meeting to allow users to watch back meeting recordings and emotions
Built With
- computer-vision
- machine-learning
- nextjs
- opencv
- python







Log in or sign up for Devpost to join the conversation.