-
-

Frontpage
-
Problem Info Page
-

Statistic 1
-

Statistic 2
-

Statistic 3
-

Why Motif?
-

What is Motif?
-

Motif Input Prompt
-

Motif Data Viz
-

API Response










Inspiration
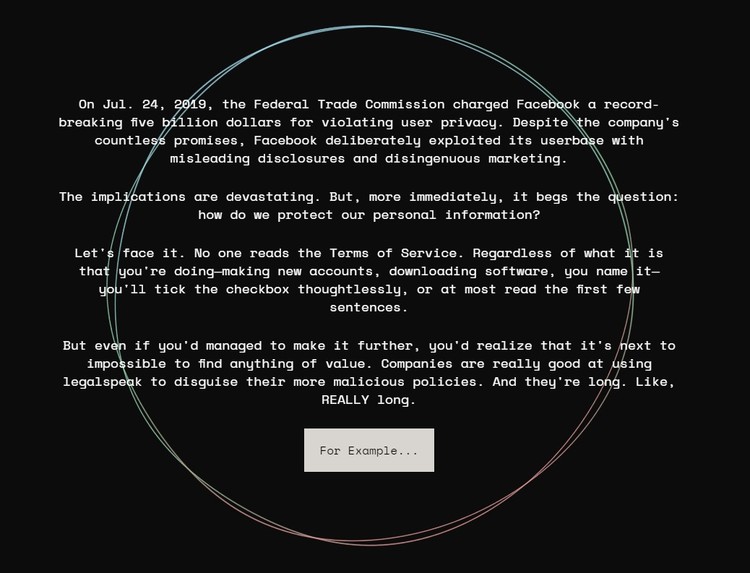
We initially thought of doing this project because we all are proponents of privacy friendly products. On the daily, we use Brave and open source software, and we absolutely hate when companies don't respect user privacy. For example, on Jul. 24, 2019, the Federal Trade Commission charged Facebook a record-breaking five billion dollars for violating user privacy. Despite the company's countless promises, Facebook deliberately exploited its user base with misleading disclosures and disingenuous marketing.
We took a critical look into how companies and services achieve this and found that often these suspicious breaches of privacy often stem from their Terms of Service. However, we felt that no one actually reads the Terms of Service. Regardless of what it is that people were doing—making new accounts, downloading software, you name it—they would just tick the checkbox thoughtlessly, or at most read the first few sentences. This is a huge issue as if companies are using the Terms of Service to breach privacy, and users aren't actually looking at it, then users aren't actually being educated on the subject and are sitting ducks.
We did some market research and found that were was no automated, Natural Language Processing (NLP) based solution for determining the validity/maliciousness of a Terms of Service on the fly that could achieve these 3 concepts:
- Simplistic but significant statistics to determine an answer
- Understanding the holistic language of the document
- Super fast and performant
What it does
Motif is a simple Natural Language Processing and Distributed System website, giving you straightforward results on how privacy-friendly a service is based on their Terms of Service. If you provide a URL to a terms of service, it will automatically extract the text content from the page, perform analysis on it. It them provides a TL;DR verdict, solid numbers, and data visualization on the severity of the verdict.
How We built it
Our project consists of three parts - the client, server, and API.
The Client is made with HTML/SASS/JavaScript, Lucia.js, Parcel+Babel, GSAP, FontAwesome, and Odometer. It is hosted on Netlify, which is pipelined from a Github repository we have.
The Server handles all the requests from the client and is the bridge between the client and the API nodes. It also does MongoDB caching and is made with Golang+Gin, and MongoDB. It is hosted on Repl.it.
The REST API does all the heavy work, which is made with TypeScript, ExpressJS (NodeJS internally), node-fetch+cheerio, and NaturalJS for natural language processing. It first fetches the content of the ToS with node-fetch and cleans it up with cheerio. For NLP, it utilizes these methods through sentence by sentence analysis:
- Static Keyword Matching: compiled list of common suspicious keywords that occur in ToS, matched against content
- Sentiment Analysis: determines the sentiment of a phrase (ex. "I hate you" has a negative sentiment score, "I love you" has a positive sentiment, "I really love you" has a high positive sentiment)
- Bayesian and Logistic Regression Classification: trained AI model that determines whether a phrase can be categorized as "good" or "bad" in the context of ToS legalspeak.
- Gender Bias Analysis: determines whether there is a code bias based on how many gender specific codings it finds.
All of these are daisy-chained together to produce a fully-functional web application that users are able to use.
Challenges We ran into
We ran into several issues:
- Hosting: We had troubles with finding good free hosting (as we have no monies 😔), and we had troubles pipelining Github to AWS Amplify, so we decided to try out Repl.it and it worked great!
- Finalizing an Idea: We pivoted 3 times in one day - we first started with scam detection software, then a theme customizer, and finally stopped with this idea.
- Learning about NLP: We had trouble getting Bayesian & Logistical Regression methodologies to work with our sample data, so we spent a TON of time tweaking the data to return accurate results.
- Library compatibility: It was hard getting so many libraries in the Client to work well together, especially GSAP which was a pain in the animation to get working with our setup.
- Merge Conflicts on Github: Nothing needs to be said about this - these suck.
Accomplishments that We're proud of
- Accurate Results: Our NLP model and API provide accurate data, thanks to tons of tweaking and retraining.
- Sleek Design/UI: We spent a lot of time making sure the design looked great and pleasing to the eye with a great UI/UX
- Teamwork and Fun: We bonded together a ton and made some really good memories working with each other.
- Intentional Product and Storyline: We believe that a story is more memorable and impactful than just a basic website, so we created a whole journey instead, which turned out really nice.
- Performance: Motif is remarkably fast, thanks to the many optimizations and architectural decision we made to be so, such as using Go for the main server, natural for NLP, type validation, and post processing on Netlify.
What we learned
- Using and understanding NLP methodologies, as well as daisy chaining repl.it.
- Making a product isn't easy and requires a lot of work. Be ready to accept something, even if it isn't perfect.
- Most importantly, we learned about the value of teamwork, compassion, and friendship, and how connections you make directly impact the value you create.
What's next for Motif
- Scale Motif with AWS or some other cloud SaaS
- Create browser extensions so that visiting is automatic
- Update data models through training, more **specific training so that areas like data tracking, children, etc can be shown
- Make the UX better, with better user flow and data visualization
- Promote the product to others on Dev.to, Producthunt, and YC Hacker News
Shoot us a comment if you want to have a coffee chat over Zoom 😃
Made with 😢 + ❤️ by Tejas Agarwal, Aiden Bai, Melinda Chang, William Lane
Built With
- babel
- css
- css3
- express.js
- font-awesome
- gin
- github
- github-platform
- go
- html
- html5
- javascript
- lucia
- mongodb
- natural-language-processing
- netlify
- node.js
- odometer
- parcel
- repl
- sass
- scrum
- typescript









Log in or sign up for Devpost to join the conversation.