-
-
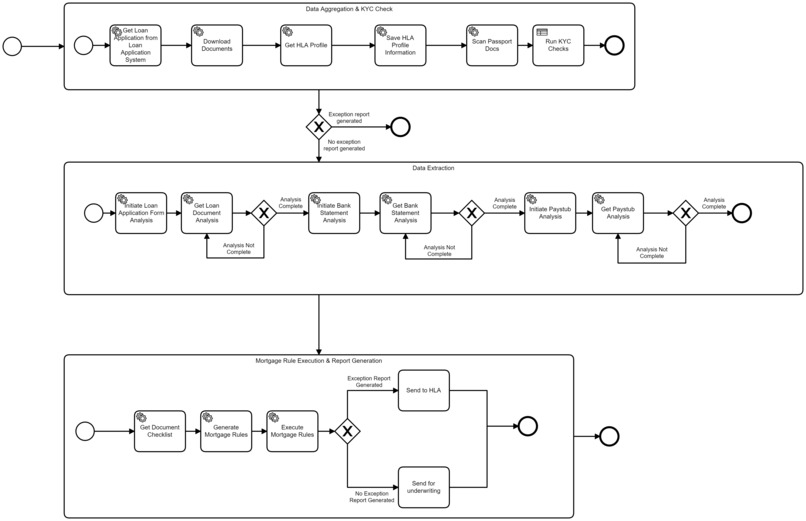
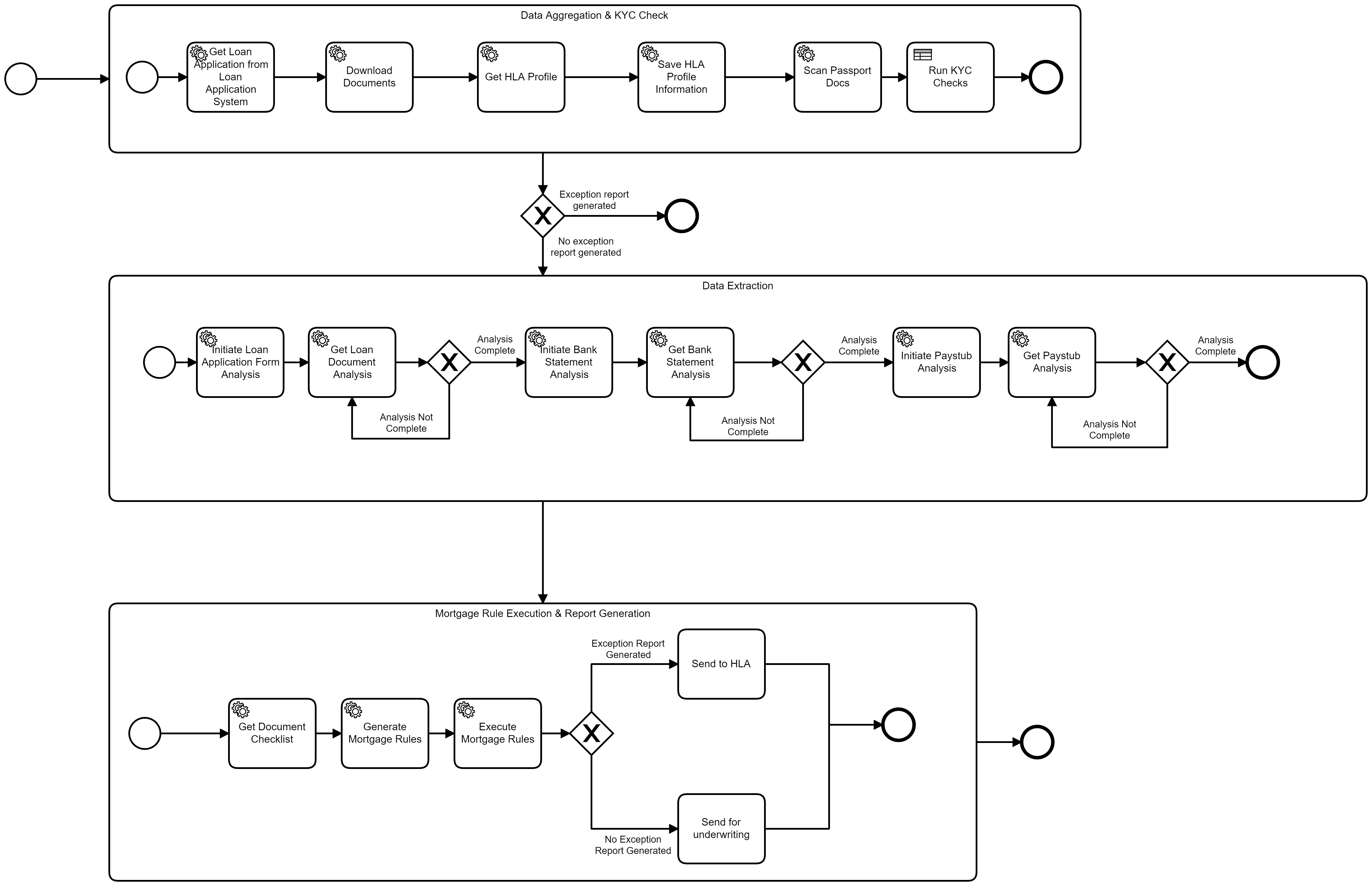
Camunda Workflow
-
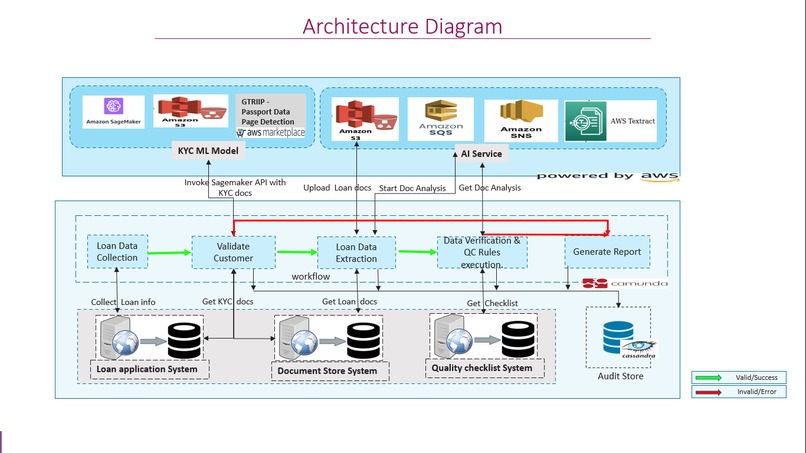
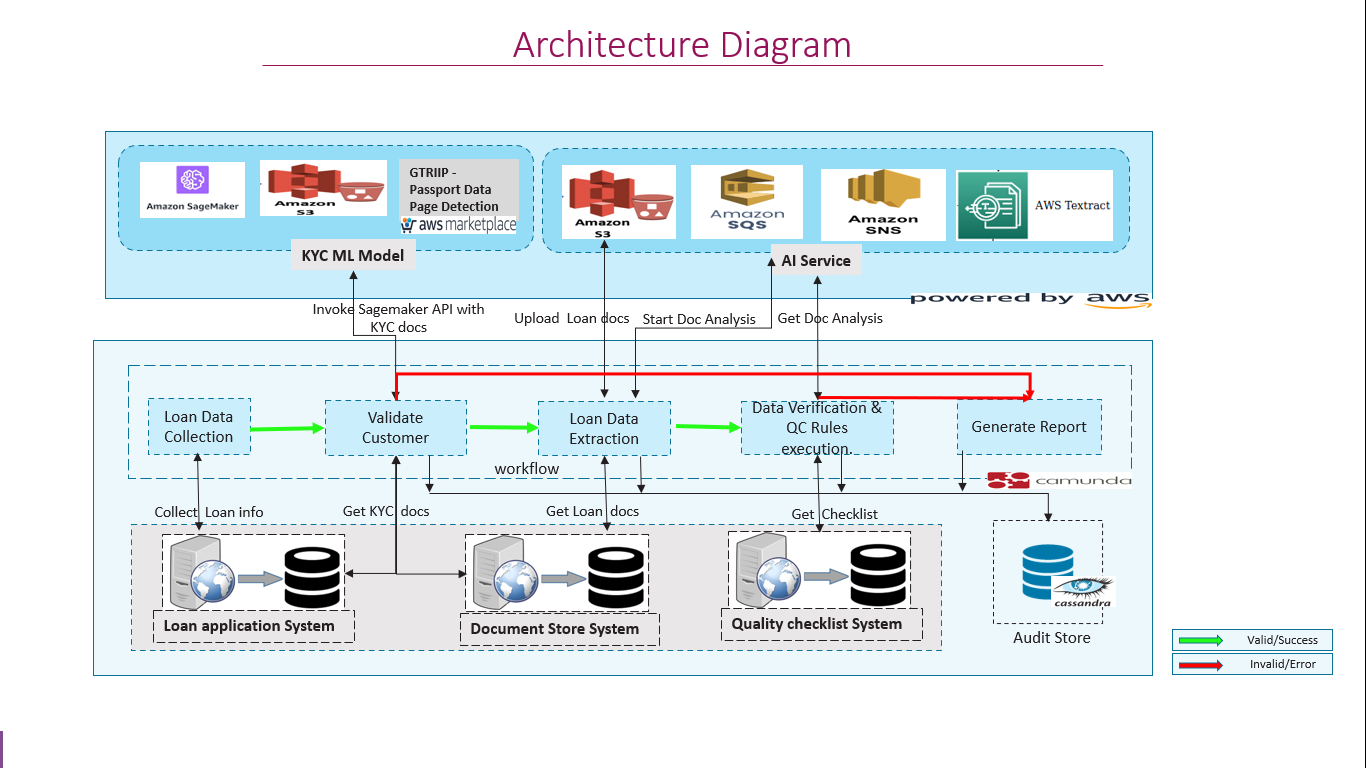
Architecture Diagram
Inspiration
Mortgage Loan origination is the process by which a borrower applies for a new loan, and a lender processes that application to grant the mortgage loan. It's observed that the pre-ops stage is mostly manual, Pre-ops stages for Loan Origination may vary depending on the organization(s) but generally, can be broadly classified into 3 stages which includes 'Pre-qualification'(Documents submission), 'Loan Application'(Form filling) and 'Application processing'. While processing the applications, it is reviewed for accuracy and completeness,Like, All required fields must be filled in and accurate, All supporting documents should be submitted...etc otherwise the application is returned to the Borrower/House Loan Agent. If all the requirements match and the application is deemed complete, the 'Underwriting' stage/process begins.
Organizations mostly perform 'Quality Control' checks manually, by verifying data across multiple systems and validating it with various business rules. As a result, Organizations incur huge costs in Pre-ops process and As the process is manual, it's time consuming and prone to errors.
Automating the pre-ops process would make the process faster, improve the quality, reduces the risk, and most importantly reduces the 'Loan Origination' costs. Today, we can possibly, automate the pre-ops process. Thanks to advancement in the technologies like OCR, Machine learning and Workflows.
What it does
Provides an AI based platform to automate the process of Mortgage Loan verification.
How we built it
We have used 'GTRIIP Passport Data Page Detection' ML model to suffice KYC component of the 'Pre-ops' process and Amazon Textract to extract data from the Loan application form and supporting documents(Ex: Bank Statement,Pay Stub). The back-end services like 'Loan Application system', 'QC system' are mocked for the PoC purposes. The platform connecting these various systems is implemented using Camunda BPM and workflow.
Challenges we ran into
- 'GTRIIP Passport Data Page Detection' ML model captures digit '4' in the passport document as digit '6'.
- 'GTRIIP Passport Data Page Detection' ML model did not capture the name properly, character 't' was captured as 'i' Ex: passport had first name 'Rohit' and the model output name was 'Rohii' Due to this issue, we had to stub the 'name check' rule and mock data as per ML model's output.
- 'AWS Textract' does not perform classification and identify the type of document, Document aliasing is quite time consuming manual process. However, we had to ingest 'document type' related mocking.
Accomplishments that we're proud of
We were quick enough to learn and understand the curated list of ML models and its usage, AWS Textract AI service and other services along with AWS Java SDK and bring it all together as a workflow platform. We see that the 'AI based business operations' idea has a great potential.
What we learned
We learnt a lot more about AWS services AWS Marketplace, AWS Sagemaker Inferencing, SQS, SNS and Textract.
What's next for Mortgage Ops
Apply more business rules, Identify/Implement tool to recognize the 'type of supporting document' to automate document aliasing. Implement/Identify tool to recognize documents with changes only, to avoid repetitive processing of all documents along with changed document.
Built With
- ai
- camunda
- cassandra
- java
- machine-learning
- sagemaker
- texttract







Log in or sign up for Devpost to join the conversation.