-
-
Dashboard
Inspiration
Every AI system in the world today is frozen. The moment a model finishes training, its weights never change again. You can give it memory, you can give it retrieval, but the underlying model, the parameters that determine how it reasons, stay fixed forever. We kept asking the same question: what if a deployed model could actually learn from the conversation it was having, right now, on consumer hardware?
That question became Morpheus.
What It Does
Morpheus is a multi-agent pipeline where a local LLM updates its own LoRA adapter weights in real time, turn by turn, during a live conversation. Claude Sonnet acts as an automated critic, evaluating every response, scoring it 0–10, and generating an ideal answer that becomes the training target. A background training thread runs concurrently on the same GPU, updating the model between turns.
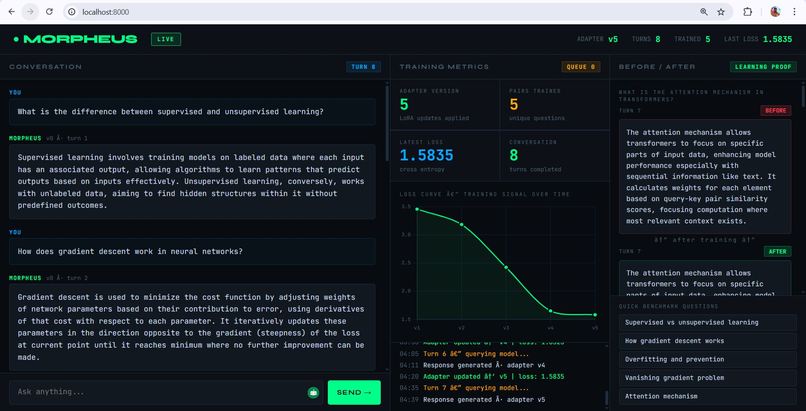
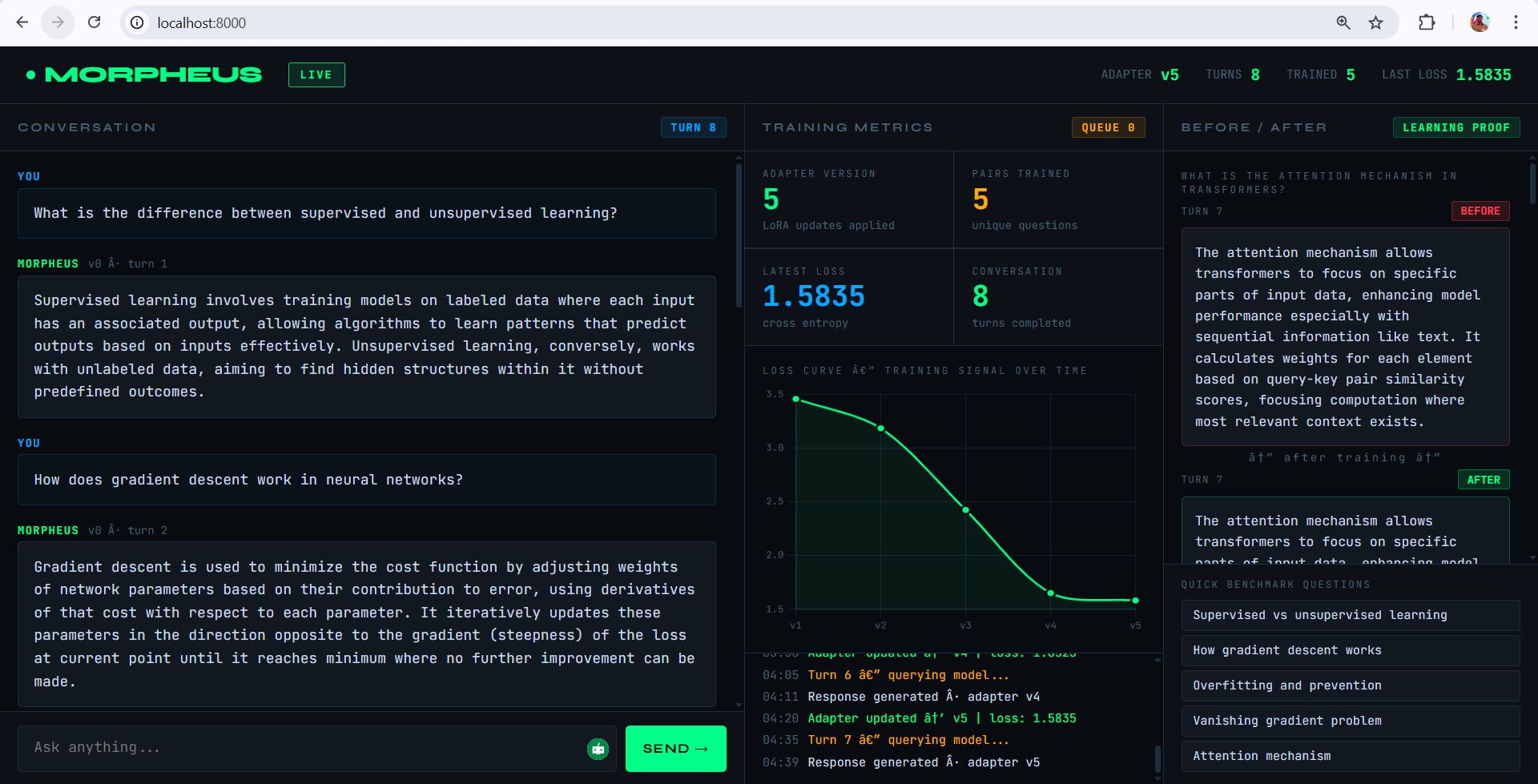
The result: the model at turn 6 is measurably different from the model at turn 1. In our validated demo run, training loss dropped from 3.70 → 3.44 → 2.57 → 2.07 → 1.44 across five consecutive updates, each taking under two seconds.
How I Built It
Architecture
The pipeline has four components running concurrently:
1. Local Model Layer Qwen 2.5-3B-Instruct loaded at 4-bit NF4 quantization via Unsloth, using approximately 2.3 GB VRAM. LoRA adapters with rank $r = 16$ are attached to all attention and MLP projection layers, making approximately 0.96% of total parameters trainable:
$$\text{trainable params} = \frac{29{,}933{,}568}{3{,}115{,}872{,}256} \approx 0.96\%$$
The LoRA update rule adds low-rank matrices to each frozen weight:
$$W' = W + \frac{\alpha}{r} \cdot BA$$
where $W \in \mathbb{R}^{d \times k}$, $B \in \mathbb{R}^{d \times r}$, $A \in \mathbb{R}^{r \times k}$, and $r \ll \min(d, k)$.
2. Critic Agent Every (question, answer) pair is sent to Claude Sonnet via the Anthropic API with a structured JSON schema. Claude returns a score, what was wrong, and an ideal answer capped at 120 words, short enough to be a reachable training target for a 3B model.
3. Curator A training queue with a per-question blacklist. Once a question is trained on, it is permanently skipped. This prevents the weight collapse that occurs when a model memorizes a single example through repeated gradient updates.
4. Async Trainer
A background threading.Thread that acquires a swap_lock between inference turns runs 2 gradient steps using HuggingFace Trainer with batch size 1, saves the updated adapter, and releases the lock. The base model weights remain frozen throughout, only the LoRA adapter parameters change.
Concurrent Inference and Training
The core engineering challenge was running inference and training on the same GPU without memory collisions. We solve this with a threading lock acquired strictly between turns:
Turn N ends → swap_lock acquired → 2 gradient steps → adapter saved → lock released → Turn N+1 begins
The model never reads and writes weights simultaneously.
Windows + CUDA 11.8 Compatibility
Unsloth's Triton kernels do not compile on CUDA 11.8 / Windows. We identified and patched four kernel files with standard PyTorch fallbacks:
rms_layernorm.py— replacedFast_RMS_Layernormwith PyTorch RMS normrope_embedding.py— replacedfast_rope_embeddingwith a seq_len-aware PyTorch RoPE implementationswiglu.py— replaced both forward (swiglu_fg_kernel) and backward (swiglu_DWf_DW_dfg_kernel) Triton kernels withF.silu(e) * gllama.py— patched the inference-path RoPE inLlamaAttention_fast_forward_inferenceto handle the cos/sin shape mismatch between prefill and autoregressive generation
Challenges
Concurrent CUDA access was the hardest problem. Running a training backward pass and an inference forward pass on the same GPU naively causes memory corruption. The threading lock approach works but requires careful placement, acquiring the lock after generation completes, not before.
Model selection took significant iteration. Phi-4-mini was our first choice and failed after just five training steps; catastrophic output degradation was caused by quantization instability under concurrent LoRA updates. Qwen 2.5-3B proved stable across repeated micro-batch updates while fitting within the 6 GB VRAM budget.
Triton kernel patching on Windows required reverse engineering. Unsloth's kernel dispatch logic across four files to replace GPU-compiled Triton kernels with numerically equivalent PyTorch operations. Getting the RoPE patch correct for both prefill (full sequence) and autoregressive (single token) generation paths required careful handling of the cos/sin tensor shapes which differ between the two code paths.
Preventing training collapse required the curator blacklist. Without it, repeated training on the same question causes the model to memorize that single example and degrade on everything else, a failure mode we encountered and solved.
Accomplishments
- Concurrent inference and LoRA training on a single consumer GPU (RTX 3060, 6 GB VRAM) with no memory collisions
- Training loss dropping from 3.70 to 1.44 across five consecutive updates in a single three-minute conversation
- A fully functional live dashboard showing the loss curve, adapter version, and before/after comparison updating in real time
- A working system end-to-end on Windows with CUDA 11.8, a notoriously difficult environment for Unsloth, through surgical kernel-level patches
What I Learned
- LoRA's mathematical elegance - representing weight updates as $\Delta W = BA$ with $r \ll d$ — is what makes real-time training on consumer hardware possible at all. Without it, a single gradient step on a 3B model would require more memory than the entire GPU.
- The separation of roles between the local model and Claude is load-bearing. The local model needs to be trainable; Claude needs to be accurate. Conflating those requirements into one model does not work at this scale.
- Threading on CUDA is unforgiving. A lock in the wrong place causes silent memory corruption. A lock in the right place adds negligible latency.
- Model selection for concurrent training is not the same as model selection for inference quality. Stability under gradient updates is a distinct property from output quality.
What's Next
- Longer conversations - extending the system to accumulate training signal across sessions, not just within one conversation
- Better training strategies - experimenting with DPO and GRPO instead of supervised fine-tuning for more robust learning signal
- Multi-GPU support- separating inference and training onto different GPUs to remove the lock bottleneck entirely
- Broader model support - testing Llama 3.2, Mistral, and Gemma architectures under the same concurrent training regime
- Productionization - packaging the Triton patches and threading architecture as a reusable library for any deployment scenario requiring live model updates

Log in or sign up for Devpost to join the conversation.