-
-

moot
-
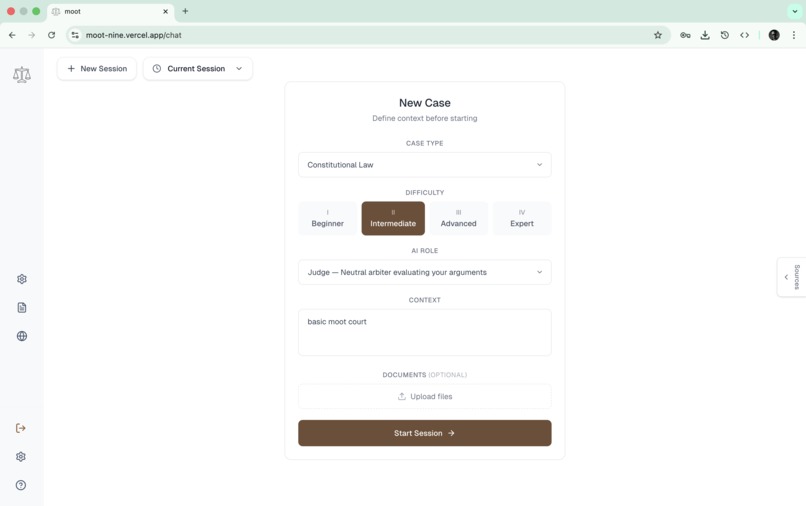
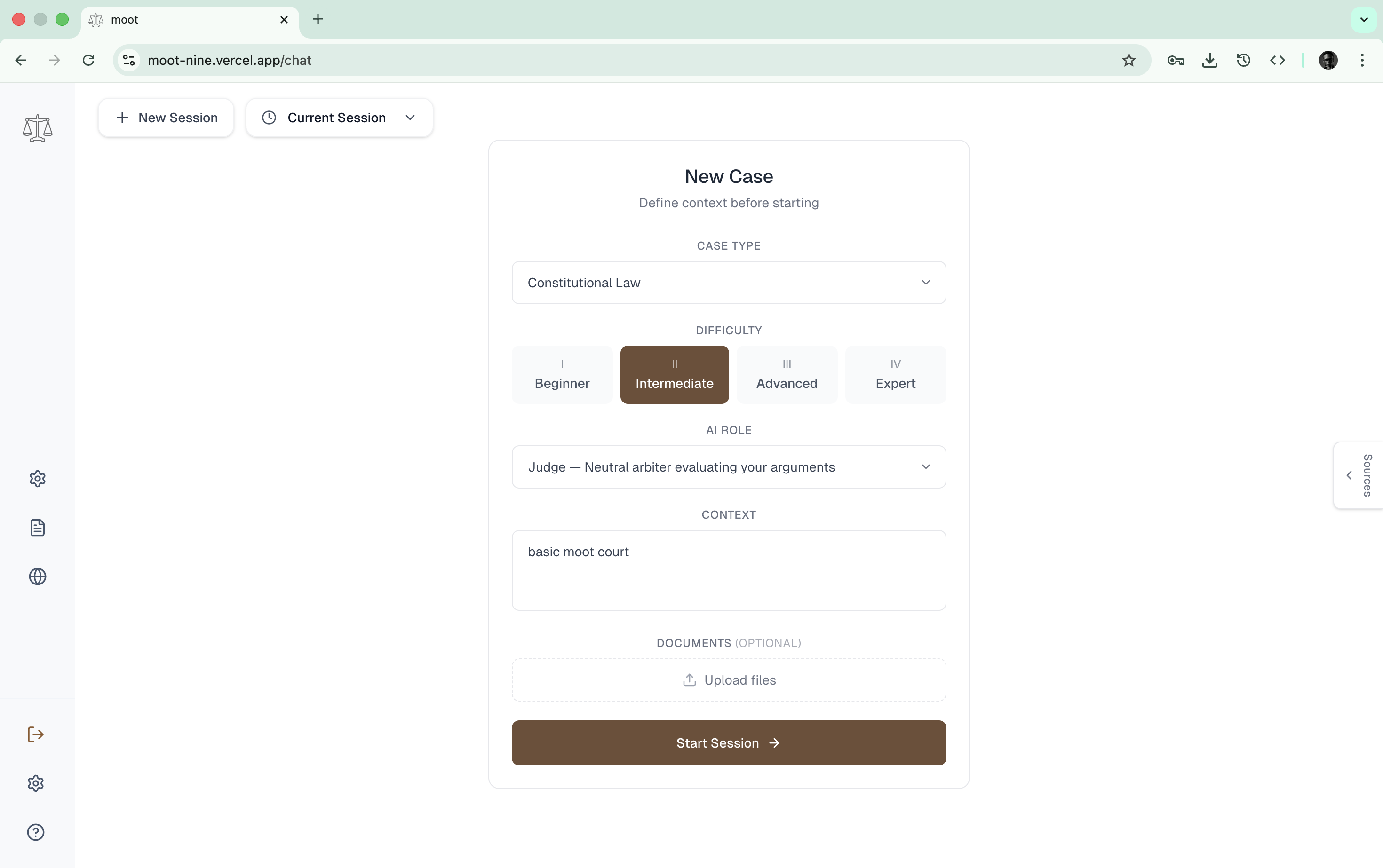
session selection
-
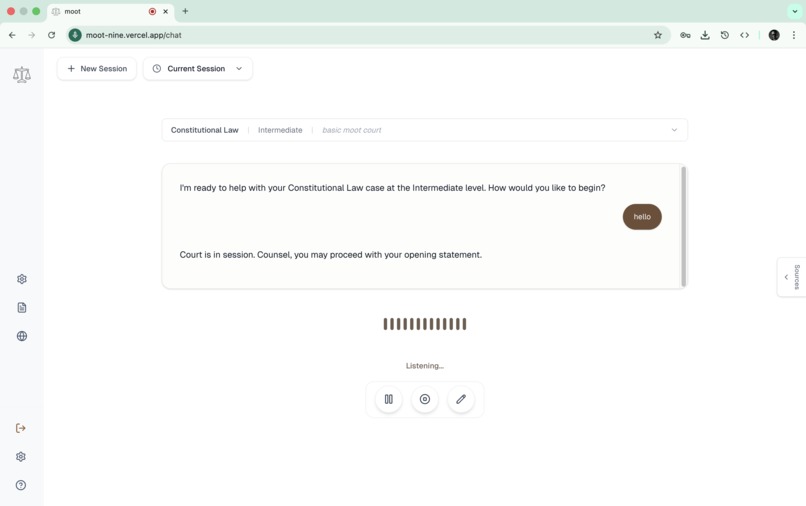
voice based ui
-
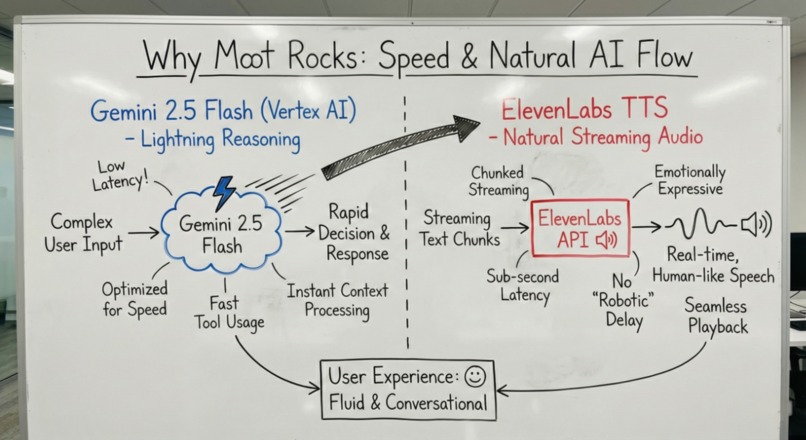
gemini + 11labs intergration
-
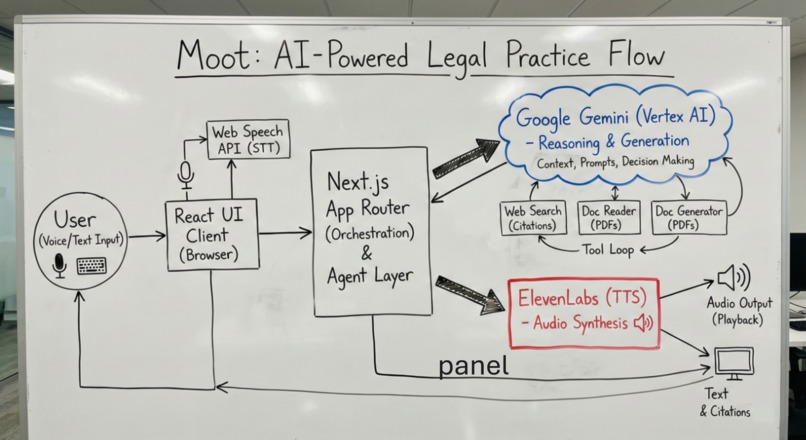
why moot is epic


Moot
AI-powered legal practice platform for moot court preparation, case analysis, and oral argument training.
Inspiration
Law students and legal professionals face significant barriers when preparing for moot court competitions and oral arguments. Finding qualified practice partners to simulate opposing counsel or judicial questioning is expensive and difficult to schedule. Traditional preparation methods are text-heavy, yet real courtroom advocacy demands verbal articulation under pressure. Legal research, document analysis, and argument practice happen across fragmented tools with no unified workflow.
We built Moot to democratize access to rigorous legal practice. Every aspiring advocate deserves a tireless practice partner who can challenge their arguments with real case law, adapt to different courtroom roles, and provide immediate voice-based feedback.
What it does
Moot is an AI-powered legal practice platform that transforms how law students and professionals prepare for oral arguments. Users engage in real-time voice conversations with an AI that dynamically assumes courtroom roles:
| Persona | Behavior |
|---|---|
| Opposing Counsel | Challenges every argument with cited case law, generates counter-briefs, exploits weaknesses relentlessly |
| Judge | Demands citations, asks probing questions, evaluates argument merit with judicial neutrality |
| Witness | Responds only to questions asked, maintains caution during cross-examination |
| Mentor | Provides strategic coaching and honest critical feedback |
| Legal Assistant | Guides research and case preparation supportively |
Core Capabilities
Voice-First Interaction: Users speak naturally and receive spoken responses, simulating real courtroom dynamics. The system manages bidirectional audio to prevent feedback loops.
Live Legal Research: The AI searches case law and statutes in real-time, returning results with proper citations that appear in a dedicated sources panel.
Document Intelligence: Upload case documents for AI analysis. Generate professional legal documents including memos, briefs, summaries, and contract drafts as downloadable PDFs.
Adaptive Difficulty: Configure session difficulty from beginner to expert, adjusting how aggressively the AI challenges arguments.
How we built it
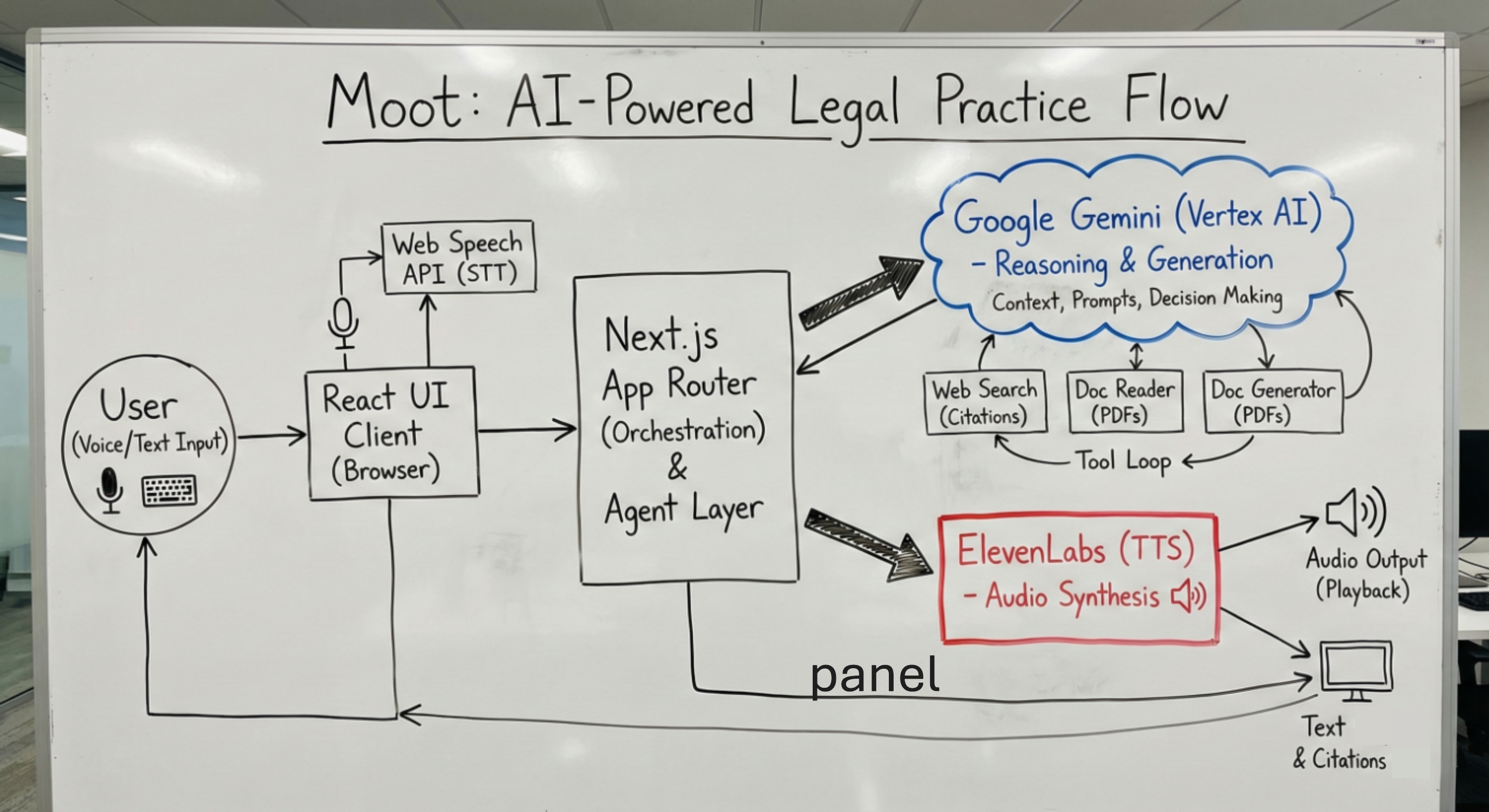
System Architecture
┌─────────────────────────────────────────────────────────────────────────────────┐
│ SYSTEM ARCHITECTURE │
└─────────────────────────────────────────────────────────────────────────────────┘
┌─────────────────────────────┐
│ BROWSER CLIENT │
├─────────────────────────────┤
│ • React Components │
│ • Web Speech API │
│ • Audio Queue │
└──────────────┬──────────────┘
│
▼
┌─────────────────────────────┐ ┌─────────────────────────────┐
│ NEXT.JS APP ROUTER │ │ EXTERNAL SERVICES │
├─────────────────────────────┤ ├─────────────────────────────┤
│ /api/chat │◄────▶│ Gemini 2.5 Flash │
│ /api/upload-pdf │◄────▶│ ElevenLabs TTS │
│ /api/voices │◄────▶│ Perplexity Sonar │
│ /api/documents │◄────▶│ Vercel KV │
└──────────────┬──────────────┘ └─────────────────────────────┘
│
▼
┌─────────────────────────────┐
│ LEGAL AGENT LAYER │
├─────────────────────────────┤
│ Google ADK Runner │
│ Session Manager │
│ │
│ ┌────────────────────────┐ │
│ │ AGENT TOOLS │ │
│ ├────────────────────────┤ │
│ │ • Web Search │ │
│ │ • Document Reader │ │
│ │ • Document Generator │ │
│ │ • Provide Link │ │
│ └────────────────────────┘ │
└─────────────────────────────┘
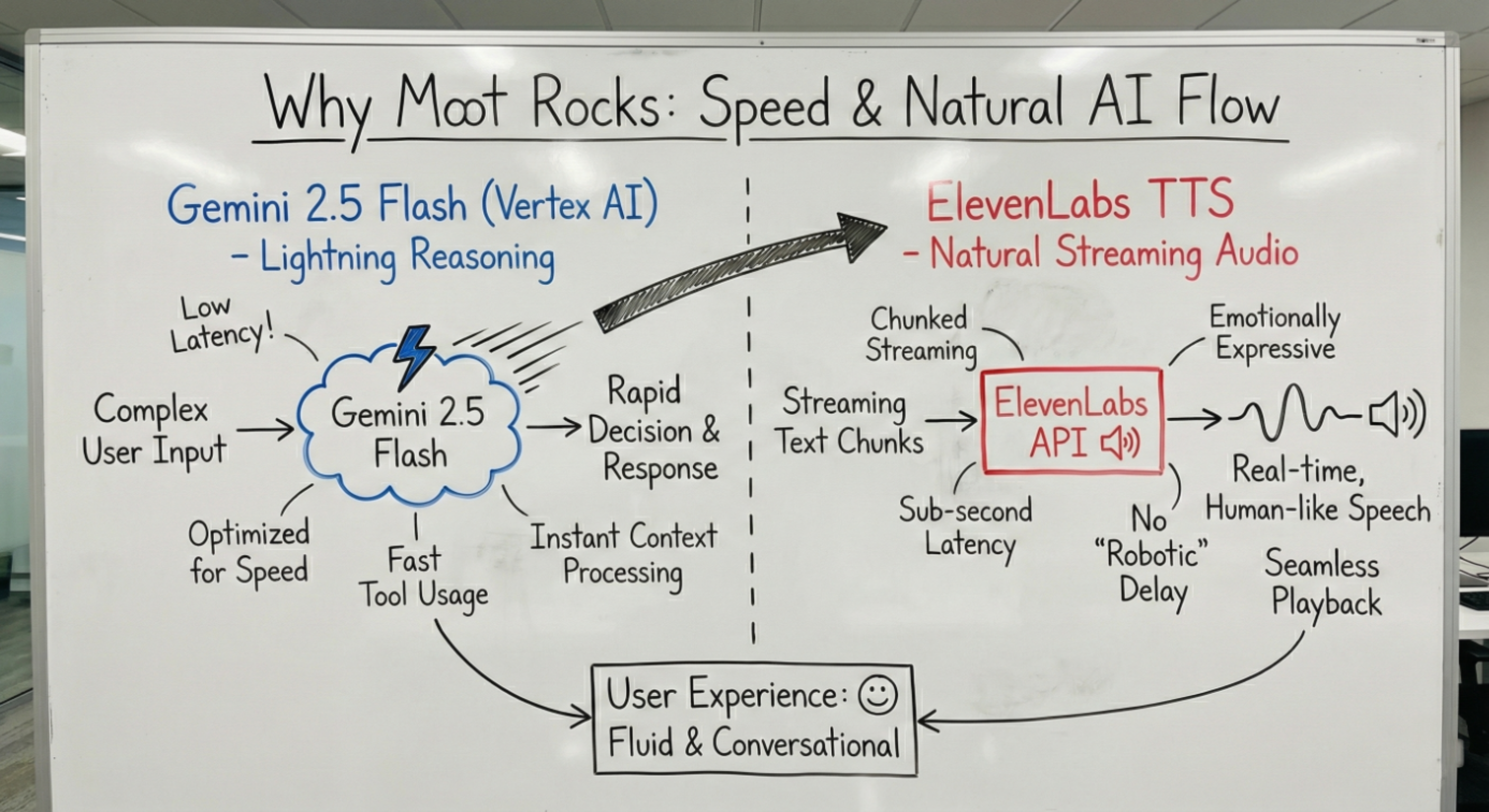
Google Gemini Integration
Moot uses Gemini 2.5 Flash as its core reasoning engine through the Google Agent Development Kit (ADK).
Why Gemini 2.5 Flash:
- Optimized for low-latency streaming responses critical for voice conversations
- Strong legal reasoning and citation comprehension
- Native function calling for reliable tool orchestration
- Cost-effective for extended practice sessions
┌─────────────────────────────────────────────────────────────────────────────────┐
│ GEMINI TOOL ORCHESTRATION │
└─────────────────────────────────────────────────────────────────────────────────┘
┌─────────────────────┐
│ Gemini 2.5 Flash │
│ (Legal Agent) │
└─────────┬───────────┘
│
┌─────────────────────────┼─────────────────────────┐
│ │ │
▼ ▼ ▼
┌────────────────┐ ┌────────────────┐ ┌────────────────┐
│ web_search │ │ read_document │ │generate_document│
├────────────────┤ ├────────────────┤ ├────────────────┤
│ Perplexity API │ │ Vercel KV │ │ jsPDF │
│ Returns: │ │ Returns: │ │ Returns: │
│ • Citations │ │ • Content │ │ • Download URL│
└────────────────┘ └────────────────┘ └────────────────┘
│ │ │
└─────────────────────────┴─────────────────────────┘
│
▼
┌─────────────────────┐
│ Response with │
│ Real Citations │
└─────────────────────┘
Tool Orchestration: The ADK Runner manages tool execution automatically. When Gemini determines it needs case law, it issues a function call to web_search. The runner executes the Perplexity query, returns citations, and Gemini incorporates them into its response.
Session Management: The ADK InMemorySessionService maintains conversation history automatically. Case context including persona instructions is injected at the start of each session and persisted for continuity.
ElevenLabs Integration
ElevenLabs provides text-to-speech synthesis for natural voice output.
┌─────────────────────────────────────────────────────────────────────────────────┐
│ VOICE OUTPUT PIPELINE │
└─────────────────────────────────────────────────────────────────────────────────┘
Legal Agent /api/chat ElevenLabs API Browser
│ │ │ │
│ Final Response │ │ │
│────────────────────▶│ │ │
│ │ │ │
│ │ Strip Markdown │ │
│ │ Split Sentences │ │
│ │ │ │
│ │ Generate Speech │ │
│ │────────────────────▶│ │
│ │ │ │
│ │◀────────────────────│ │
│ │ Audio (Base64) │ │
│ │ │ │
│ │ SSE audio event │ │
│ │─────────────────────────────────────────▶│
│ │ │ │
│ │ │ Queue Audio │
│ │ │ Play Chunks │
│ │ │ Mute Mic │
│ │ │ │
Voice Pipeline:
- Agent response is stripped of markdown and URLs for natural speech
- Text is split on sentence boundaries for chunked delivery
- Each chunk is sent to ElevenLabs eleven_flash_v2_5 model
- Audio streams back as base64-encoded SSE events
- Client queues chunks for gapless playback
Feedback Prevention: The browser mutes the microphone during AI speech and maintains a 500ms cooldown after playback completes before re-enabling recognition.
Request Flow
┌─────────────────────────────────────────────────────────────────────────────────┐
│ COMPLETE REQUEST FLOW │
└─────────────────────────────────────────────────────────────────────────────────┘
User React UI /api/chat Legal Agent
│ │ │ │
│ Voice Input │ │ │
│─────────────────▶│ │ │
│ │ │ │
│ │ POST (SSE) │ │
│ │───────────────────▶│ │
│ │ │ │
│ │ │ Create Runner │
│ │ │───────────────────▶│
│ │ │ │
│ │ │ │
│ │ │ ┌───────────────────────┐
│ │ │ │ TOOL EXECUTION │
│ │ │ │ LOOP │
│ │ │ ├───────────────────────┤
│ │ │◀───│ Function Call │
│ │ │ │ Execute Tool │
│ │ │───▶│ Return Citations │
│ │ │ └───────────────────────┘
│ │ │ │
│ │◀───────────────────│◀───────────────────│
│ │ content events │ Final Response │
│ │ audio events │ │
│ │ citation events │ │
│ │ │ │
│◀─────────────────│ │ │
│ Display Text │ │ │
│ Play Audio │ │ │
│ │ │ │
Technology Stack
| Layer | Technology | Purpose |
|---|---|---|
| Frontend | Next.js 16, TypeScript, Tailwind CSS 4 | React framework with App Router |
| Voice Input | Web Speech API | Browser-native speech recognition |
| Voice Output | ElevenLabs eleven_flash_v2_5 | Low-latency text-to-speech |
| AI Reasoning | Google Gemini 2.5 Flash | Core LLM with function calling |
| Agent Framework | Google ADK | Tool orchestration and session management |
| Legal Search | Perplexity Sonar | Web search with citation extraction |
| Document Processing | unpdf, jsPDF | PDF parsing and generation |
| Persistence | Vercel KV | Redis-based document storage |
| Deployment | Vercel | Edge functions and hosting |
Challenges we ran into
Voice Feedback Prevention: When the AI speaks through device speakers, the microphone picks up its own voice, creating an infinite loop. We implemented a multi-layered solution: immediate microphone muting when AI starts responding, audio queue state tracking, and a 500ms cooldown after playback completes before re-enabling recognition.
React State Timing in Voice Callbacks: Speech recognition callbacks fire asynchronously. When a user speaks immediately after session setup, the React state for case context had not yet updated. We solved this by maintaining refs alongside state for values needed in callbacks, ensuring immediate access.
Streaming Response Coordination: The chat endpoint streams text content, audio chunks, tool calls, and citations simultaneously. Coordinating these different event types while maintaining proper sequencing required careful buffer management and event type handling in the SSE parser.
Persona Consistency: Early versions would occasionally forget the assigned persona mid-conversation. We now inject persona instructions with every message rather than just the first, ensuring the AI maintains its role throughout the session.
PDF Text Extraction Quality: Legal documents often have complex formatting, headers, and multi-column layouts. We iterated through multiple PDF parsing libraries before finding a combination that reliably extracts readable text while preserving document structure.
Accomplishments that we're proud of
Seamless Voice Experience: Users can have extended voice conversations without touching their keyboard. The system handles turn-taking naturally, muting the microphone during AI responses and resuming listening automatically.
Real Legal Research Integration: The AI does not fabricate case law. When it cites a case, that citation comes from a real Perplexity search with verifiable sources displayed in the citations panel.
Document Generation Pipeline: Users can request legal documents during conversation and receive downloadable PDFs. The AI generates the content, formats it appropriately for the document type, and provides a download link in the citations panel.
Adaptive Persona System: The opposing counsel persona genuinely challenges arguments. It searches for counter-precedents, identifies logical weaknesses, and maintains adversarial pressure without breaking character.
Production-Ready Architecture: The application deploys to Vercel with proper session isolation, document persistence through Vercel KV, and streaming responses that work reliably in production environments.
What we learned
Voice UX Requires Different Design: Text interfaces can show loading states and partial responses easily. Voice interfaces need careful silence management, clear turn-taking signals, and responses optimized for listening rather than reading.
LLM Tool Use Needs Guardrails: Without explicit instructions to actually call tools, the model sometimes "pretends" to have read documents or searched for cases. We learned to be very direct in system prompts about when and how to use each tool.
Streaming Complexity Compounds: Each additional stream type (text, audio, citations, tool calls) multiplies the edge cases. We gained appreciation for robust SSE parsing and state machine design.
Legal Domain Has Unique Requirements: Legal professionals expect precise citations, formal document formatting, and role-appropriate language. Generic AI assistant patterns needed significant adaptation for this domain.
What's next for Moot
Expanded Document Types: Support for analyzing contracts, depositions, and case files with structured extraction of key clauses, dates, and party information.
Session Recording and Review: Record practice sessions for later playback with AI-generated feedback on argument structure, citation usage, and delivery.
Multi-Party Simulations: Enable scenarios with multiple AI participants, such as direct examination with both judge interjections and opposing counsel objections.
Performance Analytics: Track improvement over time with metrics on argument coherence, citation accuracy, and response to challenges.
Mobile Application: Native iOS and Android apps optimized for voice-first interaction during commutes or away from desktop.
Integration with Legal Research Platforms: Connect with Westlaw, LexisNexis, and court databases for authoritative case law access.

Log in or sign up for Devpost to join the conversation.