-
-
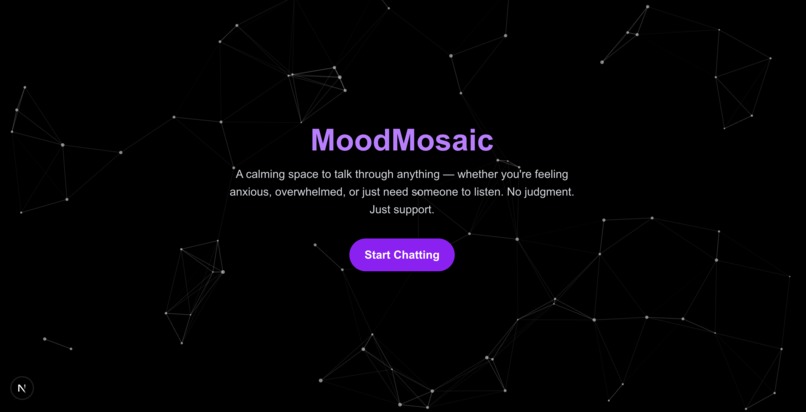
homepage
-
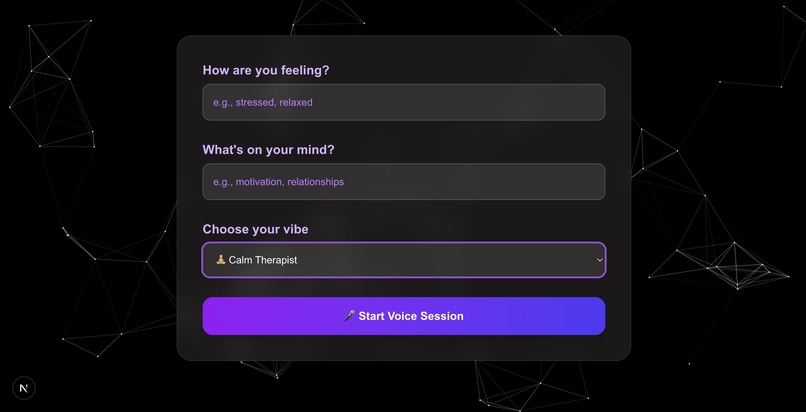
-


🧠 MoodMosaic — Your AI-Powered Emotional Companion
🚀 Inspiration
In a world where mental health is often overlooked, we wanted to create a space where individuals can freely express their feelings, be truly heard, and receive personalized, real-time emotional support. With MoodMosaic, we aim to bridge the gap between human empathy and cutting-edge AI, providing a platform where people can connect on a deeper, emotional level with a truly attentive AI companion.
Our vision was to bring the comforting feeling of speaking to someone who genuinely listens, combined with the speed, adaptability, and endless potential of AI.
🛠️ How We Built It
To bring this ambitious vision to life, we carefully selected a powerful and cutting-edge tech stack, leveraging some of the most innovative tools available in the industry to ensure a seamless and responsive experience for users. Here's an in-depth breakdown of the technologies we used to build MoodMosaic:
Frontend: Next.js & TypeScript
We chose Next.js for its speed, scalability, and flexibility, which is essential for a real-time application like MoodMosaic. Next.js’s server-side rendering (SSR) capabilities allowed us to ensure that the app loaded quickly and efficiently, providing instant access to users with minimal lag. It also supports static site generation (SSG), which boosts performance even further by pre-rendering certain pages at build time.
TypeScript was employed to provide type safety and improve the development process. By integrating TypeScript, we ensured that potential bugs were caught early in the development cycle, leading to cleaner, more maintainable code. It allowed us to scale the application with confidence, ensuring that as new features were added, there was strong typing and documentation to guide the process. Additionally, the integration of Next.js with TypeScript enabled us to write concise, type-safe code for complex interactions, particularly when handling dynamic user inputs and real-time responses.
Voice Interaction: Vapi
For seamless real-time voice interactions, we chose Vapi, a state-of-the-art platform for voice-powered AI communication. Vapi allowed us to handle voice-to-text and text-to-voice functionality with exceptional precision, ensuring that our conversations with users felt both natural and responsive.
What set Vapi apart was its real-time voice capabilities. We used Vapi to stream voice input from the user and deliver output from the AI in real-time. This dynamic interaction is powered by Vapi’s low-latency, high-performance infrastructure, which minimizes the delay between user speech and AI response. The system allows for continuous dialogue, enabling our AI to adapt its responses based on the ongoing emotional state of the user. Whether the user is anxious, calm, or excited, Vapi's technology ensures that their voice input is transcribed quickly and accurately, facilitating seamless communication.
Emotional Intelligence: groq llama3-70b-8192
The core of our AI's dynamic conversational intelligence is powered by groq llama3-70b-8192, an advanced language model optimized for understanding natural language and sentiment analysis. This large model is capable of processing vast amounts of data and understanding not only the words being said, but also the underlying emotional context behind them.
We integrated groq into MoodMosaic to detect user sentiment, mood shifts, and other emotional markers in real-time. For instance, if a user expresses frustration or sadness, groq can adjust the AI's tone and persona to match the emotional context, providing responses that feel empathetic and tailored. Additionally, groq's advanced understanding of natural language processing (NLP) allows for highly contextual responses, so the AI doesn’t simply generate generic answers—it knows how to respond in a way that reflects the user’s emotional state.
The use of groq has been critical in enabling us to create conversations that feel emotionally intelligent, allowing the AI to evolve its responses based on emotional cues. Whether it's detecting calmness, excitement, or anxiety, the AI continuously adapts to provide the most empathetic and appropriate responses.
Backend: Custom Voice-Routing System (Node.js)
At the heart of our system is a custom voice-routing backend, built using Node.js. This backend serves as the bridge between the user’s voice input, the AI’s conversational model, and the real-time voice interaction through Vapi. We used Node.js for its non-blocking, event-driven architecture, which is perfect for handling the real-time, concurrent processes involved in voice communication.
The backend’s primary responsibility is to route user input to the correct AI persona based on the emotional context of the conversation. It listens to the AI’s detected emotional state, adjusts the voice persona dynamically (e.g., switching from a calm therapist persona to an energetic coach), and ensures that the conversation flows without interruption. This is achieved by creating custom voice-routing algorithms that respond to the user's emotional shifts, detected either through text-based sentiment analysis or voice tone analysis from Vapi.
Integrating Persona-Based Voice Synthesis
One of the standout features of MoodMosaic is its persona-based voice synthesis. By dynamically switching the AI's persona (calm, energetic, nurturing, etc.), we are able to create deeply personalized conversations that evolve with the user’s emotional state.
When the AI detects that a user’s mood has shifted—for example, they become more anxious or agitated—the backend triggers a change in the AI’s voice persona to reflect this shift. This adjustment isn't just about changing the tone of the voice—it’s about adjusting the mannerisms, speech cadence, and word choice of the AI to match the emotional context. This feature is powered by a combination of groq’s emotional detection model and our custom voice-routing system, which helps maintain a smooth, intuitive conversational flow even as the persona of the AI adapts in real time.
Real-Time Data Flow and Emotional Adaptation
One of the biggest challenges in building this system was managing the real-time data flow between the components. As soon as a user speaks, the following sequence occurs:
- Vapi transcribes the voice input into text.
- The Node.js backend routes this input to groq llama3-70b-8192 to analyze the emotional tone.
- Based on the detected emotion, groq adjusts the AI’s response and Node.js routes the voice output to Vapi to synthesize and deliver a tailored response back to the user.
This fluid, continuous feedback loop ensures that the system not only feels immediate and responsive but also emotionally adaptive. Users can experience conversations where the AI feels attuned to their emotions, providing a supportive, empathetic response each time they speak.
Sentiment Detection with Claude
At the heart of MoodMosaic’s emotional intelligence is Claude, which we use for advanced sentiment detection. When a user speaks, Vapi transcribes their voice to text, which is then analyzed by Claude to determine the emotional tone of the conversation.
Claude’s ability to assess the sentiment behind the user’s words allows the AI to adjust its responses accordingly. For example:
- If Claude detects anxiety or sadness, the AI responds with a calm, supportive tone to help soothe the user.
- If the sentiment is positive or excited, the AI adopts a more energetic and motivational persona.
This real-time sentiment detection allows the AI to dynamically shift its tone, voice, and responses, ensuring the interaction always feels emotionally in-tune with the user’s needs. By using Claude, MoodMosaic can engage in more personalized and emotionally resonant conversations, making the AI feel like a true companion.
💡 What We Learned
Building Voice-First Interfaces is Complex: Transitioning from text-based AI systems to voice-first systems presents a whole new set of challenges. We quickly realized that latency and real-time feedback loops are critical in delivering a seamless user experience. Even slight delays can disrupt the flow of conversation, making it feel less natural. Synchronizing speech recognition, AI processing, and voice synthesis in real time was more complicated than we initially anticipated. This experience highlighted the importance of optimizing all stages of the conversation for speed and smoothness. Sentiment Detection is Not Just About Words: While sentiment analysis has traditionally focused on text-based indicators like word choice and structure, mood detection through voice adds a layer of complexity. We learned that emotions in speech aren’t just about what’s being said but how it's said — tone, pitch, pace, and pauses all play a significant role. Using Claude to determine emotional states based on vocal cues enabled us to better align the AI's responses with the user’s emotional needs, but it also required continuous refinement of our models to ensure accuracy. Persona Management is a Balancing Act: Creating a coherent, dynamic personality for the AI agent while keeping conversations fluid and engaging required constant adjustments. We had to manage persona consistency while ensuring that the AI could adapt its tone and identity in real time, based on user input and emotional shifts. This involved a delicate balance between the AI's core characteristics (calm, energetic, etc.) and the context-sensitive adjustments needed to convey empathy and understanding effectively. Emotional Engagement Takes Creativity: Designing an AI that feels emotionally connected to the user involves more than just understanding words or sentiment — it's about crafting responses that feel genuine and empathetic. We learned that prompt engineering plays a huge role in achieving this. Fine-tuning prompts to ensure that the AI responds with the right level of warmth, attentiveness, and understanding was a surprisingly intricate task. We also explored different ways to manipulate tone and voice characteristics to ensure that our AI could speak with an emotionally resonant voice, depending on the mood of the conversation. Real-Time Interaction Can Be Mentally Exhausting: As we built the system, we realized that keeping up with real-time interaction can be mentally taxing for users. The AI needed to provide instant feedback, but also leave space for the user to process and reflect. We learned that balancing speaking speed, pauses, and emotional tone is crucial in creating a conversational experience that feels like a natural dialogue rather than an interrogation. It's all about giving users the emotional space they need to engage deeply. User Expectations Are High, But Flexible: As we iterated on the design and functionality of MoodMosaic, we found that user expectations around AI empathy were higher than anticipated. People expect more than just functional responses — they want to feel like they’re talking to a real person who understands them. This challenge led us to experiment with various levels of emotion detection and tone variation, and we learned that users are often willing to be forgiving of mistakes, as long as the AI can reflect their emotions and stay present with them. AI is a Tool, Not a Replacement: One key takeaway was that no matter how advanced the AI, it can never fully replace the human element. While MoodMosaic provides valuable emotional support and can guide users through difficult moments, it’s ultimately a supplementary tool — not a substitute for real human interaction. We learned that there’s a delicate line between providing support and knowing when to direct users to professional help or human-centered solutions. This insight will drive our future enhancements to ensure that the AI never oversteps its role.
🧱 Challenges
Building MoodMosaic presented several unique challenges that pushed us to innovate and problem-solve in creative ways. Here are some of the key obstacles we encountered:
Vocal Latency: Ensuring seamless real-time interaction between voice input, sentiment detection, and AI response was a significant challenge. Even small delays in transcription or voice synthesis could disrupt the flow of conversation. We had to optimize each step—voice-to-text, LLM processing, and voice synthesis—to ensure smooth, low-latency communication.
Emotional Tone Alignment: We faced difficulties aligning the AI’s tone with the detected emotions. Even with Claude providing sentiment analysis, ensuring the AI's voice and responses reflected the correct emotional context was challenging. Fine-tuning the prompts and voice synthesis to match different emotional states was an ongoing iterative process.
User Experience Design: Designing an interface that is intuitive while supporting complex voice interactions and real-time emotional adjustments was no easy feat. The goal was to create a seamless user journey where the AI feels genuinely empathetic and responsive, which required constant feedback and fine-tuning.
Despite these challenges, the process of overcoming them has led to the creation of a truly innovative product. With every obstacle, we learned and improved, ultimately resulting in a more polished, user-centered experience that we're proud to share with the world.
🎯 What’s Next?
As we continue to evolve MoodMosaic, we have exciting plans to further enhance the user experience:
Voice Customization: We aim to allow users to input any voice and curate it into a specific persona. For example, users could choose a voice that resembles their mom to offer motivational support or create any other voice profile they prefer. This personalized experience will make the AI feel even more familiar and emotionally connected to the user. Memory Tracking: We plan to integrate a memory tracking system, where the AI can remember details from each session and use that information to better understand and support the user over time. This will help monitor the user’s emotional well-being, track progress, and provide contextual support during each session, creating a more personalized and insightful experience. Mental Health Insights: We are also working on a mental health dashboard that provides users with AI-generated insights into their emotional health based on ongoing interactions. This dashboard will offer trends, patterns, and suggestions to help users track their mental well-being and improve their emotional resilience.
These features will deepen the user experience, making MoodMosaic not just a conversational AI but a comprehensive emotional health companion that adapts and grows with you.
🫂 Final Thoughts
MoodMosaic is more than a voice bot — it’s a small step toward emotionally intelligent machines that care.
Built With
- claude
- groq
- javascript
- lmnt
- next.js
- node.js
- react
- typescript
- vapi






Log in or sign up for Devpost to join the conversation.