Here is the story of our project, Moodify.
What Inspired Us
Our project began with a simple, well-known fact: music has a powerful influence on human emotion. We looked at the current landscape of music apps and saw a major "personalization gap". Most platforms rely on you to manually pick a playlist or tell them how you're feeling. We wanted to build something smarter.
Our inspiration was to create an intelligent system that could recognize a user's mood in real-time and automatically play music that aligns with that emotion, all without requiring any significant user effort. We wanted to build the "beat that matches your feel".
How We Built It
We designed Moodify as a full-stack web application with a specialized, dual-backend architecture to handle the different tasks.
Frontend: The user interface is a clean, responsive site built with React.js and styled with Tailwind CSS. This is what the user sees and interacts with, whether they're uploading a video or answering questions.
Backend (The "Brains"): We split our backend into two microservices:
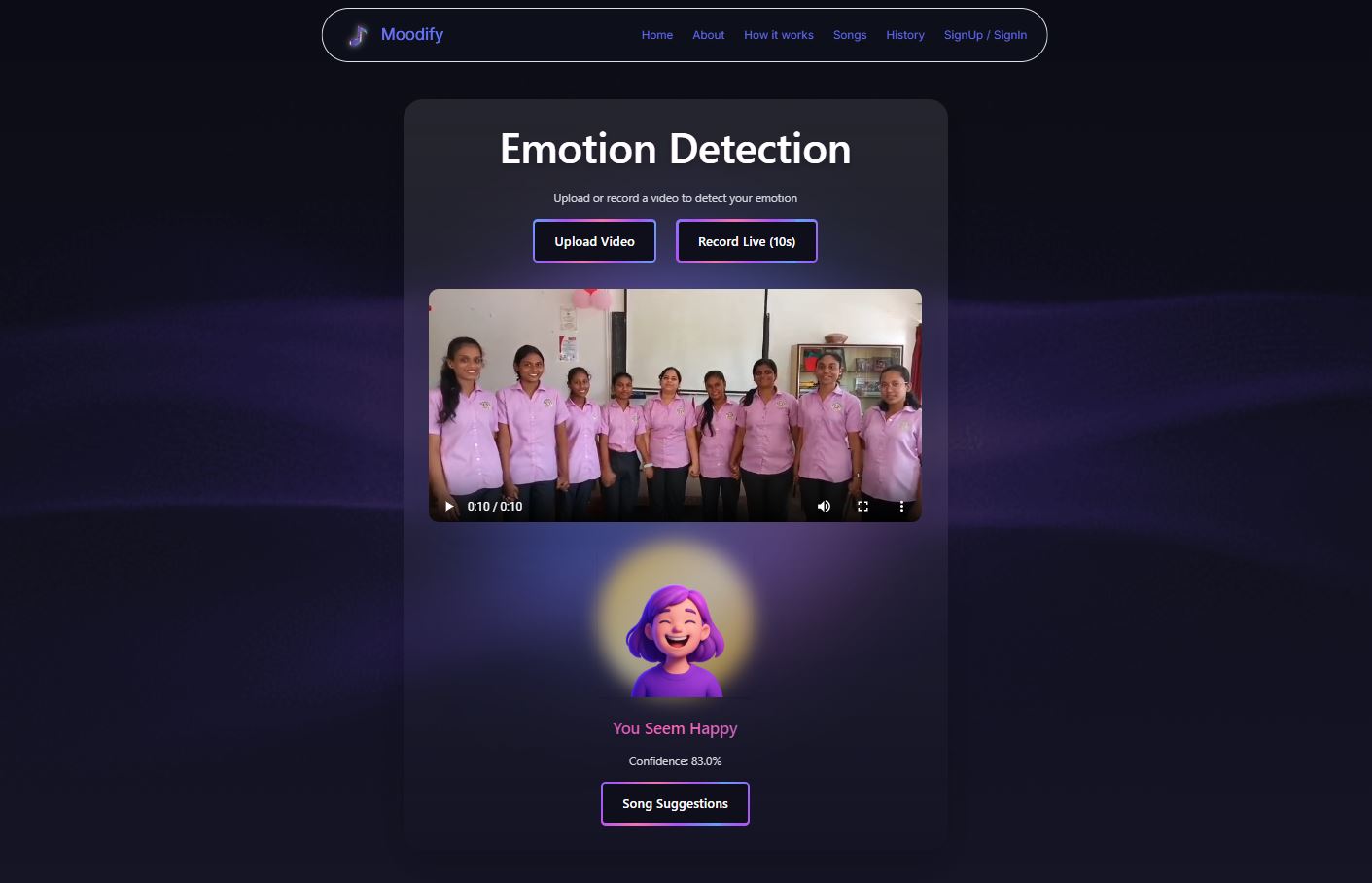
- Flask (Python): This service is our AI powerhouse. It handles all the machine learning tasks. When a user provides a video, this backend uses OpenCV to extract frames, a DNN model to detect a face, and the DeepFace library to analyze the facial expression. For text input, it uses a DistilRoBERTa model to perform mood inference.
- Express.js (Node.js): This service manages everything else. It handles user authentication (signup/signin), manages user sessions, and provides the REST APIs for our database.
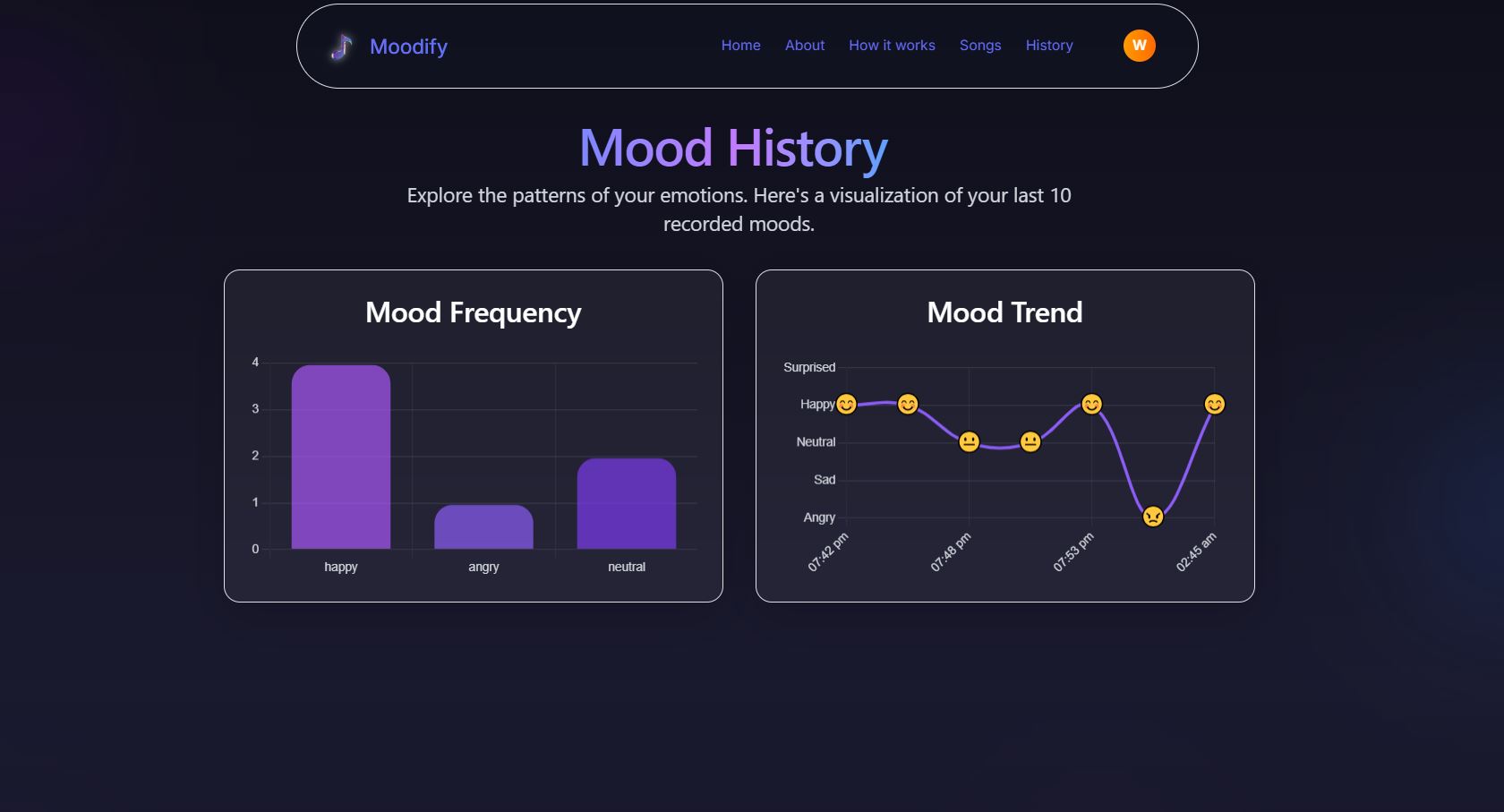
Database: We used MongoDB Atlas as our cloud database. It stores user account information (with securely hashed passwords), the song library (categorized by emotion), and every user's mood history to power our analytics dashboard.
When a user provides input (video or text), the React frontend sends it to the Flask backend. Flask analyzes it, determines the dominant emotion, and then fetches a matching playlist from our MongoDB database. This JSON response—containing the emotion, confidence score, and song list—is sent back to the frontend for the user to see and hear.
Challenges We Ran Into
Building an "emotionally intelligent" app was not easy. Our biggest challenges were with the reliability of the AI models.
Subtle Expressions: We found that the model struggled to differentiate between nuanced emotions, especially anger and sadness, which can have similar facial expressions.
- Our Solution: We stopped relying on a single frame. Instead, we analyze multiple frames from the video and use a "majority vote" or averaging system to get a much more stable and accurate prediction.
Noisy Video: The DeepFace model would get confused if there were multiple people in the video or if a face was partially covered.
- Our Solution: We implemented a filtering pipeline. We first use a DNN model to draw bounding boxes around all detected faces, then prioritize the largest or closest face to the camera. We crop this "Region of Interest" (ROI) and only pass that clean, isolated face to DeepFace for analysis.
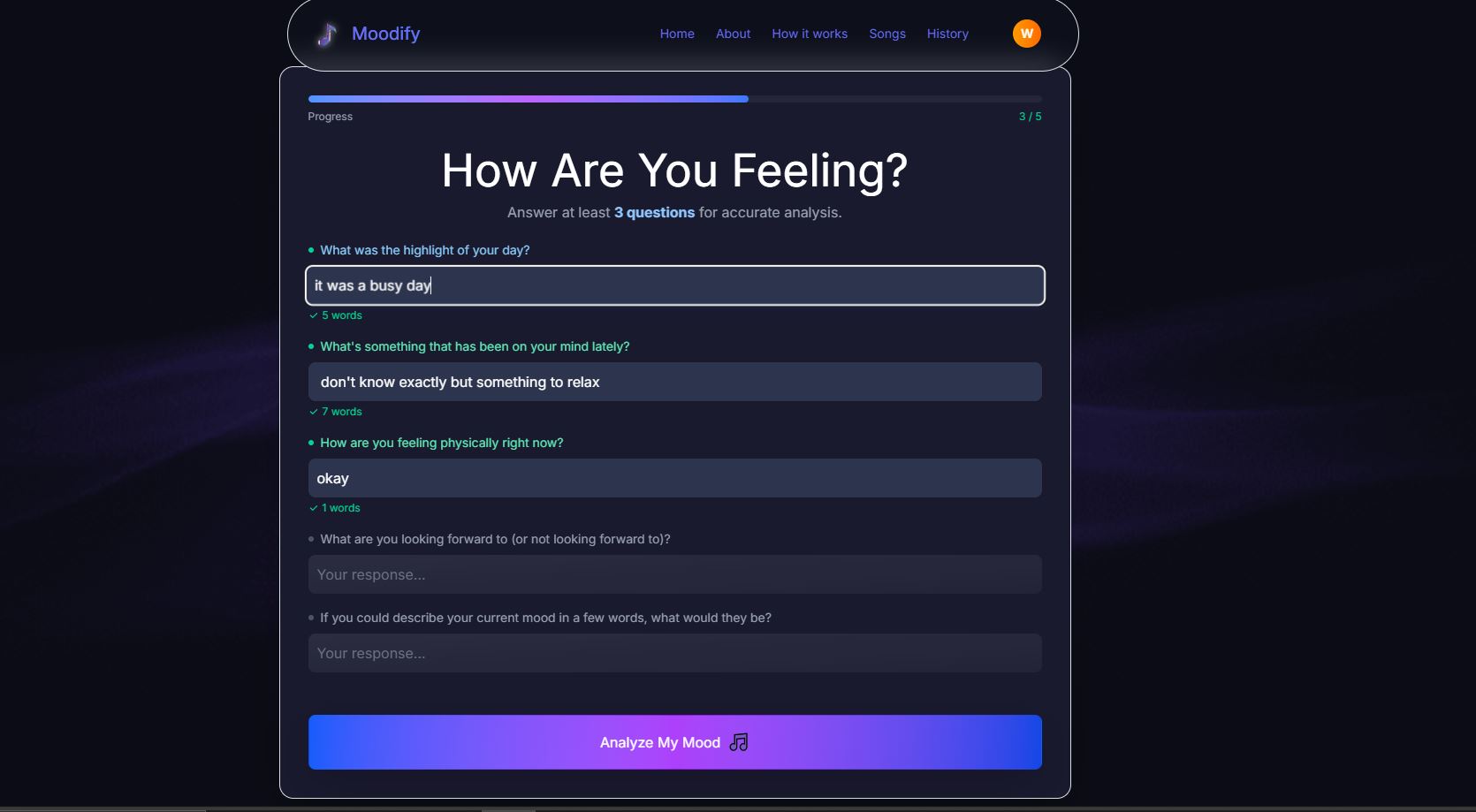
Messy Text: Users don't always type perfectly. Misspelled words and ambiguous or mixed-emotion answers in the questionnaire would confuse our DistilRoBERTa model.
- Our Solution: We added a preprocessing step for all text input. This includes spell correction and normalization. We also use a confidence threshold to ensure we only act on predictions the model is reasonably sure about.
What We Learned
This project was a massive learning experience, teaching us that a raw AI model is rarely a complete solution.
- We learned the critical importance of preprocessing and post-processing. Our solutions for frame averaging, ROI cropping, and text normalization were just as important as the models themselves.
- We learned how to design a robust, full-stack architecture. Separating the AI tasks (Flask) from the user/data management (Express.js) made our application much more stable, scalable, and easier to debug.
- We gained practical experience with real-world data. We learned to anticipate messy inputs—whether it's a poorly lit video or a typo-filled text response—and to build a resilient system that can handle it gracefully.

Log in or sign up for Devpost to join the conversation.