Inspiration
Over the years we realized that AI should work in the direction of detecting human emotion and help the person in their terms. If we take an instance of a lonely man staying away from the family during these pandemic times he sure misses them, so the system should act as his support system by enhancing his mood by playing some light music or motivating music. So the detection of human emotion can be observed clearly from his expression or his voice. So we have been working on a project which has the ability to detect one's facial expression and predict the emotion from your camera or if you want to use voice assistance to describe how u r feeling then our intelligent software will play a whole bunch of playlist what u need at the particular moment. If someone is way too worried or distracted up to the extent that he is unable to sleep then our 'Mood Wick' will play those soothing tunes that let him relax and hit the bed peacefully.
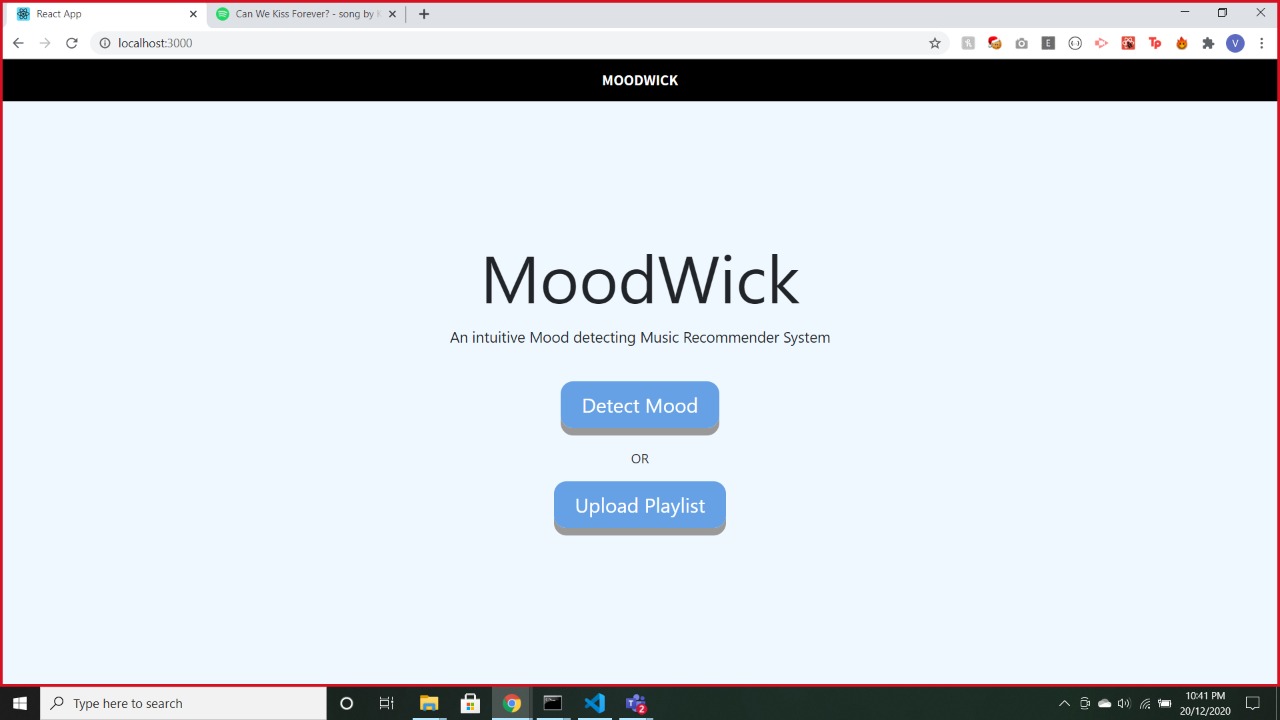
What it does
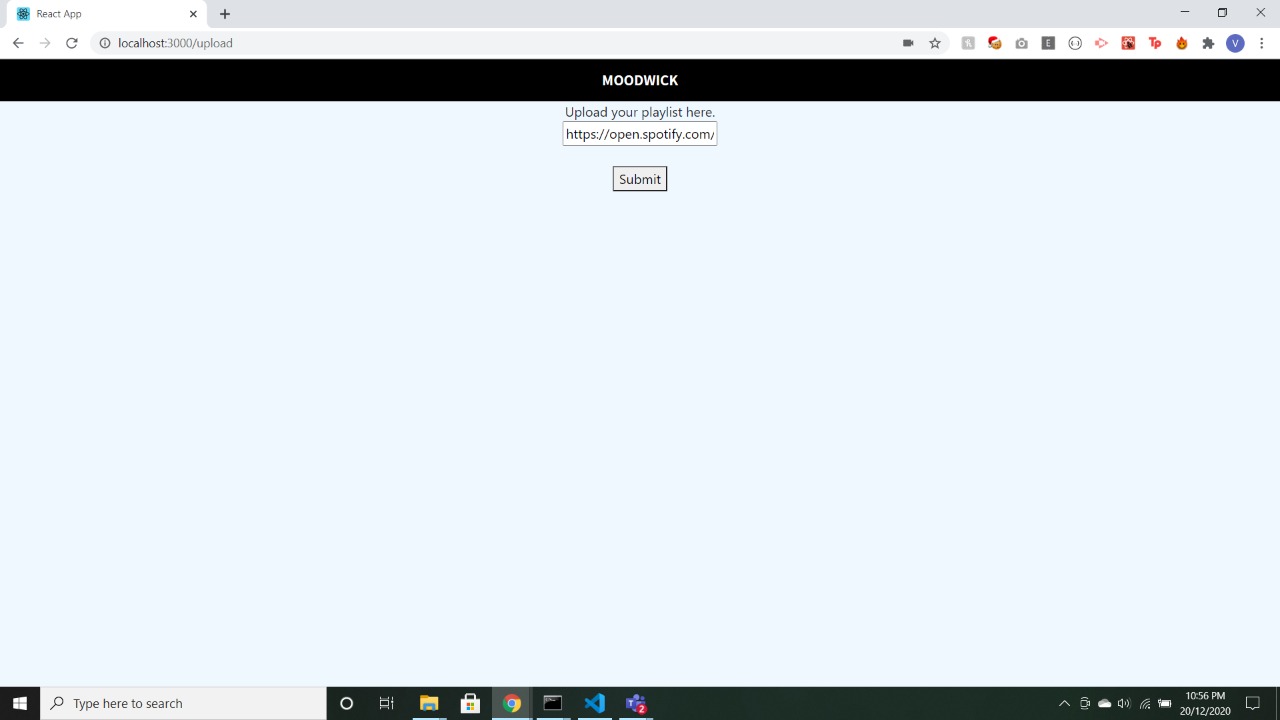
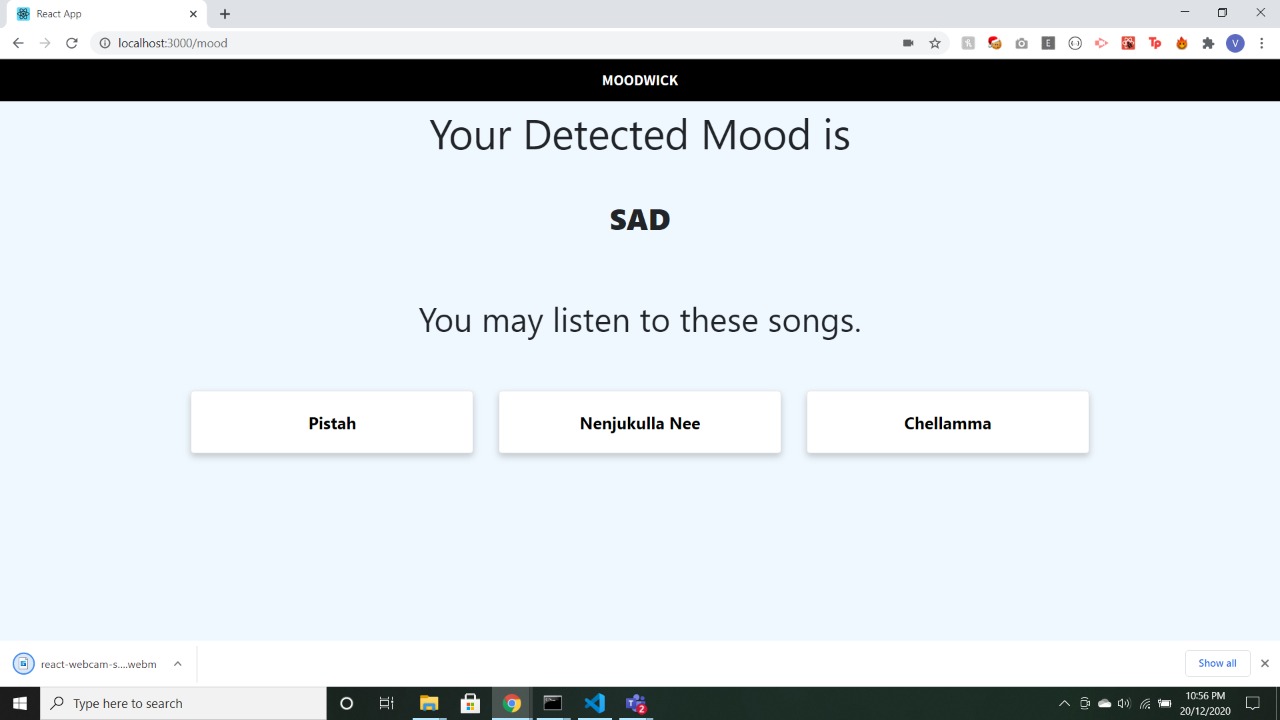
It's not just about feeling low, it is about the current mood which you experience, whether you want to celebrate any occasion or enjoy the calmness of sea/nature or you are missing someone. Have your music basket ready, with our Mood Wick which can predict not just 1 or 2 but 7 emotions, so that it can perfectly match your mood by creating a joyful ambiance needed at that moment. If you have your own playlist ready on Spotify which can ravish your feelings up then you can upload the URL of your playlist and our software will be able to play the music which you need at that moment. It will discrete your songs into 7 categories. The 7 emotions being: Angry, Disgust, Fear, Happy, Neutral, Sad, Surprise.
How I built it
So we started by creating a website for Mood Wick, for this, we made the front-end with the help of web technologies such as HTML, CSS, and JS. This website has been designed to give the user an option to either open voice assistance or the camera. We used the harcasscade classifier and fonts for our project. (a) We created a dataset of the playlist to detect which of the 7 emotions it falls into. For the same, we referred to the Spotify developer website from where we can get to know the detailed components which make a song different from the others these categories being danceability, liveness, energy, tempo, valance, instrumentals, acoustics, speechiness, loudness. We used all this to cluster the playlist. The main objective of this was to create a model that can predict any song and make it fall accurately into 1 of these 7 categories. (b) Our most important aspect was to read the live video and make it capable enough to detect one's facial expression and thereby his current ongoing emotion. So for that, we used a dataset of images from Kaggle which has values for each image in the form of pixels. Dataset: https://www.kaggle.com/chiragsoni/ferdata So the excel sheet had 35887 entries of images out of which we used 28,709 images for training, and 7,178 for testing purposes. Thereby resulting in an 80: 20 ratio for training to testing. We used TensorFlow, Keras module, Numpy, pandas, and neural network layers like Max Pooling, Zero Padding, Relu. After 100 epochs our training set accuracy of 78%, also with a testing Set accuracy resulted in 63%. So this model has the pretty much-enhanced capability to detect the live emotion from the video by converting it into frames and thereby treating it as an image, for which we used OpenCV. (c) We created a voice assistant program to read our voice and convert it to text. So the voice assistant system will ask for your mood and we are also trying to make it more user friendly and interactive so that it can give its feedback and you can suggest it which type of song you want to listen to or how are you feeling now and it will use (a) model to predict which song suits best for his mood. If his mood is dull and on the negative side or he is frustrated then it will try to try to change his mood and make him forget all of his stress and problem for the time being and can rest his mind. (d) The last step of our project was to merge this into a single website and interconnect it. The website has 2 options either the voice assistance which has been integrated with © and plays the song or the option of the camera which if we go for it will use the ML model of (b) to predict the emotion and accordingly play the song using ©.
Challenges I ran into
With the time constraint, it was very difficult to train the model and also find a good dataset with a good count. So with this dataset, it took us 18hrs to train the model with 60epochs. If we would have got a better dataset with more entries our accuracy would have increased. Voice assistant made for this was facing difficulty to recognize each style of voice commands and it could understand only English. The website was a bit lagging when we started integrating it. We were facing a compatibility issue of the return type of each (a),(b),(c) part for JSON file type. Integrating JAVASCRIPT and Python code was another problem which solved after a lot of research.
Accomplishments that I'm proud of
We are glad to announce that we were able to make a good collection of the database with a variety of language options and music choices which have been categorized on 7 parameters danceability, liveness, energy, tempo, valance, instrumentals, acoustics, speechiness, loudness. It is customizable up to a great extent. We were able to integrate Java Scrip and python, along with using Json File, camera, voice input in the website. We are moving towards making Progressive Web Application and making it more user friendly and interactive. Working with Spotify API. Running a python program from JS. Last but not least to be able to build something which we just thought of and were not aware of, whether it is possible or not, and then watching it built up to a great margin considering the time constraint and our future plans which seem more strong, evident than ever before.
What I learned
Throughout this beautiful journey, we saw various ups and downs in the form of encountering any challenge/failure and thereby learning from the mistakes and by applying new techniques. The idea which we had during the planning of this project itself gave us immerse learning when we were building it step by step and to make it possible the learning the techniques which we got from our college references and various books. We learned that the most important part is to merge different projects into the 1 embodied website or in an application is another important aspect which we should keep on practicing more and more as there are various techniques of adding ML models, dataset, voice assistant feature, and to make it accessible from different devices.
What's next for Mood Wick
We will make it available offline so that people can access it from anywhere including those who are serving us at borders or glaciers and also for those who don't want to use much of their data. We will be working on making an application in which we are trying to improve our voice assistance feature so that the user can interact with it and as a person, it will be able to ask few queries, and then based on the conversation it will start playing the songs like Amazon's Alexa which will reflect your mood. We are also trying to offer more language to the same so the user can interact in one's preferred language. Our next big objective is to experiment it with a person so that we will have a dataset of an individual for various days and of various emotion after training the model on the person's voice notes. After it is implemented, we will be able to detect his emotion from his voice itself, the pitch, loudness, speed liveness, energy, tempo, valance will be the entities of the dataset. So it has a high probability to evolve as the next big thing, as it provides an option of personal customization so we can detect one's mood via their voice tone, expression, and the voice assistance makes it a great user experience. We will try to make the app cross-platform and the website more responsive with better features and proper integration with your email. We are also trying to make Mood Wick take the playlist from any mp3 format playlist thereby giving users more options if they want to share their own choice of a playlist from streaming services such as Spotify or Wynk music or Saavn etc. Thereby giving users the freedom to make their choice of language and lighten up their moods! This can be integrated with a home automation system like Alexa.
Built With
- css
- html
- javascript
- keras
- machine-learning
- node.js
- opencv
- python
- react
- tensor-flow








Log in or sign up for Devpost to join the conversation.