## Inspiration
Three real problems converge for anyone running their own Linux server:
- The expertise gap. Linux server hardening, package patching, firewall management, cron orchestration — every
team needs them, only senior engineers do them confidently. Misconfiguration is consistently the #1 root cause of breaches at this tier. - Tool fragmentation. Existing admin tools each cover one slice — state inspection, metrics, container logs,
firewall management — and they don't talk to each other. Sysadmins context-switch across half a dozen tools to do a
single job. - AI agents that talk vs. agents that act. Most "AI assistants" describe what an admin should do. Almost none
can do it safely on a real host with auditability and consent.
I wanted one console that addresses all three.
## What it does
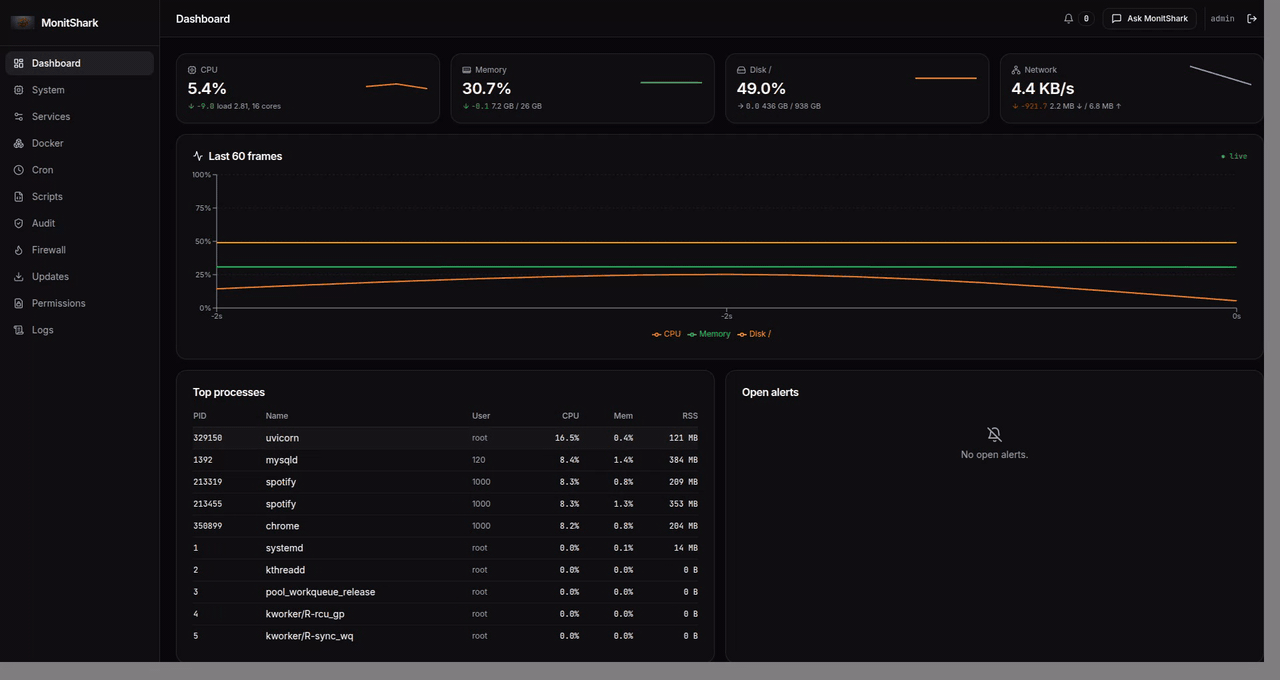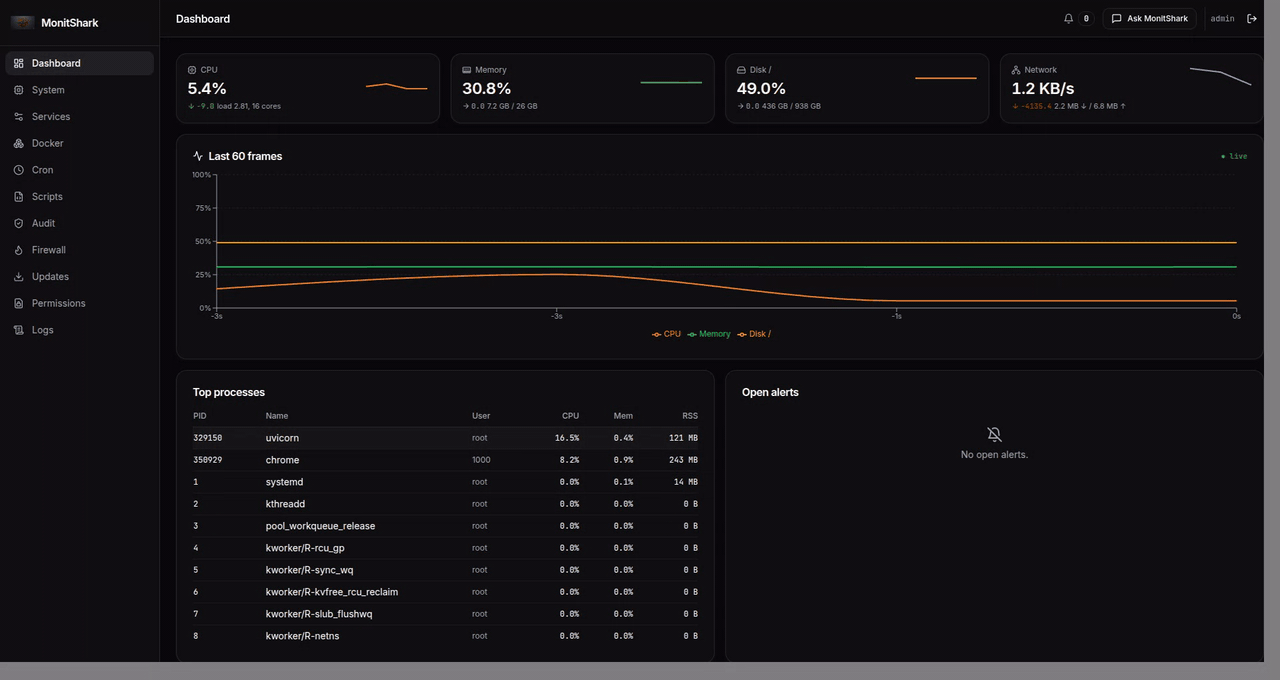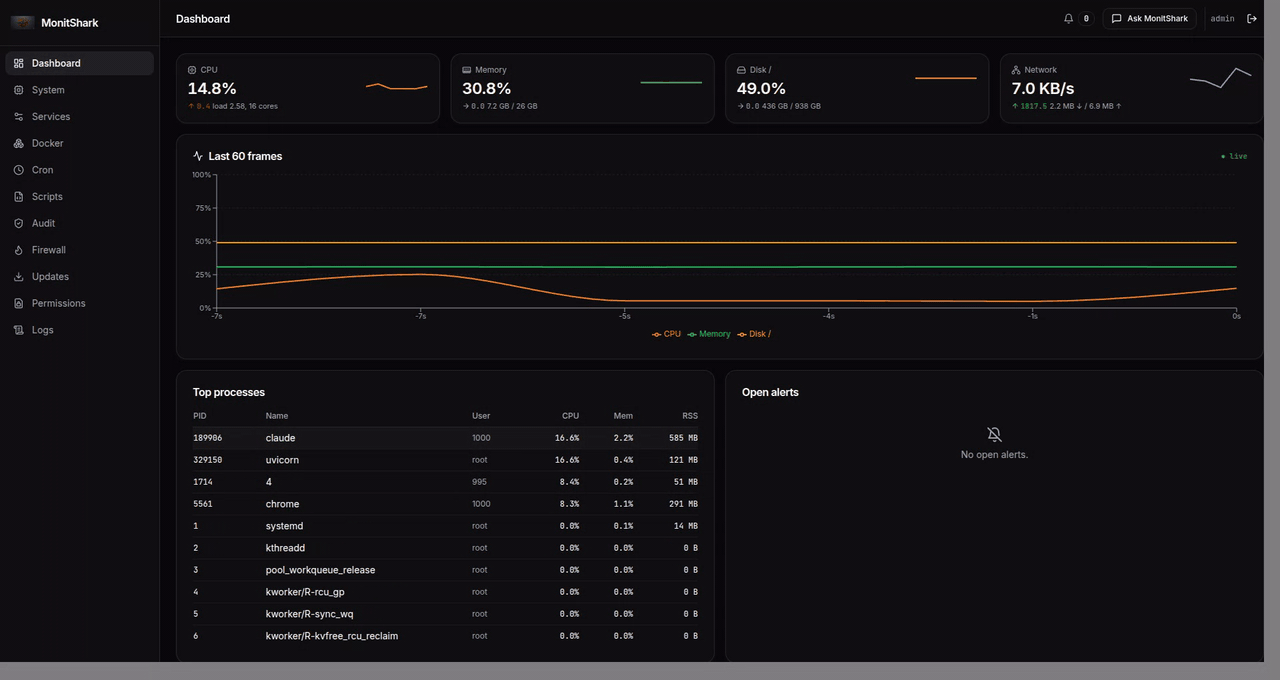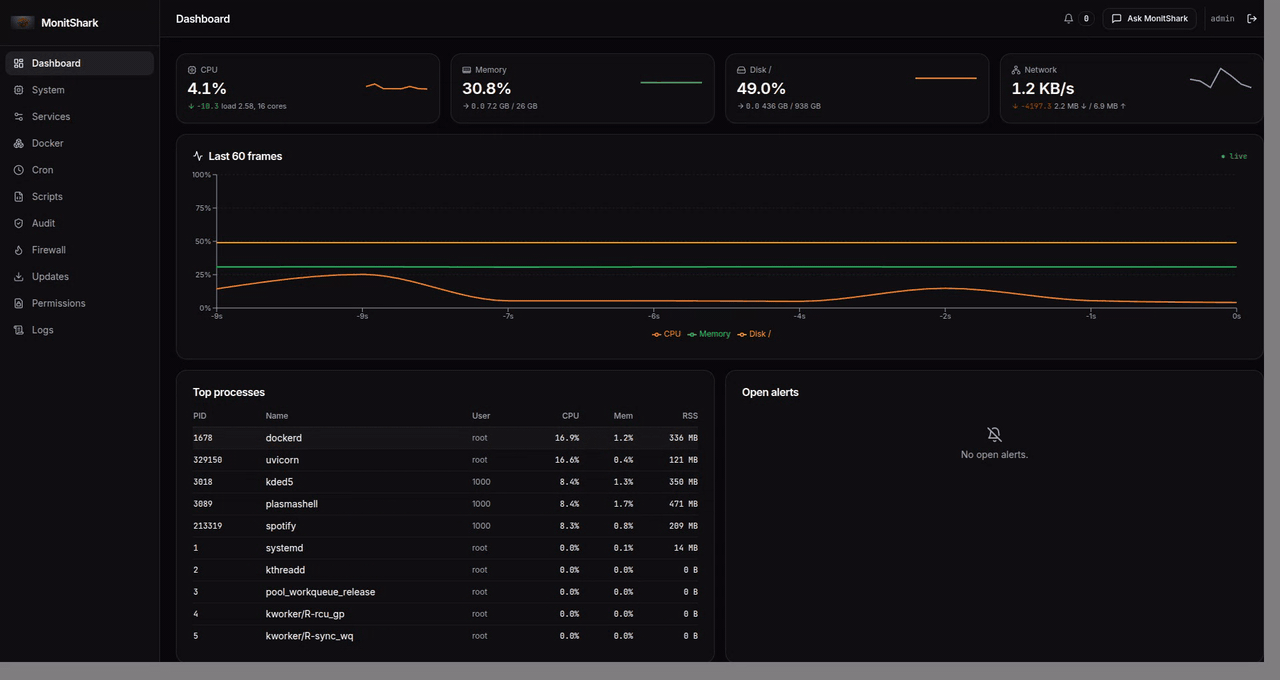
MonitShark is a self-hosted web app you run with one Docker command. It gives you:
- Live dashboard — CPU, memory, disk, network streaming over WebSockets, top processes, open alerts
- System page — per-core CPU, per-disk I/O, per-NIC throughput, sensors (temps, fans, battery), kernel modules,
listening ports with PID
- Services — every systemd unit, start / stop / restart with confirmation
- Docker — containers grouped by Compose project, live log streaming over WebSocket, lifecycle actions
- Cron — per-user tabs + system crontab, full CRUD + run-now
- Scripts — bash editor under
/opt/cockpit/scripts/, run with timeout, install as systemd service, schedule via
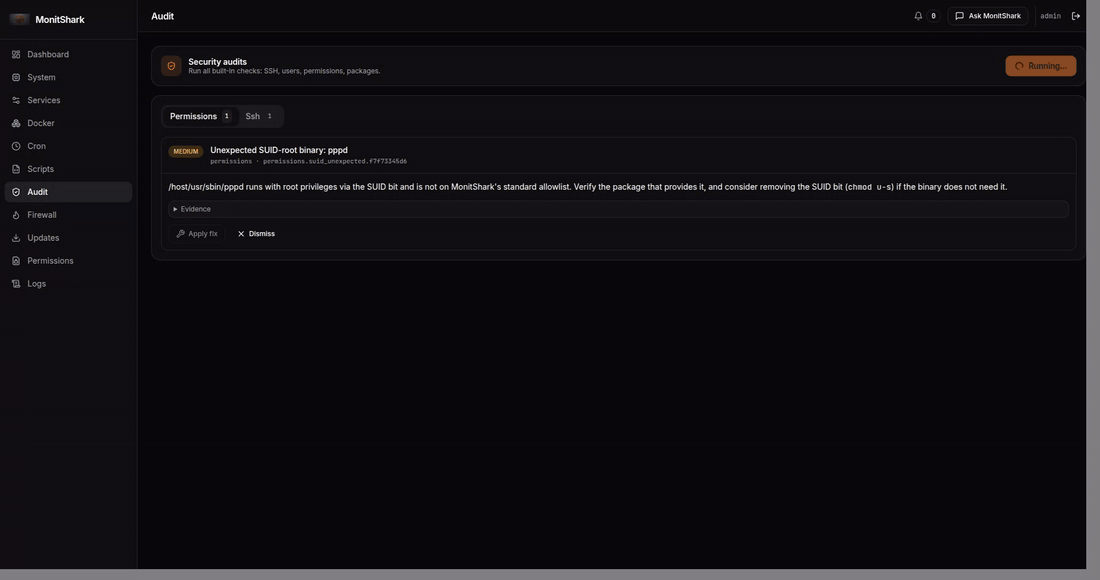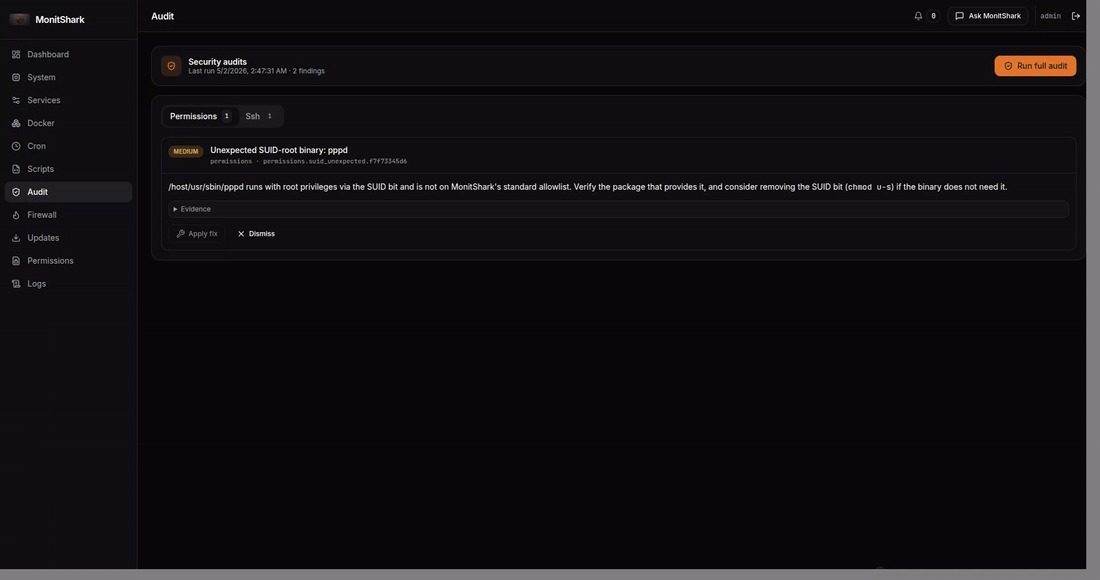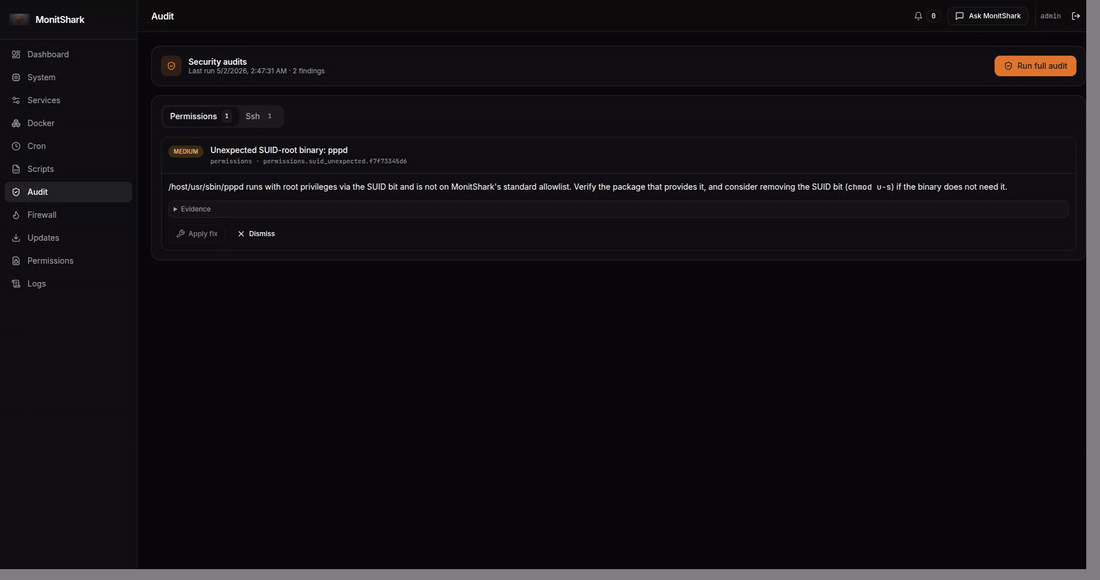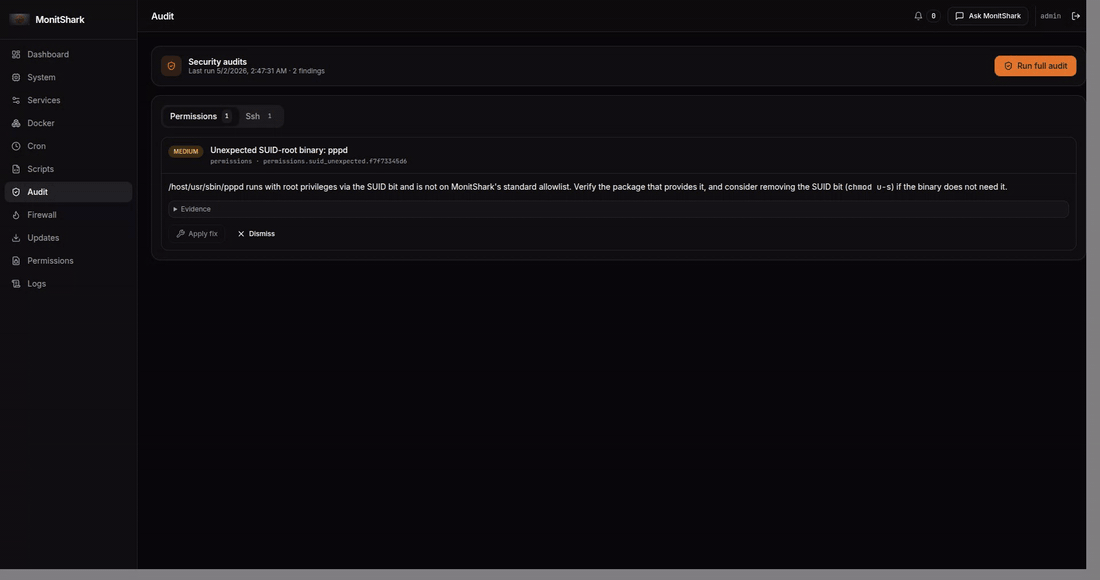
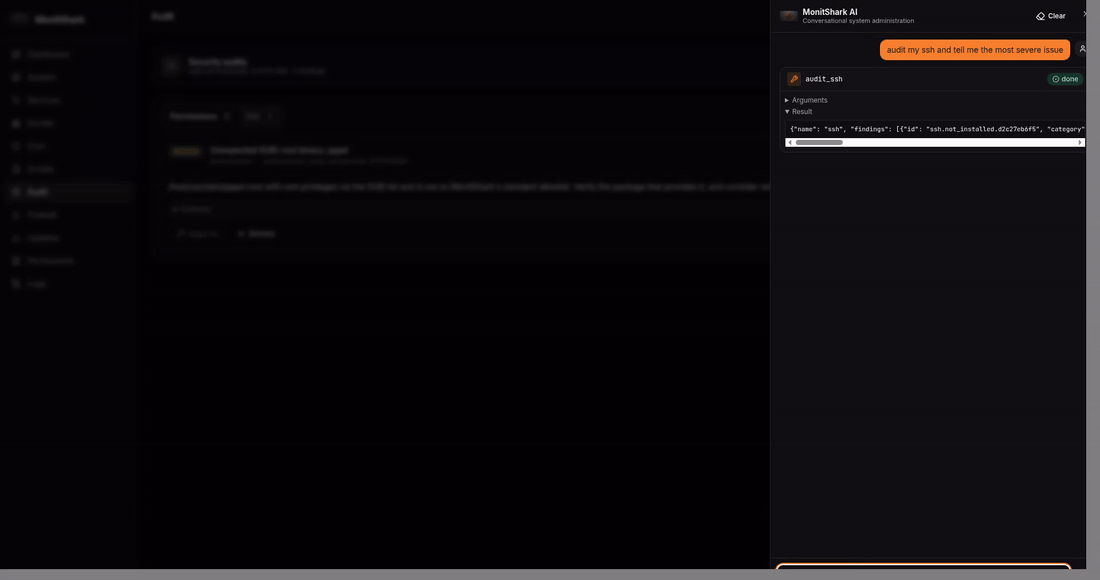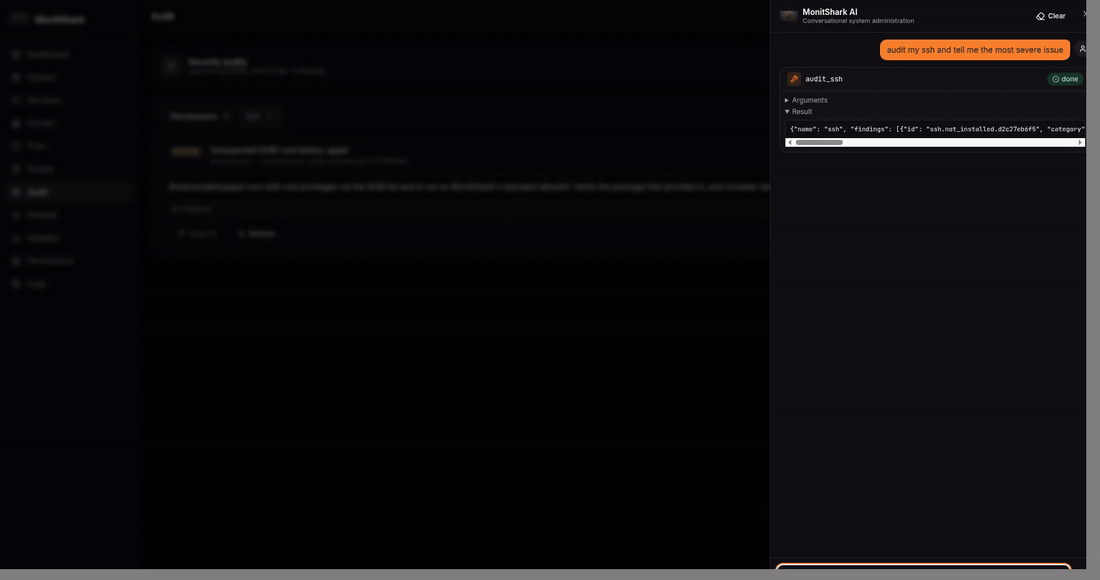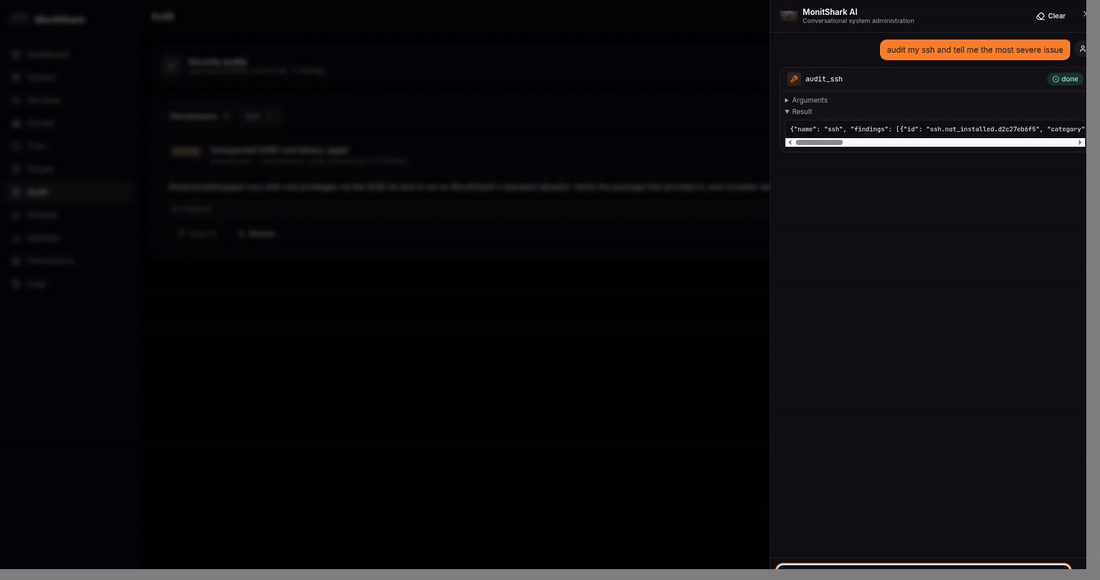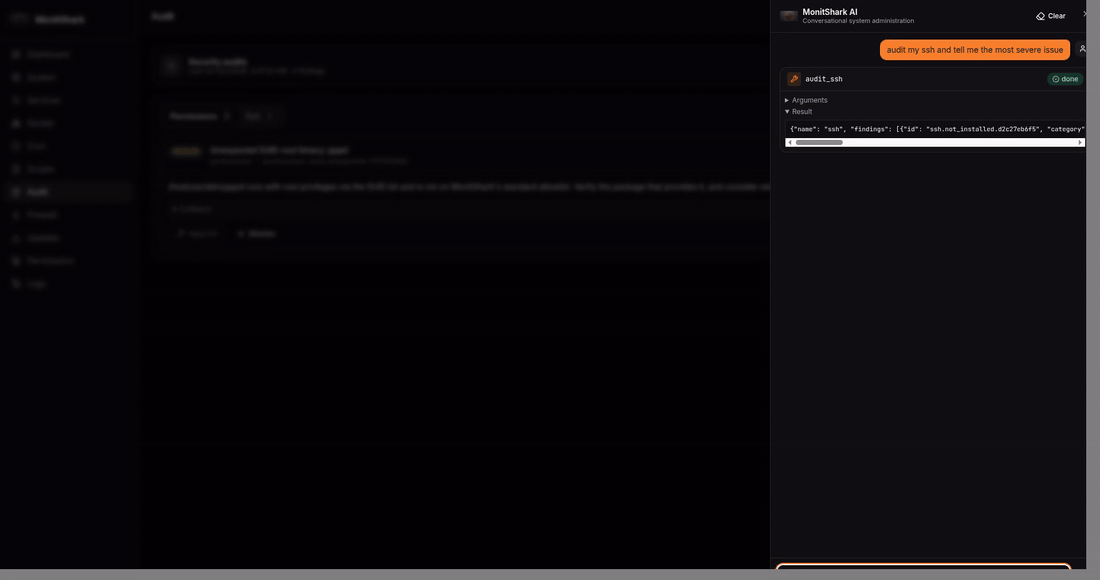
cron - Audit — 4 security audits (SSH, users, permissions, packages) with ~20 checks ranked by severity, one-click fix
- Firewall — host firewall rules: add / delete / enable / disable with action, port, protocol, source filters,
comments - Updates — distro-aware (apt/dnf), security-only updates separately
- Permissions — file browser scoped to
/etc /opt /var/log /home /root, chmod + chown - Logs — tail any file under
/var/log, regex search, "Ask the agent to analyze" handoff to chat
And the differentiator — a chat agent (Groq + LangGraph) with 51 tools, 21 of them gated by an explicit confirmation
card. The agent calls the same Python modules the REST API uses. When it wants to do something destructive, the
LangGraph state machine pauses on langgraph.types.interrupt(), surfaces a confirmation card to the React drawer, and
resumes only after the user clicks Allow. Confirmation lives in the graph topology, not in a prompt the LLM could
ignore.
## How we built it
- Backend — Python 3.11, FastAPI, uvicorn, LangGraph 0.2, langchain-groq, psutil, pystemd, python-crontab,
aiosqlite, PyJWT, passlib[bcrypt], docker SDK, distro - Frontend — React 18, Vite, TypeScript (strict), Tailwind CSS, shadcn-style primitives, TanStack Query, Recharts,
axios, react-markdown, sonner
- Reverse proxy / TLS — Caddy 2.8 with
tls internal(local CA, self-signed) - Distribution — docker-compose, single host
The backend container runs --privileged --pid=host with /:/host:rw. Mutating commands use nsenter --target 1 to
execute in the host's namespaces; reads go through the bind-mount.
Safety invariants:
- One subprocess gate (
app/util/sh.run) — a CI test fails if any other module importssubprocess - Path allowlists for log files, scripts, file browser, cron paths
- Pydantic + regex validation on every tool input before it reaches the host
- 21 destructive tools all run through the confirmation gate
- JWT auth (HS256, users.yml + bcrypt) on every REST + WebSocket endpoint
## Challenges we ran into
- LLM tool-call format quirks. Some completions emit malformed function-call syntax. Worked around with retries and a graceful fallback to a friendly user-facing error.
- Free-tier rate limits. 51 bound tools cost ~6-8k tokens per request. Switched default to
llama-3.3-70b-versatile(higher TPM ceiling) and added a 2.5s throttle between outgoing requests. - WebSocket interrupt resumption. Getting the LangGraph
interrupt()payload to surface as a React confirmation card and the user's response to resume the graph required handlingastream(stream_mode="updates")and the special
__interrupt__chunk correctly. - Self-signed cert + Docker networking. Caddy on bridge couldn't reach a backend on host networking. Moved backend
to bridge with
expose: 8000. - Bcrypt $ escaping. Compose interprets
$as variable expansion, so admin password hashes need$$doubling — documented loudly in.env.example.
## Accomplishments that we're proud of
- The confirmation gate works end-to-end — agent proposes → user clicks → host changes. Verified live on Ubuntu
24.04. - 51 tools, 11 management surfaces, 200 source files, all in one cohesive build with consistent design tokens (HSL
Tailwind variables, light/dark themes, amber accent).
- Genuine cross-distro support — apt/dnf detection, nsenter for host-namespace execution.
- Real safety architecture, not security theatre — the single subprocess gate enforced by a unit test is the kind
of invariant production codebases should have. - One-command bootstrap —
./start.shgenerates a JWT secret, createsconfig/fromconfig.example/, and brings up the entire stack.
## What we learned
- LangGraph's
interrupt()is a remarkably elegant primitive for human-in-the-loop AI. Putting consent in the graph
topology (not in a prompt or a tool wrapper) makes it un-bypassable. - Aggressive path allowlists + a single subprocess gate (with a CI test enforcing it) catches more issues than dozens
of ad-hoc validations scattered across modules. - For a chat agent over an LLM with rate limits, what you bind to
bind_tools()is a fixed token-cost overhead per request. Trimming tool docstrings is the cheapest win. - Self-hosted privileged tools shouldn't be hosted publicly even for demo — a recorded video is the right "live link"
for this category.
## What's next for MonitShark
- Comprehensive audit expansion — kernel sysctls, mount options, firewall posture, failed-login bursts, CIS
benchmark mapping - Multi-host fleet management — run a MonitShark hub that coordinates agents across N machines
- Open-ended audit mode — let the LLM plan checks dynamically rather than calling a fixed audit set
- Code-splitting the frontend bundle — current 1.2 MB JS could be halved with route-level splitting
- Custom dashboard layouts — drag-resize panels, saved views per user
Built With
- caddy
- docker
- docker-compose
- fastapi
- groq
- javascript
- langchain
- langgraph
- linux
- node.js
- playwright
- psutil
- python
- react
- recharts
- shadcn
- sqlite
- tailwindcss
- typescript
- uvicorn
- vite


Log in or sign up for Devpost to join the conversation.