-
-
Automated Source Data Verification
-
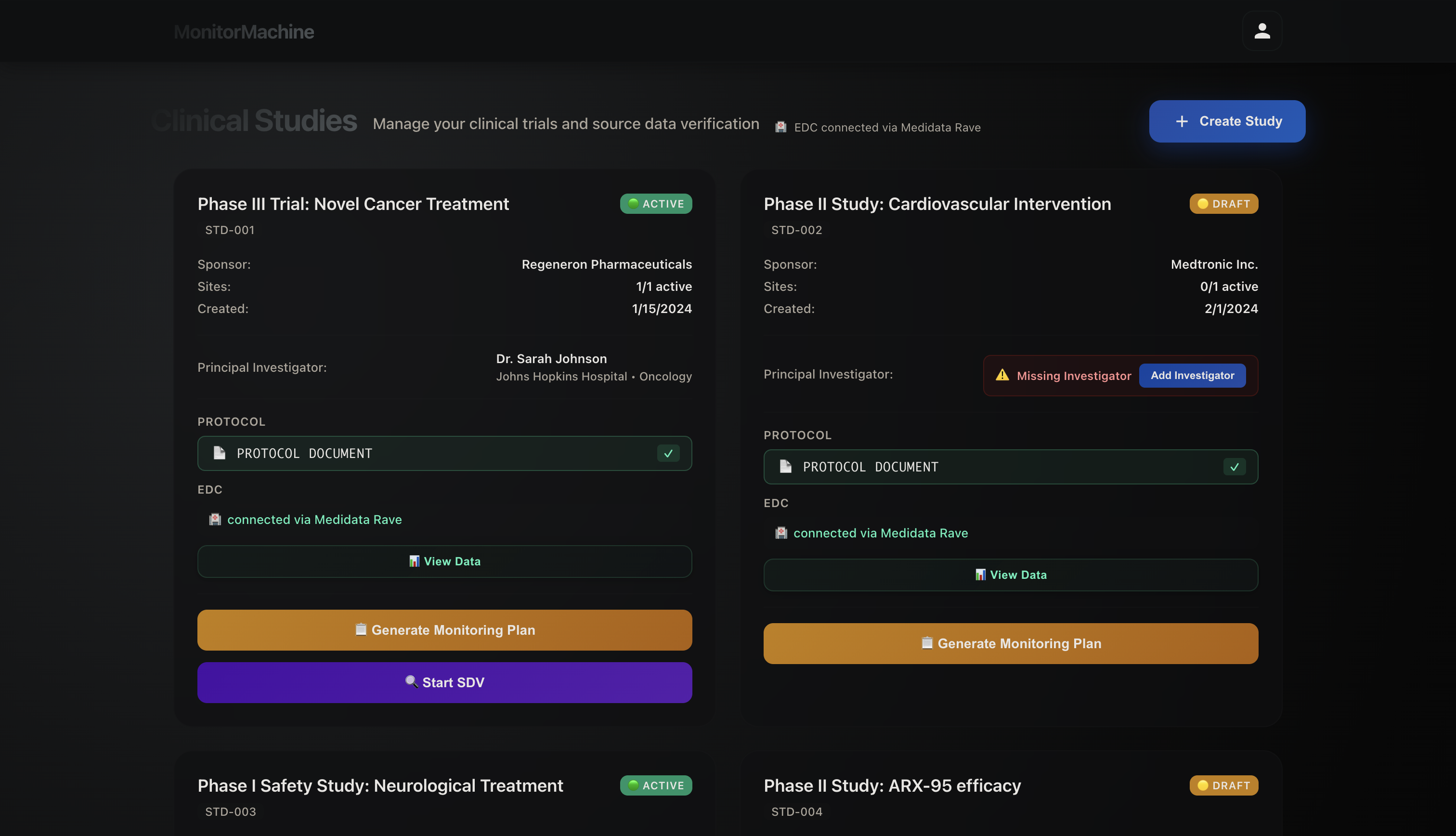
Collection of Clinical Studies
-
Login
Inspiration
Clinical trials are the bridge between scientific discovery and real-world cures -- but that bridge, currently, is slow, fragile, and expensive.
While studying how trials operate, I was struck by how much time and money go into one repetitive task: verifying and reviewing data by hand. Monitors spend weeks cross-checking PDFs, lab reports, and CRFs. It a process that consumes up to 30% of a trial’s cost and delays life-saving medicines from reaching patients.
I wanted to change that.
My inspiration was simple: what if an AI agent could handle this repetitive verification work -- allowing researchers to focus on science, safety, and innovation instead?
By automating Source Data Verification and Review, I aim to help trials move faster, cut costs, save more lives, and invite more innovation into the clinical space -- so that life-saving treatments reach people sooner.
What it does
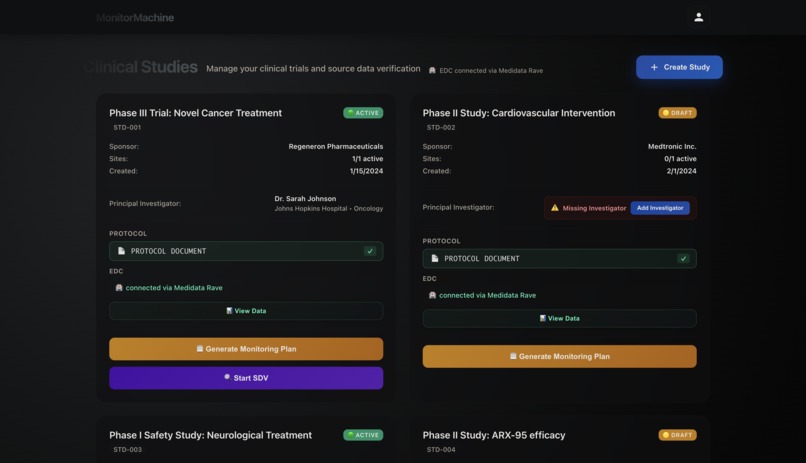
This platform automates and simplifies clinical trial monitoring by connecting directly to the technologies already used in research — such as Veeva Vault, Medidata Rave, and EHR/EDC systems — eliminating the need to copy or migrate data across tools.
It includes a Protocol Analyzer, powered by Fetch.ai and Gemini, which reads the clinical trial protocol and automatically generates a Monitoring Plan based on the study’s endpoints, schedule of activities, and key compliance requirements.
Once attached to a study, this plan enables autonomous monitoring by AI agents that follow the defined schedule, retrieve data, and execute tasks automatically.
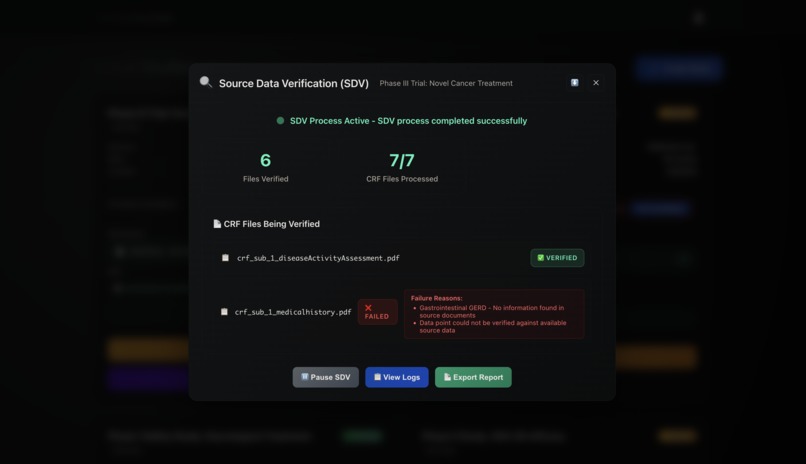
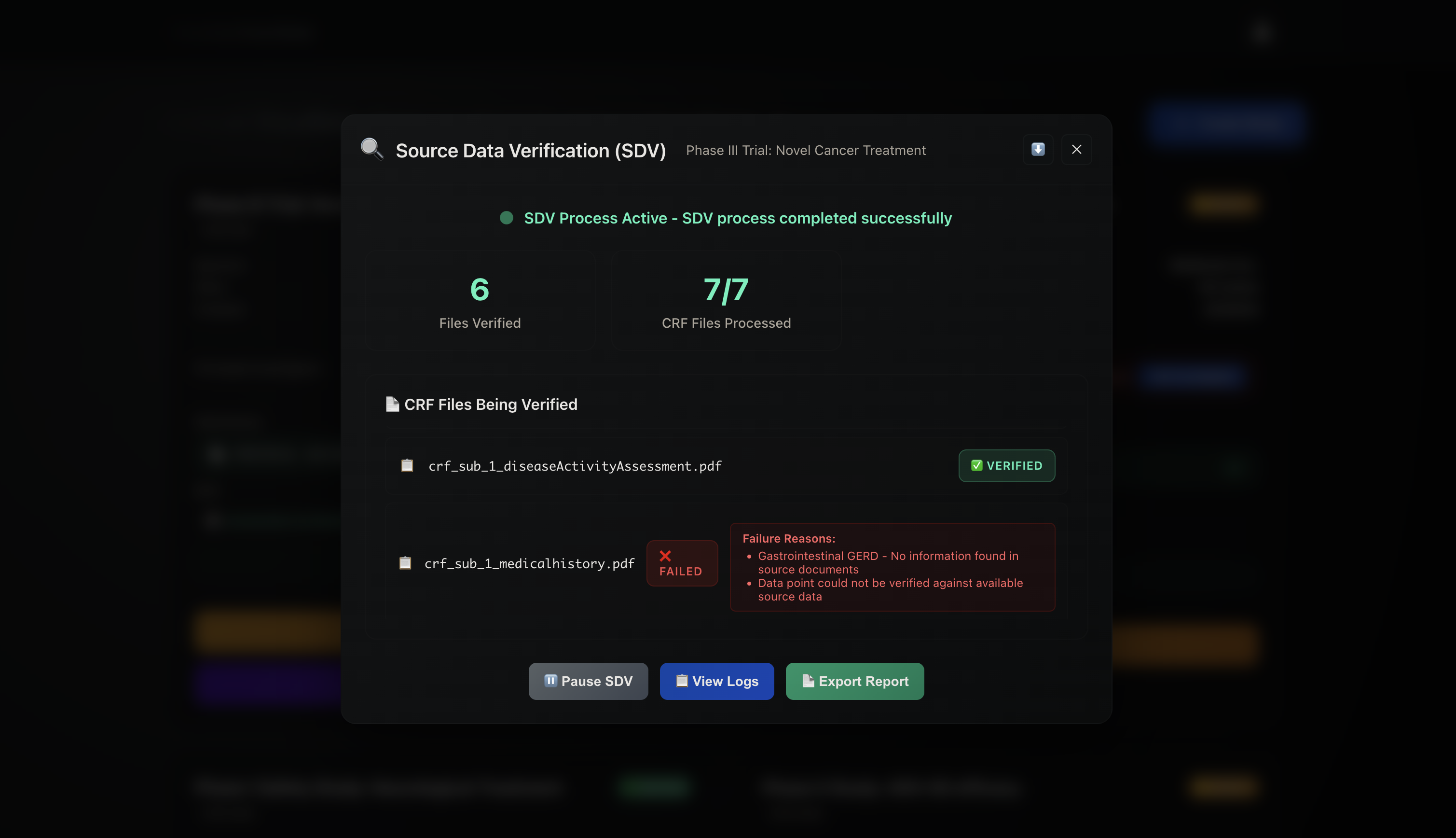
The platform also supports Source Data Verification (SDV) on demand — extracting relevant information from CRFs, eCRFs, or connected EHR/EDC systems, gaining access to source documents, and cross-referencing the two to verify accuracy.
When discrepancies are detected, it flags them for review and can take predefined corrective actions — providing faster, smarter, and more integrated clinical trial monitoring.
How we built it
I built the platform from the ground up as a full-stack web application designed to integrate seamlessly with existing clinical-trial systems.
The frontend was built with React.js, CSS, and JavaScript, giving it a modern UI and smooth transitions. The login and sign-up flow includes both standard authentication and SSO integrations with Google, Veeva Vault, and Medidata Rave (mocks), enabling secure, role-based access for sponsors and investigators.
The backend uses Flask (Python) for the API layer, with REST endpoints that manage user sessions, study creation, and file intake. Each uploaded or fetched file—protocols, eSource PDFs, and CRFs—is stored securely in a database (ChromaDB).
I integrated Fetch.ai agents and Gemini and Claude models to power the Protocol Analyzer. The analyzer parses trial protocols, identifies endpoints, study arms, inclusion/exclusion criteria, and the schedule of activities, then automatically generates a Monitoring Plan tailored to the study design. Along with this I built a monitor agent that is fluent in clinical trail processes, protocols, addressing schedule of events, and more.
Once attached to a study, the monitoring plan serves as a guide for autonomous AI agents. These agents connect to linked EDC or EHR systems through APIs, retrieve CRF and source data, and perform Source Data Verification when triggered. The verification engine uses a mix of document parsing, entity matching, and cross-referencing logic to detect inconsistencies between eCRFs and source data.
When discrepancies are found, the system flags them in real time and can trigger notifications or corrective actions, all recorded in an audit trail.
Challenges we ran into
One of the biggest challenges I faced was finding usable data. Real clinical trial data is highly protected for privacy and compliance reasons, and the public examples I found were incomplete, inconsistent, or missing key components like full protocols, CRFs, or source documents.
To move forward, I had to study what “complete” datasets look like in real trials — learning the structure and expectations for each type of document: protocols, CRFs, eCRFs, source data, and monitoring reports.
From there, I handcrafted realistic mock studies from scratch — writing detailed protocols, building CRF templates, and fabricating example source data that reflected how actual investigators document patient visits.
This process gave me a much deeper understanding of clinical data standards and what monitors actually look for, which shaped how I designed the platform’s data models, extraction logic, and AI validation pipeline.
Accomplishments that we're proud of
I built a fully functional AI agent capable of autonomously understanding clinical trial protocols, generating monitoring plans, and verifying study data against its sources.
I designed a complete workflow that connects directly to existing EDC platforms like Veeva Vault and Medidata Rave, eliminating the need to manually move data between systems — a real bottleneck in current clinical operations.
I also developed a Protocol Analyzer and Monitor agnet that interprets endpoints, inclusion criteria, and schedules of activities, translating them into actionable monitoring tasks for AI agents.
The system demonstrates how agentic AI can lead to a future where clinical trials are faster, more connected, and more efficient — cutting costs, reducing human error, and accelerating the delivery of life-saving treatments.
What we learned
I learned how complex and interconnected the clinical trial process really is — and how much of it depends on accurate, traceable data. Even small verification errors or delays can cost millions of dollars and slow down access to life-saving treatments.
Through building this project, I gained a deep understanding of how protocols, CRFs, and source data interact, and how crucial monitoring is for maintaining data integrity and patient safety.
Most importantly, I learned how AI and automation can help reduce this burden — not by replacing people, but by empowering researchers to focus on innovation, science, and patient outcomes instead of repetitive manual work.
What's next for MonitorMachine
I plan to build and fine-tune my own AI models trained specifically on clinical trial documents — including protocols, CRFs, monitoring plans, and site communications — to make the system smarter and more context-aware.
I want to make the platform bulletproof and production-ready, capable of handling real-world variability in data formats, terminologies, and regulatory requirements.
Future versions will focus on improving autonomous agent reliability, secure integrations with EHR/EDC APIs, and deeper alignment with CDISC and GCP standards.
The ultimate goal is to create a robust, trusted AI monitoring assistant that can operate safely in live trials — saving time, cutting costs, and pushing the boundaries of what’s possible in clinical research.



Log in or sign up for Devpost to join the conversation.