-
-

Logo
-
MCP Demo using a very simple agent
-
Architecture

🧠 Inspiration
In most Retrieval-Augmented Generation (RAG) systems, you have to obsess over chunking, prompt injection, and model orchestration just to get something semi-reliable. But I kept asking: What if the RAG pipeline wasn’t the foundation?
So I flipped it. Instead of starting with retrieval or modeling, I started with Agentic System Design—and built everything else around it, including RAG.
That led to the creation of Model Context Protocol (MCP)—a design pattern that lets you place an AI Agent at the heart of your system, and then integrate storage (like MongoDB), semantic search, and interfaces as composable layers. The result? You get flexibility, modularity, and reasoning depth—without hardwiring logic into every layer.
⚙️ What It Does
MongoDB RAG MCP Server is a fully working, production-grade demo that shows what happens when you build around an agent, not a pipeline.
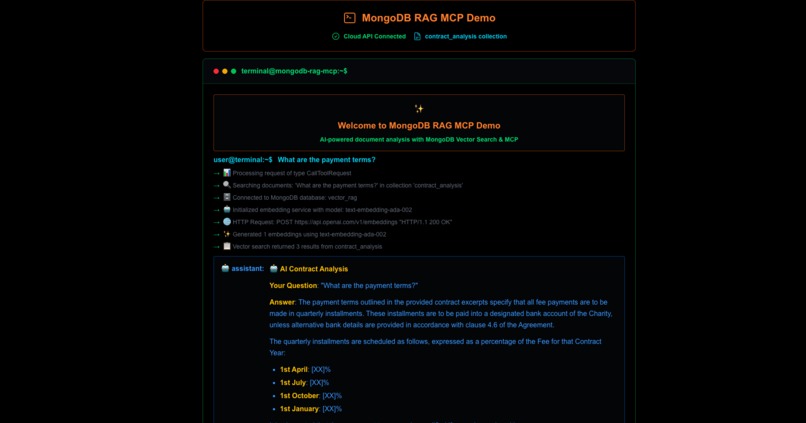
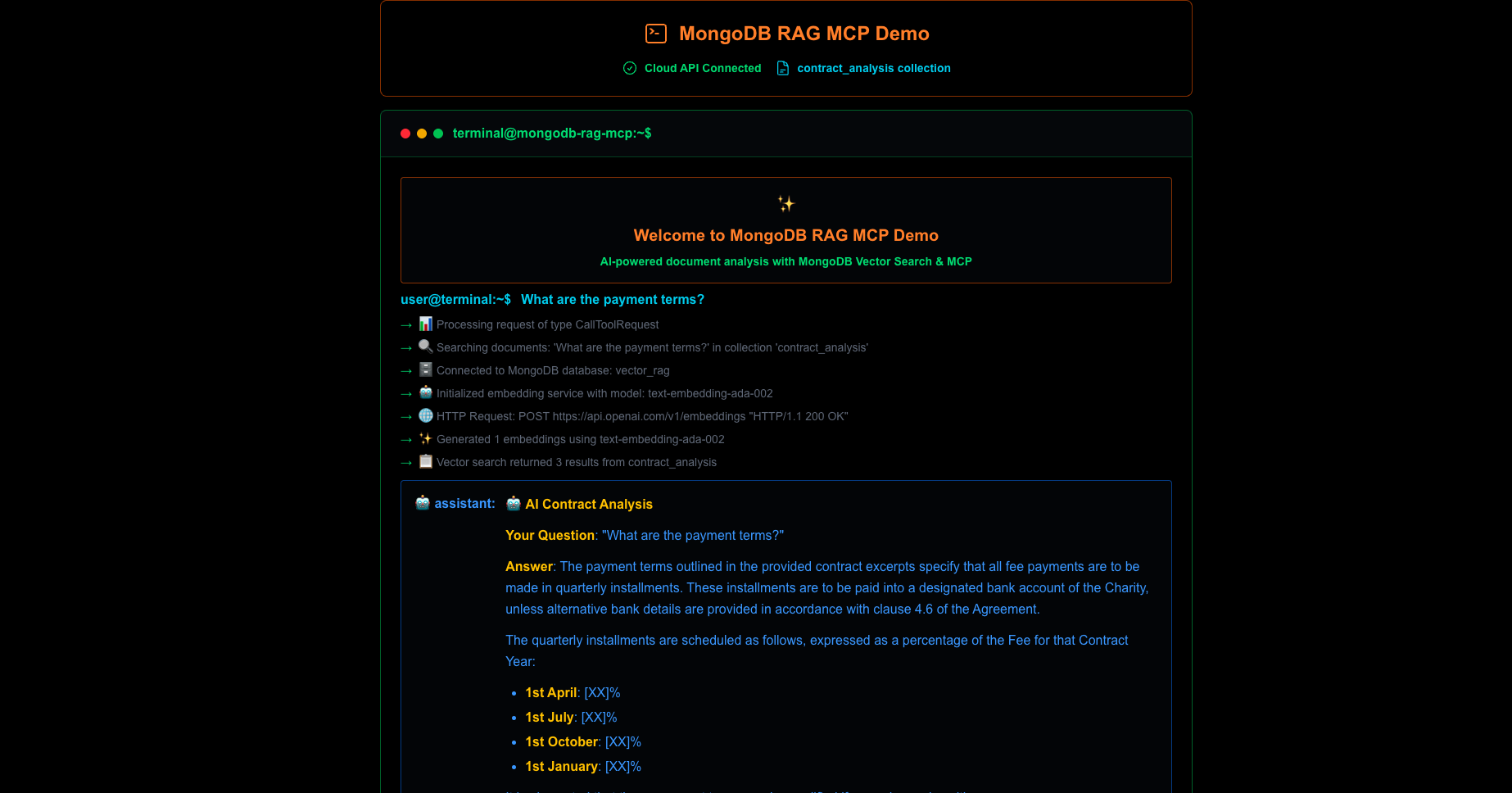
Users interact via a terminal-style web UI, asking things like “What are the payment terms?” The system uses MCP to:
- Interpret the user intent
- Retrieve semantically relevant chunks from MongoDB Atlas Vector Search
- Feed those chunks into GPT-4o-mini for context-aware generation
- Return the answer with traceable source attribution
It’s clean, modular, and doesn’t care if you’re analyzing legal docs or scientific papers. The agent adapts—because that’s what it’s designed to do.
🛠️ How I Built It
Core Innovations
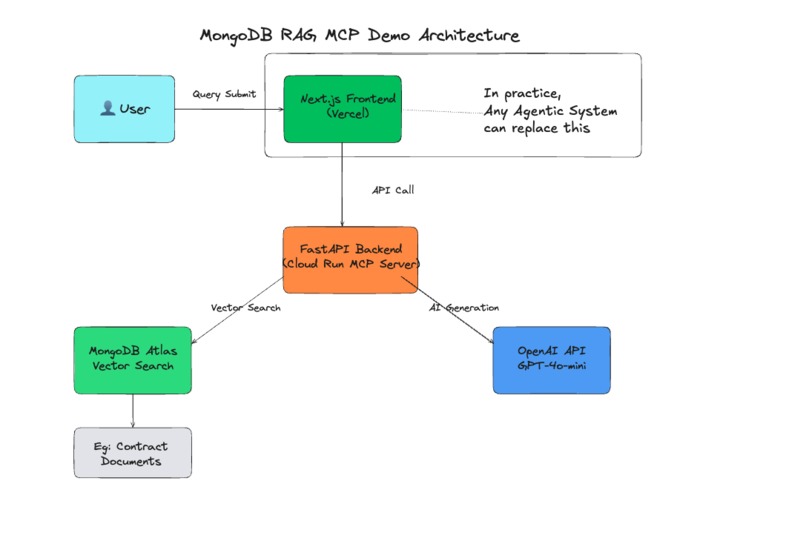
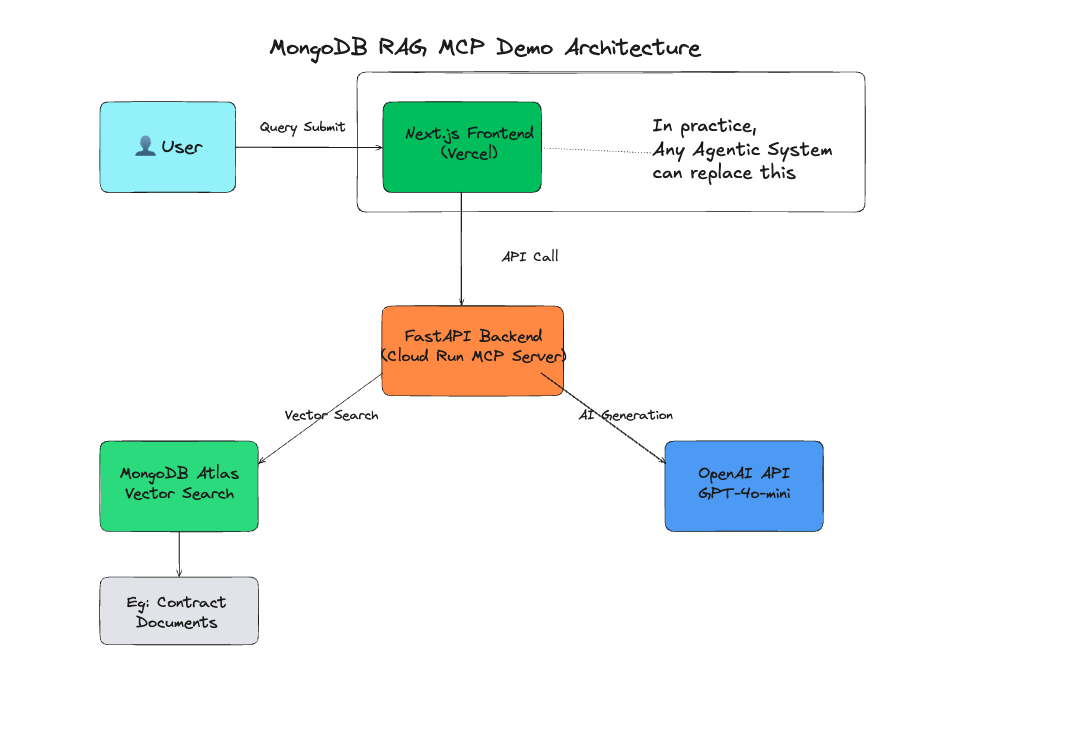
- Model Context Protocol (MCP): A standardized layer that coordinates between the user query, vector database, and LLMs. Acts as the reasoning OS.
- Agent-first Architecture: RAG lives inside the agent, not the other way around.
- MongoDB Atlas Vector Search: 666 legal document chunks embedded with OpenAI + cosine similarity
- GPT-4o-mini: Handles response synthesis with proper grounding
- FastAPI Backend: Hosted on Google Cloud Run (scalable, stateless)
- Next.js 15 Frontend: Terminal-style UI on Vercel
❗Challenges I Ran Into
- MCP-over-STDIO Was Painful: My first approach used subprocess pipes between frontend/backend. It broke under load and race conditions. So I switched to a clean REST-based MCP API with context envelopes.
- Docker Build Conflicts: PyTorch + FastAPI + OpenAI SDK caused dependency hell. Solved with strict dependency locking.
- Precision vs. Creativity: Balancing retrieval chunk size with GPT’s ability to generalize was a constant tuning problem.
✅ Accomplishments
- Built an agent-native RAG system that generalizes beyond legal use cases
- Deployed fully serverless: Google Cloud Run + MongoDB Atlas + Vercel
- Achieved sub-10s end-to-end inference latency
- Created an intuitive UI that demystifies legal analysis
- Demonstrated how MCP simplifies the architecture by eliminating hardcoded orchestration
📚 What I Learned
- You don’t need to make RAG the centerpiece—make the agent your foundation and let RAG serve it
- Learned how to tune MongoDB vector indexes and embedding models for max relevance
- Gained real-world ops experience with deploying AI pipelines to cloud-native infra
- Found that abstraction (via MCP) actually makes deployment easier, not harder
🚀 What’s Next for MCP
While the legal demo is a great showcase, MCP isn’t just for contracts—it’s a framework for intelligent, adaptable AI systems:
- Upload Pipeline: Let users embed their own docs
- Multi-Domain Support: Policy docs, medical research, startup handbooks
- Semantic Change Detection: Track meaning drift across document versions
- Role-based Access: Secure multi-user document querying
- Mobile-first UI: Fast AI access on the go
- Devtool Integration: GitLab or Notion plug-ins for agent-driven workflows


Log in or sign up for Devpost to join the conversation.