


Inspiration
Wenxi's mother works in this field at CapitalOne, and we thought that an open database containing this type of information would be beneficial to a wide audience, from small business owners to multi-national chains.
What it does
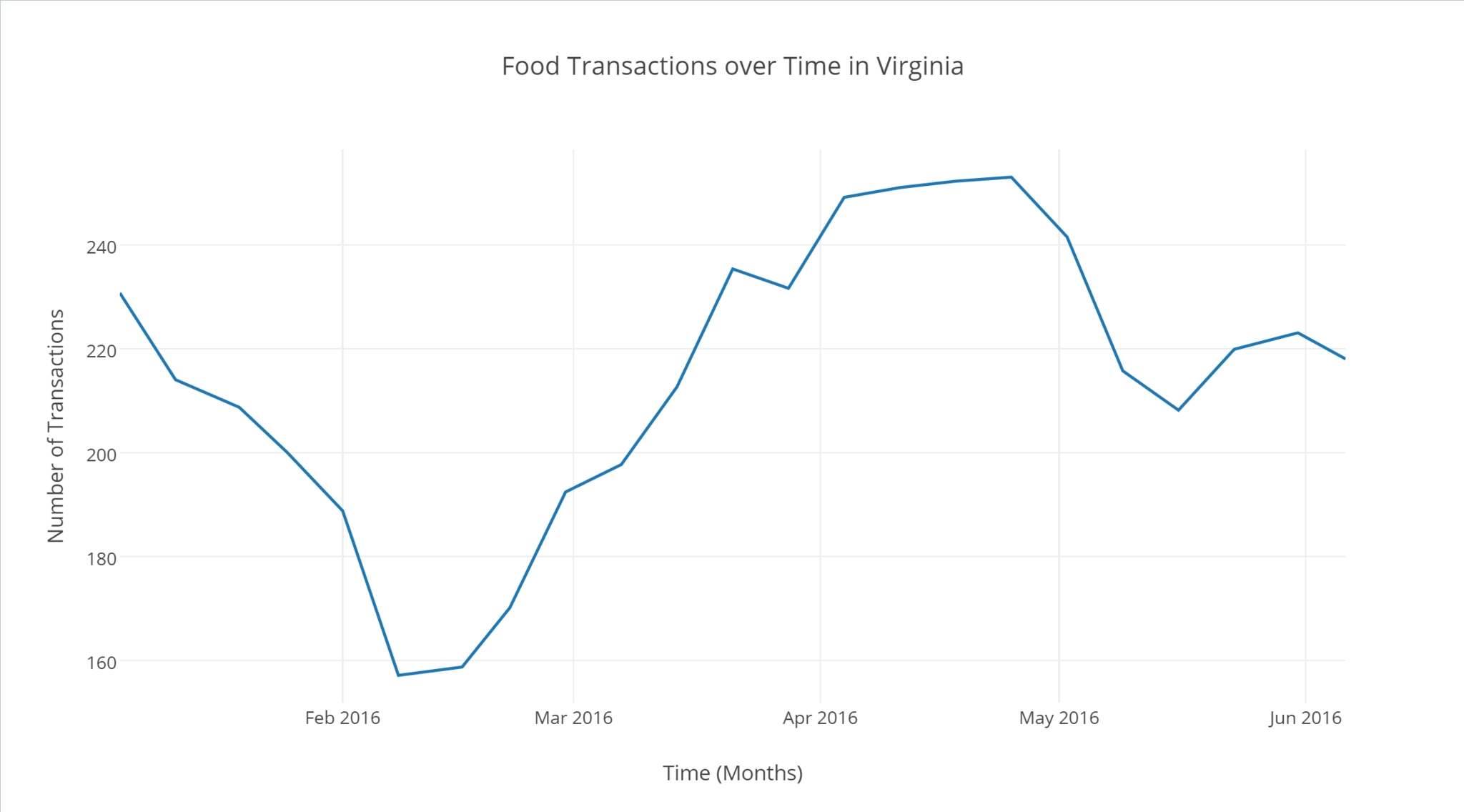
The system uses the CapitalOne API to collect transaction data. The transaction data contains information about the merchant with which the transaction was performed, the location of purchase, the amount of money transferred, the time of transaction, and the type of item bought/sold. A processing script use the BigParser API in conjunction with the CapitalOne API to filter and load the data into a Grid, taking advantage of its infinite size to fit massive quantities of transaction. A second processing script uses the BigParser's search API to perform analysis on the data, and convert it to a more readable, user-friendly form. The data is summarized, and statistically analyzed and graphed before being sent to the website, which would display these features in an interactive program called the "StatMap".
This website is only of concept, and therefore did not use real data, instead we generated masses of random data that fits the model. The data was also limited since the random generation presented limits that are not apparent in organic data. This rendered some features of our working models to be non-functional.
How we built it
We had to use the CapitalOne API to manually create a series of merchants, from which we could base our ~5000 randomly generated transactions off of. We used a Google Sheets and GoogleScripts to take the data from the CapitalOne API and populate a GoogleSheet. The BigParser API was then used to turn the sheet into a Grid. The Grid's built in sorting abilities were harnessed by the second processing script. The second script queries the Grid, and receives data in the form of JSON file. The file is converted to text through Python, allowing other subscripts to parse the text file easily, and perform analysis and display it. The script then display the information directly onto the StatMap, an interactive page that allows you to specify the data based on location or category. The graphing display is powered by the Plottly API. The non-graphable data would be displayed directly next to the graph in the form of data-tables.
Unfortunately not all of these features were integrated into the website due to time constraints.The resources and underlying structures are all present, but the actual implementation was incomplete. Instead there are non-functional place-holders on the website showing what they would actually be.
Challenges we ran into
One major problem we faced right away was the random generation of data. The data had to fit a specific model, and had to be generated with heavy limitations in order to be passable for this concept. We spent a few hours on this idea, and eventually we got help (Special thanks to Marwan from CapitalOne). Another problem we ran into right after was the moving of data from CapitalOne to the BigParser Grid, which was due to an incomplete documentation of the Beta. Eventually we got the transfer to work through a few hours of fiddling on GoogleScripts. The largest challenge we encountered was utilizing JSON files containing queried data from the Grid. We spent many hours trying to convert the JSON file into a filetype parseable by other scripts. After about 4 hours, we managed to resolve the issue with help(thanks again to Marwan).
Accomplishments that we're proud of
Data Generator was a program we are proud of, as well as the script that moves data between the APIs. We are also really proud of our JSON handling scripts, as they are very well functioning. We are also proud of UI as it is somewhat sleek and smooth, and hopefully easy to use.
What we learned
How to use python, the importance of assistance and teamwork, and building and setting a goal.
What's next for MoneyCat
We would definitely expand the abilities of MoneyCat to fit a larger variety of data. We would also flesh out all the proof-of-concepts that we were unable to complete. We would then try to acquire real-life transaction data to make our idea go from proof-of-concept to actual solution. We would definitely improve and expand on the graphing system, making it more interactive and informative, and same with the data tables
Built With
- bigparser
- capitalone
- googlescript
- html5
- javascript
- python


Log in or sign up for Devpost to join the conversation.