-
-
Landing page
-
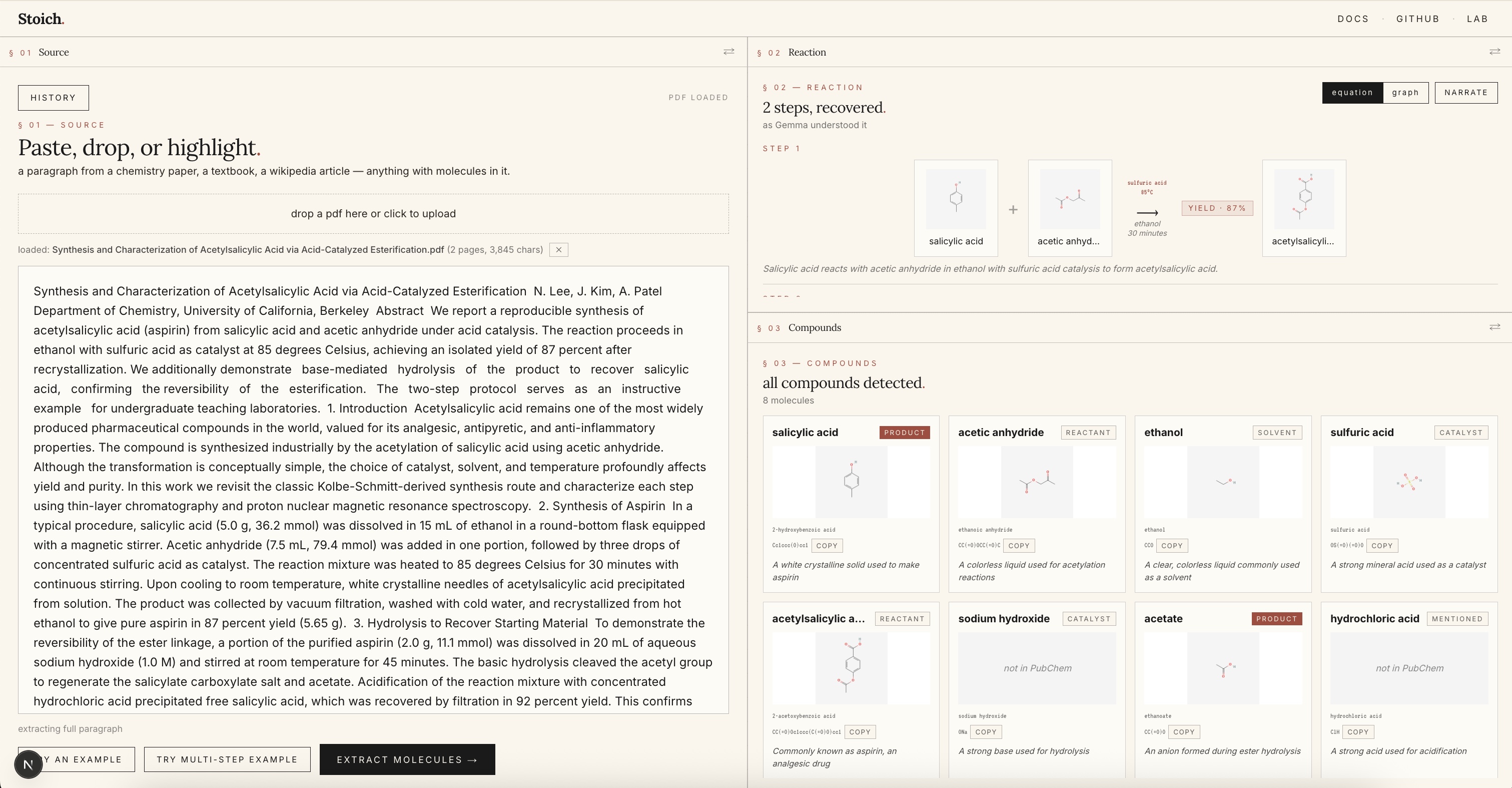
Uploaded Literature article -> all relevant compounds are extracted and multisynthesis reaction that article talks about is shown.
-
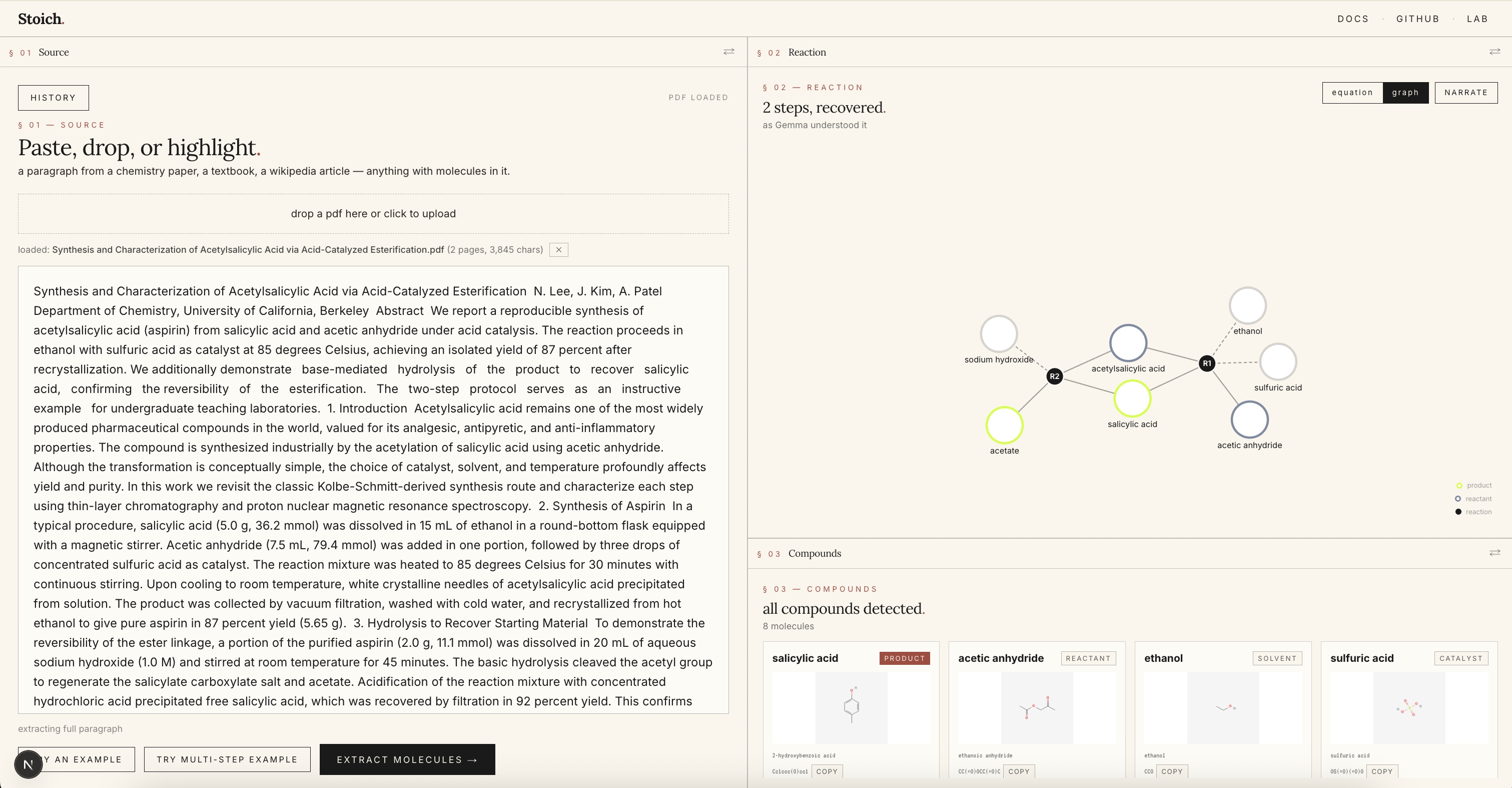
Graph visualization from reactions in literature article.
-
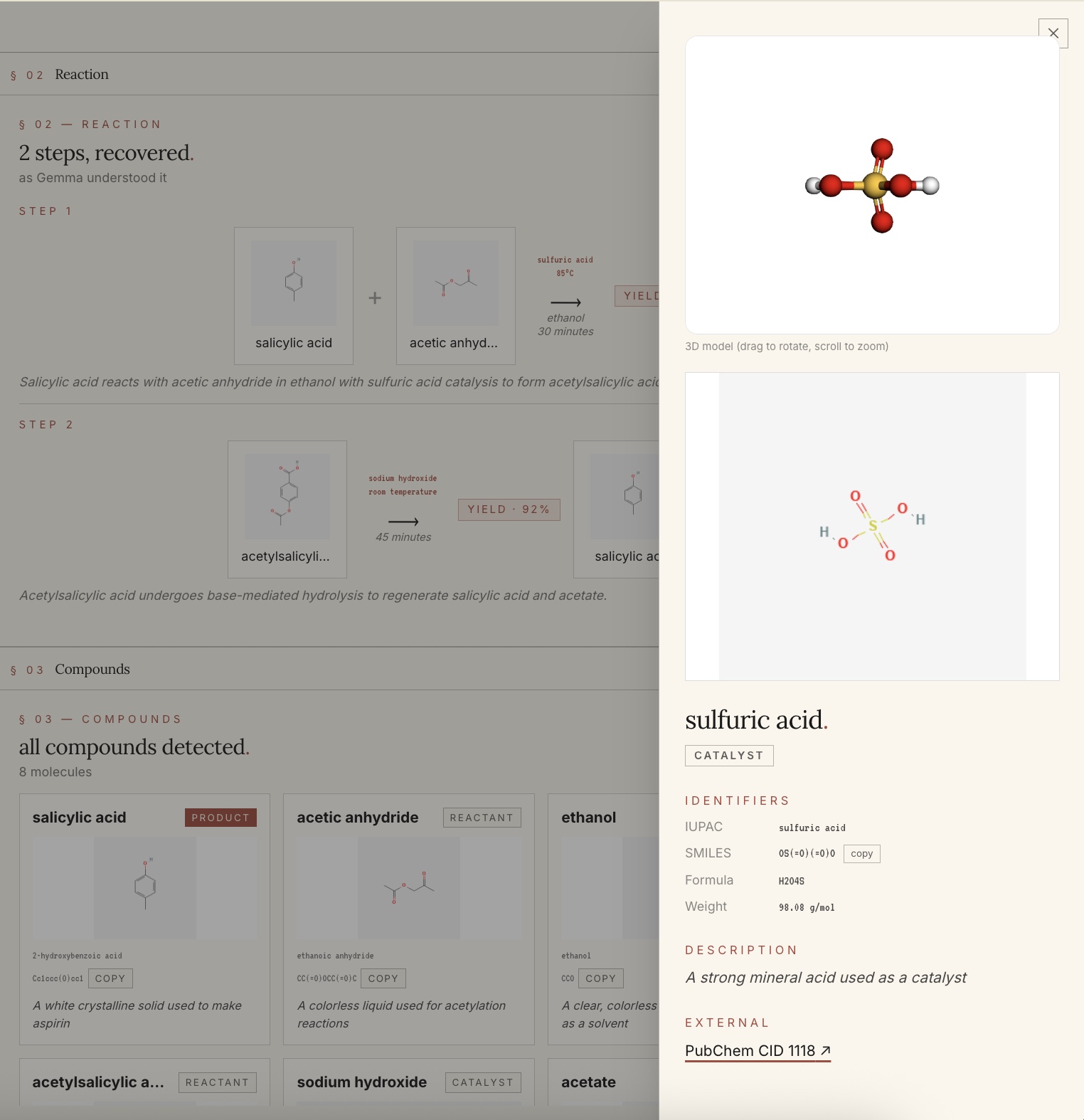
Compound details with 2D and 3D rendered diagrams.
-
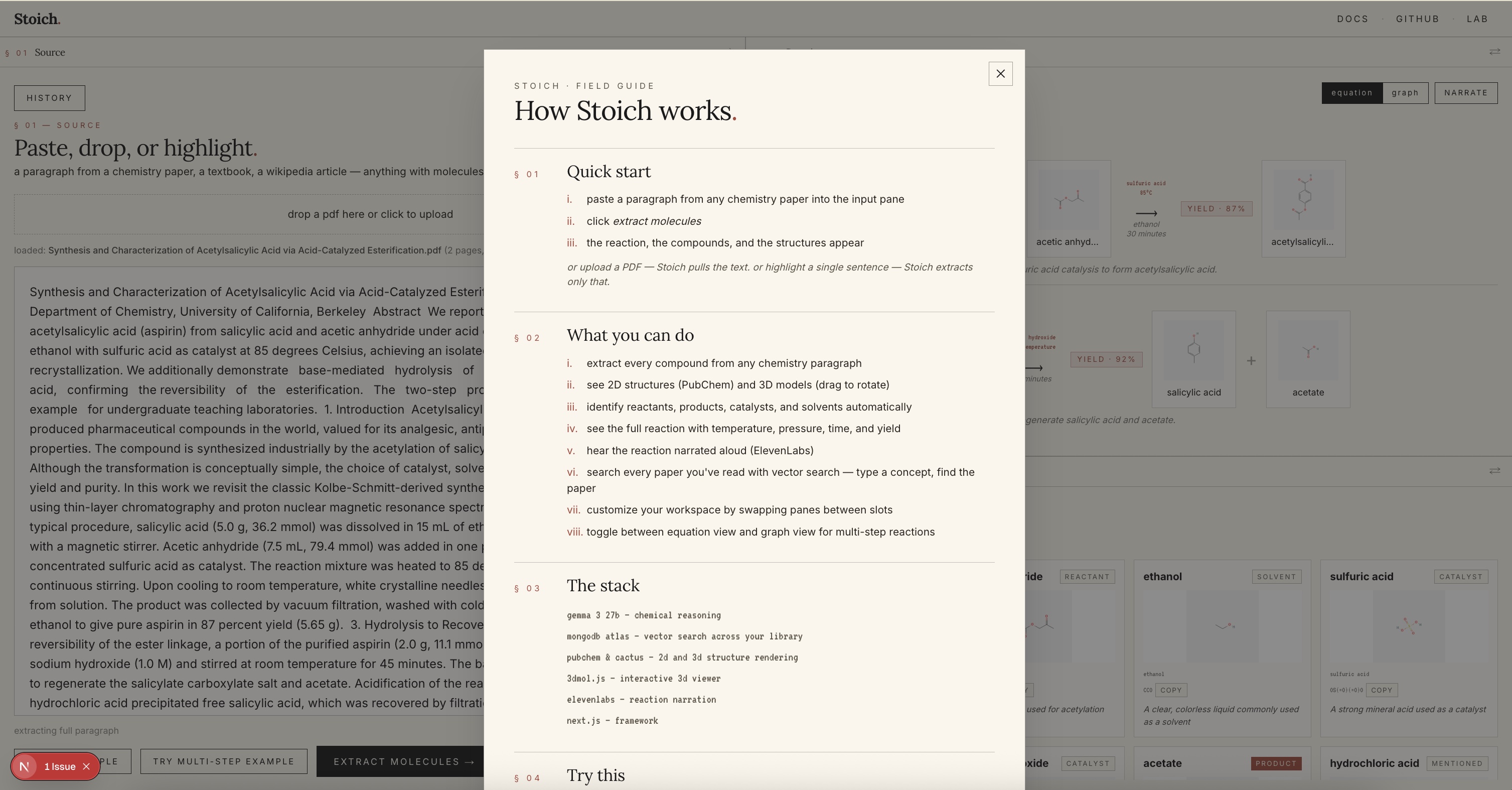
Docs Page
Inspiration
I took organic chemistry last semester at Berkeley and it nearly broke me. Not because the chemistry was unlearnable, but because every paper, every problem set, every textbook page required the same exhausting mental routine. Read a sentence. Stop. What is "acetic anhydride"? Open ChemDraw. Type the SMILES. Rotate it in my head. Try to remember which carbon was the electrophile. Lose my place. Start over.
I kept thinking: this isn't learning chemistry. This is doing OCR on a textbook with my own brain. Every chemist I know does this manual translation work on every paper, every time. The actual chemistry is the fun part. The part that takes three hours is just seeing the molecules in your head fast enough to follow the argument.
Stoich is the tool I wish I'd had in orgo. Paste a paragraph, see the molecules.
What it does
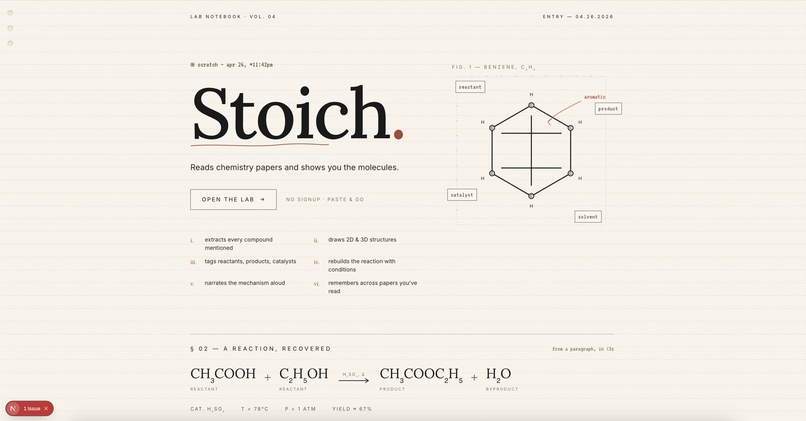
Stoich reads chemistry papers and shows you the molecules.
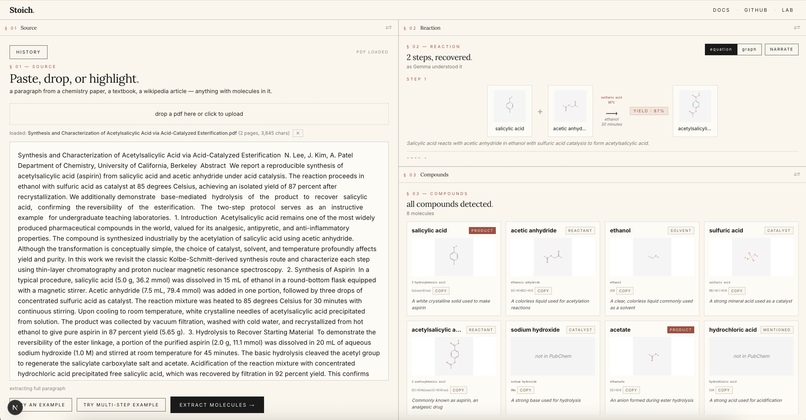
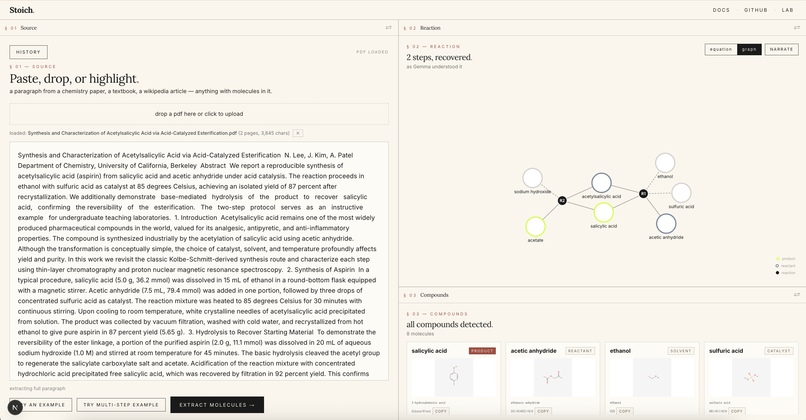
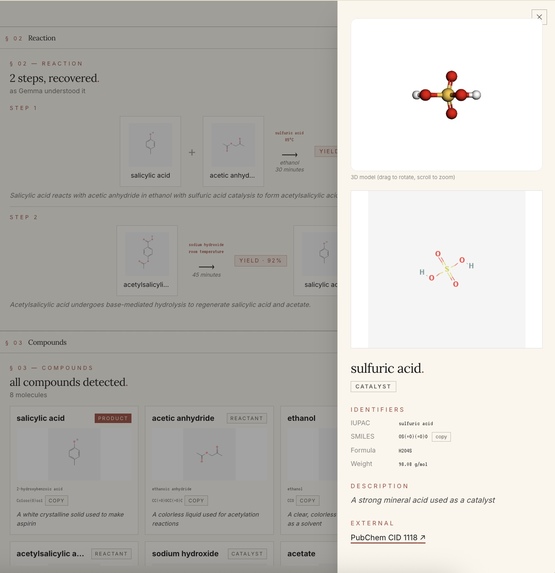
Paste a paragraph from a paper, upload a PDF, or highlight a single sentence. In about eight seconds, Stoich shows you every compound with its 2D structure (PubChem) and a rotatable 3D model (3Dmol.js + Cactus), classifies each as reactant, product, catalyst, or solvent, builds the full reaction equation with conditions and yield, and lets you search across every paper you've read with vector search. Type "painkiller" and find the aspirin paper from last week, even if those exact words never appeared in it.
Here's what Stoich extracts from a single sentence about aspirin synthesis:
$$ \text{Salicylic acid} + \text{Acetic anhydride} \xrightarrow[\text{EtOH, 85}^\circ\text{C}]{\text{H}_2\text{SO}_4} \text{Aspirin} + \text{Acetic acid} $$
Other features:
- Multi-step reactions render as stacked equations or a force-directed graph
- Each compound opens a detail drawer with formula, weight, IUPAC name, and a live 3D model
- ElevenLabs narrates any reaction aloud
- Customizable workspace — swap any pane to any slot
How I built it
Stoich is a Next.js 14 app with a multi-stage AI pipeline.
A chemistry paragraph enters via paste, PDF upload (parsed client-side with pdf.js), or highlight-to-extract. Google Gemma 3 27B receives the text and returns structured JSON: every compound with name, IUPAC name, SMILES, role, and a one-line description, plus reaction conditions and a multi-step decomposition if applicable.
For 2D rendering, I hit PubChem's REST API. For 3D, I chain Cactus (SMILES to SDF) into 3Dmol.js (SDF to interactive WebGL). Every extraction persists in MongoDB Atlas, and each compound's description is embedded with text-embedding-3-small and stored as a 1536-dimensional vector. A separate endpoint runs $vectorSearch on the compounds collection, which is what powers semantic search across past papers using cosine similarity \( \cos\theta = \frac{\mathbf{a} \cdot \mathbf{b}}{|\mathbf{a}||\mathbf{b}|} \).
Narration sends a generated script to ElevenLabs Turbo v2.5 and plays the returned audio in-browser.
Challenges I ran into
The hardest problem was getting Gemma to consistently return clean structured JSON and correctly identify the chemical role of each compound. Early prompts confused catalysts with reactants, mislabeled solvents, and occasionally hallucinated yield percentages. I fixed this with a strict JSON-only system prompt, explicit role definitions, and few-shot examples for the ambiguous cases.
The second hardest was rendering 3D structures fast enough to feel interactive. PubChem only returns 2D, so for 3D I needed atomic coordinates. I found that the NIH's Cactus service converts any SMILES to SDF on demand, and 3Dmol.js can render SDF directly. The full chain takes about three seconds, which is acceptable for "click a compound, see it spin."
The third was a self-inflicted wound. I tried to add a draggable VS Code-style panel system at hour 4, broke the entire app, and only realized after spending fifteen minutes on a useInsertionEffect error that the library had changed APIs in a major version. Reverting to a simpler swap-menu version was the right call. Lesson: scope creep at hour 4 is the most expensive scope creep.
What I learned
Open-weight models like Gemma 3 are good enough at structured extraction that a hackathon team can replace a workflow that previously required manual annotation by a chemistry student.
Vector search changes how you relate to your own reading. Once I'd searched my own past extractions semantically, keyword search felt primitive.
Visual identity matters more than features. I had every feature working two hours before submission and still spent the final stretch on typography, palette, and animation pacing. Those are what make people feel that the tool was built with care.
What's next
Today Stoich reads one paragraph and shows you the reaction. Tomorrow it reads the entire paper and shows you the synthesis tree, every reaction networked into the graph the chemist had in their head when they wrote it. Highlight a step. Click a compound. See where else in the literature it appears. Watch the molecule rotate while Gemma explains the mechanism with curved-arrow notation.
Beyond that: an "annotate together" mode for lab groups, integration with Zotero and PubMed, and fine-tuning Gemma on a chemistry-specific instruction dataset to push extraction accuracy past 99%.
Chemistry papers were written for humans who spent a decade learning to mentally compile them. I'm building the compiler.
Built for LA Hacks 2026
Built With
- 3dmol.js
- cactus
- elevenlabs
- gemma
- google-ai-studio
- mongodb
- mongodb-atlas
- next.js
- node.js
- openai
- pdf.js
- pubchem
- python
- react
- tailwindcss
- typescript
- vector-search
- vercel



Log in or sign up for Devpost to join the conversation.