



Inspiration
Storing and managing data had never been easy and with the flourish of AI, and deep learning we have generated paramount data called Big Data. Because unstructured data is made up of files like audio, video, pictures and even social media data, it's easy to see why volume is a challenge. The value of the data can get lost in the shuffle when working with so much of it. There is value to be found in unstructured data, but harnessing that information can be difficult. When there is so much data in S3 it becomes very difficult for organizations to handle document files in lesser time.
What it does
This project aims to solve data visibility problems for S3 storage solutions. Imagine you run a large Biopharmaceutical manufacturing unit, which is a highly regulated industry where deviation documents are used to optimize manufacturing processes. Deviation documents in biopharmaceutical manufacturing processes are geographically diverse, spanning multiple countries and languages. Therefore, to reduce downtime and increase process efficiency, it is critical to automate the ingestion and understanding of deviation documents. For this workflow, a large biopharma customer needed to translate and classify documents at their manufacturing site.
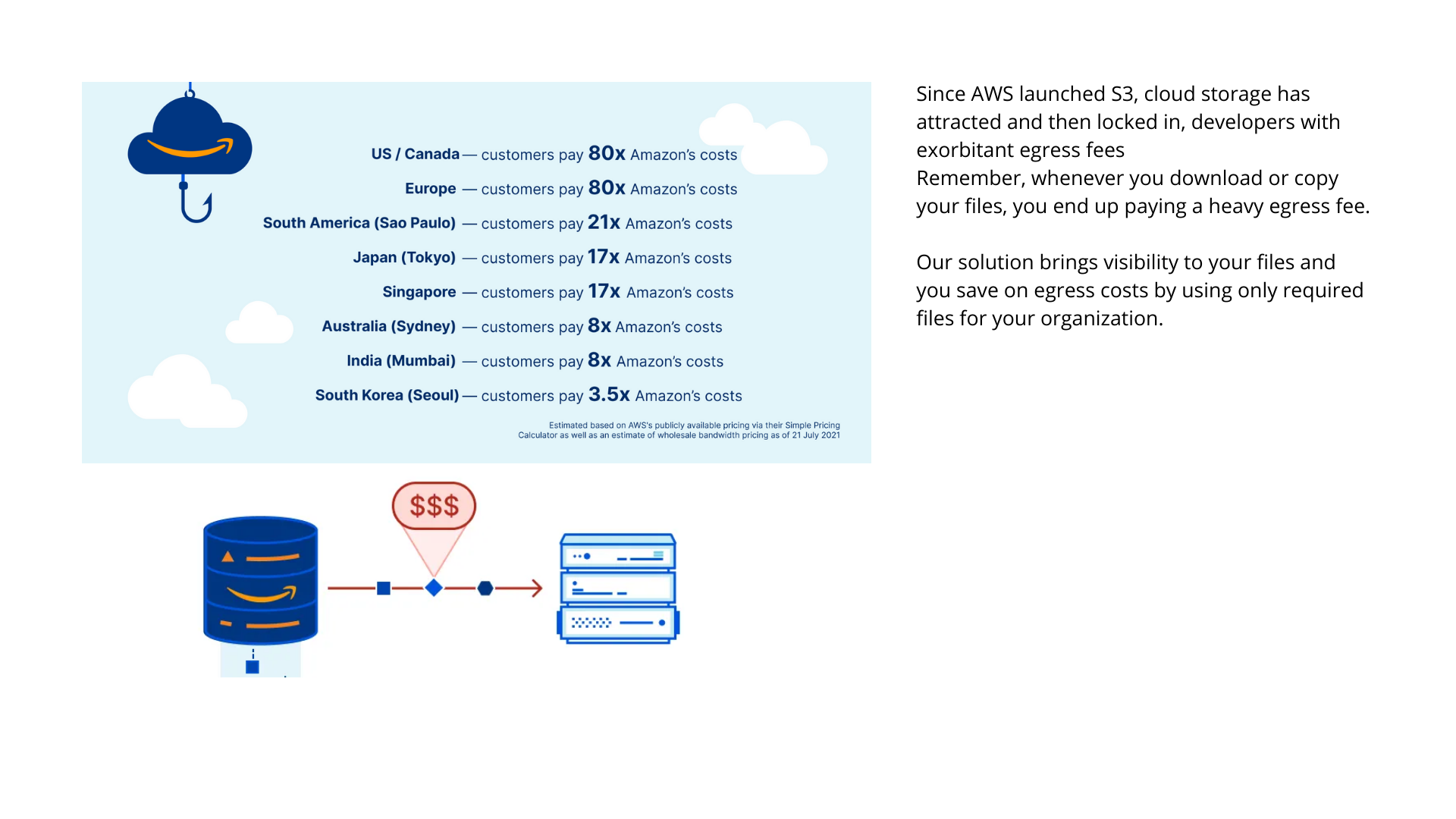
Data Visibility is also one of the most debated topics among cloud storage users. A lack of visibility in the public cloud is a business risk in terms of security, compliance and governance, but it can also affect business costs. For example, companies may be unaware that they're paying for idle virtual machines unnecessarily. Then there's performance. Almost half of those that responded to Ixia's survey stated that a lack of visibility has led to application performance issues. These blind spots hide clues key to identifying the root cause of a performance issue, and can also lead to inaccurate fixes. Now we're getting so much more data thrown at us, visibility is even more of a challenge - just trying to work out what's important through all of the noise. With a lack of visibility, some businesses may not be aware that they have customer information in the public cloud, which is a problem when "the local regulations and laws state it should not be stored outside of a company's domain.
Current market solutions for S3(Object Storage) visibility problem
Vendors are beginning to listen to the concerns of customers. Vendors have started to make more APIs available and several third-party vendors are also creating software that can run inside virtualised environments to feedback more information to customers.
On testing the power and simplicity of Modzy AI APIs, it can be a better alternative to your expensive Cloud Service Vendors who charge exorbitantly for their APIs.
How we built it
The app was built using python, Cortx S3 APIs, and streamlit. The app scans the S3 bucket for files with extensions .pdf and .txt (I chose this since most of the documents and text files are in this format). After scanning if the .pdf file is found it is converted to Images and OCR API converts from Images to texts and runs Modzy APIs to generate a content summary for all files inside the S3 bucket.
The first step is to set up Cortx Data Storage on VMWare:
- Follow this instruction to setup OVA on VMWare https://github.com/Seagate/cortx/blob/main/doc/ova/2.0.0/PI-6/CORTX_on_Open_Virtual_Appliance_PI-6.rst
- Load the OVA on VMWare https://github.com/Seagate/cortx/blob/main/doc/Importing_OVA_File.rst
- Set up S3 operations from the instructions https://github.com/Seagate/cortx/blob/main/doc/ova/2.0.0/PI-6/S3_IO_Operations.md
- If you are successful, you should be able to test aws commands on VMware and check your IP address which will be used as the Endpoint URL.
# hostname -I
# aws s3 cli

Your endpoint URL for S3 APIs is http://YOURIP:31949 Test it with awscli from other systems.

Next make a free account on the Modzy AI platform, https://app.modzy.com/ Make a new project and add get your API keys

Once you have the API keys, install the requirements and run the streamlit python script in the Github repository.
Challenges we ran into
Modzy was really simple. The accuracy of Modzy prebuilt models was not very much so the overall statistics on the apps could not give much insight (each sentence and paragraph were of differing sizes, the model worked fairly to find a good summary of overall content, should have capabilities to recognise data, time, the money involved in document through Named Entity Recognition API, there is the option to add custom model to fix such industry-specific use cases).
Accomplishments that we're proud of
The app is fully functional, just enter Cortx S3 credentials and the model would be ready to scan through all objects in the buckets and produce a statistical summary giving you an idea of how to improve cloud space management and faster file lookup time for any organization.
What we learned
Got to learn many new concepts of Modzy APIs, and data storage problems.
What's next for Modzy AI S3 Filesystem Scanner
In future would like to bring the characteristics to find (heavily based on the occupied size, content type, and entities involved) a richer summary of the data, like in scenarios:
- AI model to recommend to the user how much space could be saved on data compresses, i.e., what will be the compression ratio if we compress bytes of data (from point 1 above) with compression scheme X, a simple trigger would be a smart move to help the end-user save on space
- Add elastic search for generated Content Topics, entities, summaries, and translation for quicker access to data without incurring an S3 egress fee for most private Cloud Companies (saving lots of money for the organization)
Built With
- botoaws
- cortx
- modzy
- python
- s3
- streamlit


Log in or sign up for Devpost to join the conversation.